
贝叶斯深度学习:一个统一深度学习和概率图模型的框架

人工智能(AI)的进展显示,通过构建多层的深度网络,利用大量数据进行学习,可以获得性能的显著提升。但这些进展基本上是发生在感知任务中,对于认知任务,需要扩展传统的AI范式。
4月9日,罗格斯大学计算机科学系助理教授王灏,在AI TIME青年科学家——AI 2000学者专场论坛上,分享了一种基于贝叶斯的概率框架,能够统一深度学习和概率图模型,以及统一AI感知和推理任务。
据介绍,框架有两个模块:深度模块,用概率型的深度模型表示;图模块,即概率图模型。深度模块处理高维信号,图模块处理偏推断的任务。
以下是演讲全文,AI科技评论做了不改变原意的整理:
今天和大家分享关于贝叶斯深度学习的工作,主题是我们一直研究的概率框架,希望用它统一深度学习和概率图模型,以及统一AI感知和推理任务。
众所周知,深度学习加持下的AI技术已经拥有了一定的视觉能力,能够识别物体;阅读能力,能够文本理解;听觉能力,能够语音识别。但还欠缺一些思考能力。
“思考”对应推理推断任务,具体指它能够处理复杂的关系,包括条件概率关系或者因果关系。
深度学习适合处理感知任务,但“思考”涉及到高层次的智能,例如决策数据分析、逻辑推理。概率图由于能非常自然的表示变量之间的复杂关系,所以处理推理任务具有优势。

如上图,概览图示例。任务是:想通过目前草地上喷头开或关,以及外面的天气来推断外面的草地被打湿的概率是多少,也可以通过草地被打湿反推天气如何。概率图的缺点是无法高效处理高维数据。

总结一下,深度学习比较擅长感知类的任务,不擅长推理、推断任务,概率图模型擅长推理任务,但不擅长感知任务。
很不幸,现实生活中这两类任务一般是同时出现、相互交互。因此,我们希望能够把深度学习的概率图统一成单一的框架,希望达到两全其美。

我们提出的框架是贝叶斯深度学习。有两个模块:深度模块,用概率型的深度模型表示;图模块,即概率图模型。深度模块处理高维信号,图模块处理偏推断的任务。
值得一提的是,图模块本质是概率型的模型,因此为了保证能够融合,需要深度模型也是概率型。模型的训练可以用经典算法,例如MAP、MCMC、VI。

给具体的例子,在医疗诊断领域,深度模块可以想象成是医生在看病人的医疗图像,图模块就是医生根据图像,在大脑中判断、推理病症。从医生的角度, 医疗图像中的生理信号是推理的基础,优秀的能力能够加深他对医疗图像的理解。

引申一下,电影推荐系统里,可以把深度模块想象成是对电影的视频情节、演员等内容的理解,而图模块需要对用户喜好、电影偏爱之间的相似性进行建模。进一步,视频内容理解和“喜好”建模也是相辅相成的。

具体到模型细节,我们将概率图模型的变量分为三类:深度变量,属于深度模块,假设产生于比较简单的概率分布;图变量,属于图模块,和深度模块没有直接相连,假设它来自于相对比较复杂的分布;枢纽变量,属于深度模块和图模块中相互联系的部分。
下面介绍该框架是如何在实际应用中效果。
推荐系统
推荐系统基本假设是:已知用户对某些电影的喜好,然后希望预测用户对其他电影的喜好。

