来自复旦大学、字节跳动人工智能实验室等机构的研究者提出E-KAR 数据集,这是首个可解释的知识密集型类比推理数据集,相关工作已经被 ACL 2022 Findings 接收。
类比在人类认知中占有重要地位,通过类比可以发现新的见解和证明日常的推理,比如老师在课堂上用煮熟的鸡蛋类比地球的构造,使得学生很快理解了不能亲自体验的知识。由于在多个领域有着独特价值,类比成为了人工智能研究领域的重要问题。在 NLP 中,我们比较熟悉的是以多选题形式出现的词类比识别问题,然而现有的词类比数据集关注简单的二元类比关系,并且缺乏用于届时类比推理过程的标注信息。因此,解答这一类问题并不能揭示神经网络模型类比推理的内在过程,这对探究类比的内部性质来说是不利的[6]。我们亟需一类更困难的、可解释的类比推理数据集。本文介绍来自复旦大学、字节跳动人工智能实验室等机构研究者的最新工作 E-KAR,相关工作已经被 ACL 2022 Findings 接收。E-KAR 是首个可解释的知识密集型类比推理数据集,由 1,655 个(中文)和 1,251 个(英文)来自中国公务员考试的问题组成,并提出了类比推理问题的两个基准任务,用于教会和验证模型学习类比的能力。
? 论文链接:https://arxiv.org/abs/2203.08480? 项目主页:https://ekar-leaderboard.github.io现有的类比推理数据集,多以选择题的形式出现,下图是来自 BATS 数据集 [3] 的一个例子,选项分别是 “马克思” 比“德国人”、“孔子”比 “俄罗斯人”、“凯撒” 比“美国人”和 “柏拉图” 比“加拿大人”,需要选择的是与问题:“牛顿”比 “英国人” 相同对应关系的选项。
解决这种简单的类比问题,一种有效的方法是使用像 Word2Vec[2]这样静态的词嵌入,例如我们都很熟悉的这个方程式: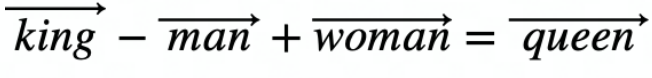
图 2 著名的词嵌入方程式(国王 - 男人 + 女人 = 王后)
这一类方法通常认为两个词语之间的关系可以通过词嵌入的向量运算来估计,这被称为线性类比(Linear Analogy)[4]。这种方法行之有效的原因之一是,目前的类比推理数据集通常被设计为评估线性类比属性。这类数据集富含简单的二元关系,如词汇、形态和简单的语义关系,像前面 “牛顿” 比“英国人”的例子,揭示的是 “人物” 和“国籍”的关系。此外,它们也是不可解释的,因此无法揭示实际的类似人类的类比推理过程。比起这种相对简单的线性类比,该研究专注于更加复杂的类比推理问题(Complex Analogy),这需要理解更多复杂的词语之间的关系。针对于此,本文提出了 E-KAR 数据集,参考一些类比相关的权威书籍和其他定义,完成这些问题还需要有一系列推理过程和背景知识,下图是其中的一个例子(读者可以尝试完成):
E-KAR 数据集是首个可解释的类比推理数据集,它有三个特点:挑战性、可解释性和双语性。E-KAR 具有挑战性,因为它来源于中国的公务员考试,这是一项对考生的批判性思维和解决问题能力的综合测试,想要解决其中的类比推理问题,需要考生理解选项中的关系,这要求一定的推理能力和背景知识,特别是常识、事实和文化知识,以及知道为什么一个事实被否定,例如汽车不是由轮胎制造的,因为汽车是由轮胎组成的。E-KAR 的第二个特点是可解释性,每条数据的问题和选项都有对应的人工注释的自由文本解释。但首先我们需要搞清楚:如何使类比推理可解释?为了回答这个问题,首先需要明白人类是如何进行类比推理的。根据一些认知心理学的研究[1],类比推理遵循一