可以将用户对电影的喜爱写成评分矩阵(Rating Matrix),该矩阵非常稀疏,用来直接建模,得到的准确性非常低。在推荐系统中,我们会依赖更多的信息,例如电影情节、电影的导演、演员信息进行辅助建模。
为了对内容信息进行建模,并进行有效提纯,有三种方式可供选择:手动建立特征,深度学习全自动建立特征、采用深度学习自适应建立特征。显然,自适应的方式能够达到最好的效果。
不幸的是,深度学习固有的独立同分布假设,对于推荐系统是致命的。因为假设用户和用户之间没有任何的关联的,显然是错误的。
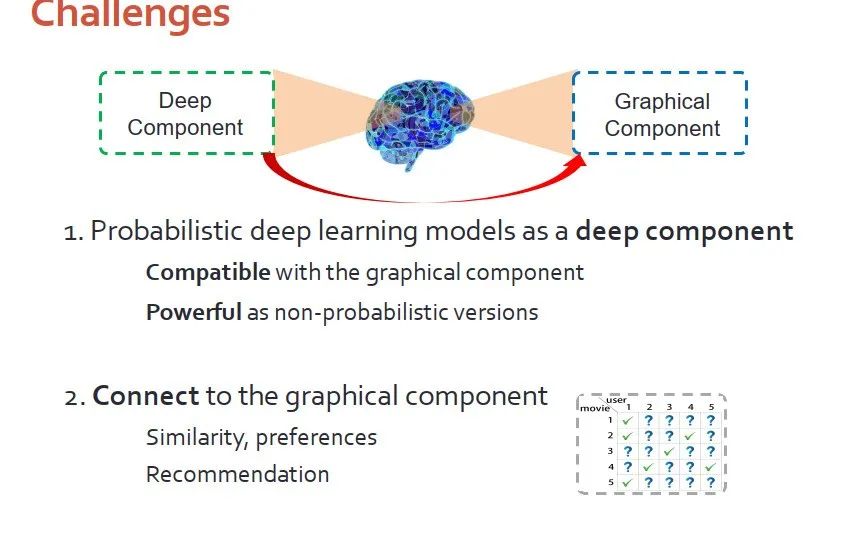
为了解决上述困难,我们推出协同深度学习,能够将“独立”推广到“非独立”。该模型有两个挑战:
1.如何找到有效的概率型的深度模型作为深度模块。希望该模型能够和图模块兼容,且和非概率型模块的效果相同。
2.如何把深度模块连接到主模块里,从而进行有效建模。

来看第一个挑战。自编码器是很简单的深度学习模型,一般会被用在非监督的情况下提取特征,中间层的输出会被作为文本的表示。值得一提的是,中间层的表示它是确定性的,它不是概率型的,和图模块不兼容,无法工作。
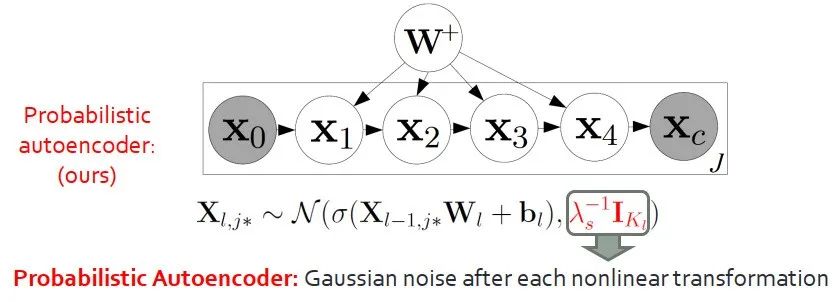
我们提出概率型的自编码器,区别在于将输出由“确定的向量”变换成“高斯分布”。概率型的自编码器可以退化成标准自编码器,因此后者是前者的一个特例。

如何将深度模块与图模块相联系?先从高斯分布中提出物品j的隐向量:

然后从高斯分布中,提取出用户i的隐向量:

基于这两个隐向量们就可以从另外高斯分布采样出用户i对物品j的分布,高斯分布的均值是两个隐向量的内积。
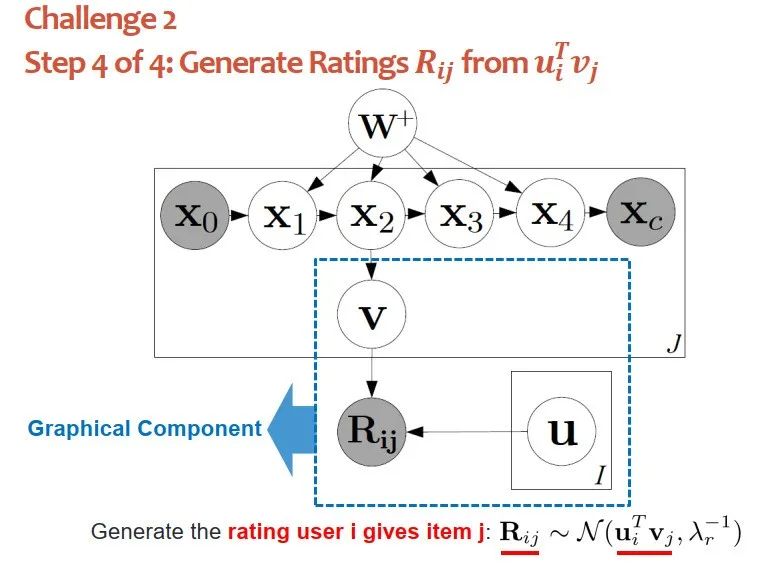
上图蓝框表示图模块。定义了物品、用户、评分等等之间的条件概率关系。一旦有了条件概率关系,就能通过评分反推用户、物品的隐向量,可以根据“内积”预测未知的背景。

上图是整个模型的图解,其中λ是控制高斯分布方差的超参数。为了评测模型效果,我们用了三个数据集:citeulike-a、citeulike-t、Netflix。对于citeulike是用了每篇论文的标题和摘要,Netflix是用电影情节介绍作为内容信息。

实验结果如下图所示,Recall@M指标表示,我们的方法大幅度超越基准模型。在评分矩阵更加稀疏的时候,我们模型性能提高幅度甚至可以更大。原因在于,矩阵越稀疏,模型会更加依赖内容信息,以及从内容提取出来的表示。

推荐系统性能提升能够提升企业利润,根据麦肯锡咨询公司的调查,亚马逊公司中35%的营业额是由推荐系统带来的。这意味着推荐系统每提升1%个点,都会有6.2亿美金的营业额提升。

小结一下,到目前为止,我们提出了概率型的深度模型作为贝叶斯深度学习框架的深度模块,非概率型的深度模型其实是概率型深度模型的特例。针对深度的推荐系统提出层级贝叶斯模型,实验表明该系统可以大幅度推荐系统的效率。
其他应用设计
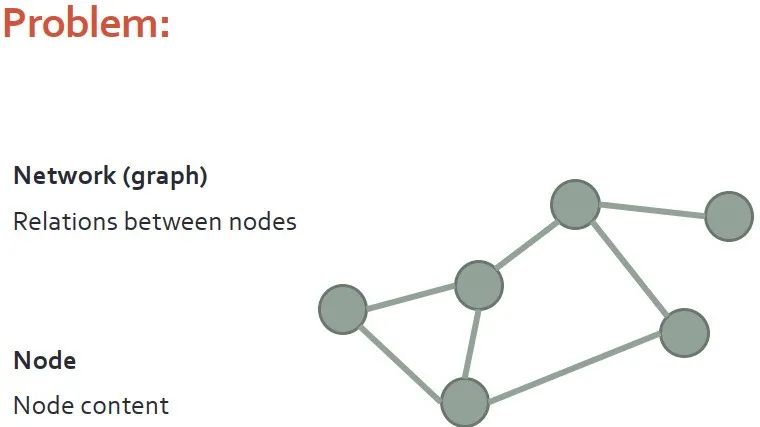
给定一个图,我们知道边,并了解节点的内容。此图如果是社交网络,其实就是表示着用户之间的朋友关系,节点内容就是用户贴在社交平台上的图片或者文本。这种图关系,也可以表示论文的标题、摘要、引用等等联系。
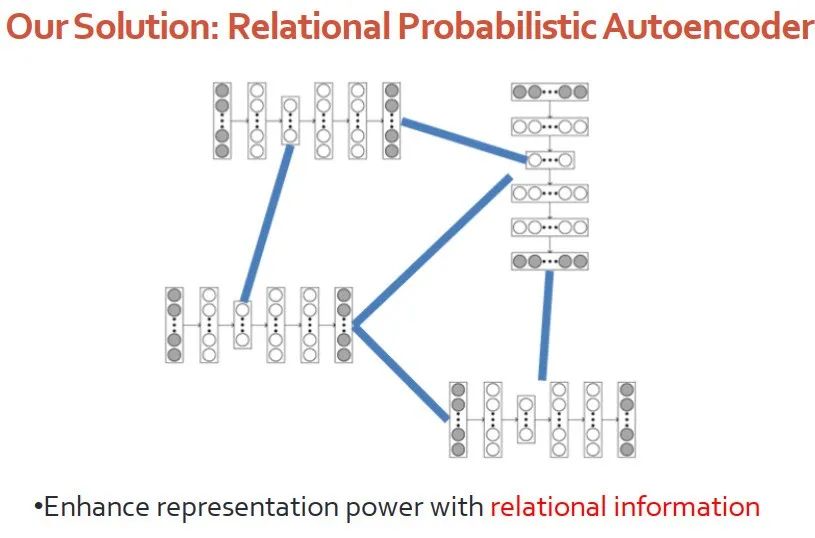
我们的任务是希望模型能够学习到节点的表达,即能够捕获内容信息,又能够捕获图的信息。
解决方案是基于贝叶斯深度学习框架,设计关系型的概率自编码器。深度模块专门负责处理每个节点的内容,毕竟深度学习能够在处理高维信息是有优势的;图模块处理节点节点之间的关系,例如引用网络以及知识图谱复杂的关系。

在医疗领域,我们关注医疗监测。任务场景是:家里有小型雷达,会发射信号,设计的模型希望能够根据从病人身上反射的信号,发现病人是否按时用药、用药的次序是否正确。问题在于:用药的步骤非常复杂,需要理清顺序。
基于贝叶斯深度学习概率框架方法,用深度模块处理非常高维的信号信息,用图模块对在医疗专有知识进行建模。
值得一提的是,即使对于不同应用的同一模型,里面的参数具有不同的学学习方式,例如可以用MAP、贝叶斯方法直接学习参数分布。
对于深度的神经网络来说,一旦有了参数分布,可以做很多事情,例如可以对预测进行不确定性的估计。另外,如果能够拿到参数分布,即使数据不足,也能获得非常鲁棒的预测。同时,模型也会更加强大,毕竟贝叶斯模型等价于无数个模型的采样。
下面给出轻量级的贝叶斯的学习方法,可以用在任何的深度学习的模型或者任何的深度神经网络上面。

首先明确目标:方法足够高效,可通过后向传播进行学习,并“抛弃”采样过程,同时模型能够符合直觉。
我们的关键思路是:把神经网络的神经元以及参数,看成分布,而不是简单的在高维空间的点或者是向量。允许神经网络在学习的过程中进行前向传播、后向传播。因为分布是用自然参数表示,该方法命名为NPN(natural-parameter networks)。
#参考文献:
??A survey on Bayesian deep learning. Hao Wang, Dit-Yan Yeung. ACM Computing Surveys (CSUR), 2020.? Towards Bayesian deep learning: a framework and some existing methods. Hao Wang, Dit-Yan Yeung. IEEE Transactions on Knowledge and DataEngineering (TKDE), 2016.
? Collaborative deep learning for recommender systems. Hao Wang, Naiyan Wang, Dit-Yan Yeung. Twenty-First ACM SIGKDD Conference on
Knowledge Discovery and Data Mining (KDD), 2015.
? Collaborative recurrent autoencoder: recommend while learning to fill in the blanks. Hao Wang, Xingjian Shi, Dit-Yan Yeung. Thirtieth Annual
Conference on Neural Information Processing Systems (NIPS), 2016.:
? Natural parameter networks: a class of probabilistic neural networks. Hao Wang, Xingjian Shi, Dit-Yan Yeung. Thirtieth Annual Conference on
Neural Information Processing Systems (NIPS), 2016.
? Relational stacked denoising autoencoder for tag recommendation. Hao Wang, Xingjian Shi, Dit-Yan Yeung. Twenty-Ninth AAAI Conference on?Artificial Intelligence (AAAI), 2015.
? Relational deep learning: A deep latent variable model for link prediction.
Hao Wang, Xingjian Shi, Dit-Yan Yeung. Thirty-First AAAI Conference on Artificial Intelligence (AAAI), 2017.
? Bidirectional inference networks: A class of deep Bayesian networks for health profiling.
Hao Wang, Chengzhi Mao, Hao He, Mingmin Zhao, Tommi S. Jaakkola, Dina Katabi. Thirty-Third AAAI Conference on Artificial Intelligence (AAAI),
2019.
? Deep learning for precipitation nowcasting: A benchmark and a new model. Xingjian Shi, Zhihan Gao, Leonard Lausen, Hao Wang, Dit-Yan Yeung,
Wai-kin Wong, and Wang-chun Woo. Thirty-First Annual Conference on Neural Information Processing Systems (NIPS), 2017.
? Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung,
Wai-kin Wong, Wang-chun Woo. Twenty-Ninth Annual Conference on Neural Information Processing Systems (NIPS), 2015.
? Continuously indexed domain adaptation. Hao Wang*, Hao He*, Dina Katabi. Thirty-Seventh International Conference on Machine Learning (ICML),
2020.
? Deep graph random process for relational-thinking-based speech recognition. Hengguan Huang, Fuzhao Xue, Hao Wang, Ye Wang. Thirty-
Seventh International Conference on Machine Learning (ICML), 2020.
? STRODE: Stochastic boundary ordinary differential equation. Hengguan Huang, Hongfu Liu, Hao Wang, Chang Xiao, Ye Wang. Thirty-Eighth
International Conference on Machine Learning (ICML), 2021.
? Delving into deep imbalanced regression. Yuzhe Yang, Kaiwen Zha, Yingcong Chen, Hao Wang, Dina Katabi. Thirty-Eighth International Conference
on Machine Learning (ICML), 2021.
? Adversarial attacks are reversible with natural supervision. Chengzhi Mao, Mia Chiquier, Hao Wang, Junfeng Yang, Carl Vondrick. International
Conference on Computer Vision (ICCV), 2021.
? Assessment of medication self-administration using artificial intelligence. Mingmin Zhao*, Kreshnik Hoti*, Hao Wang, Aniruddh, Raghu, Dina
Katabi. Nature Medicine, 2021.
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
??如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675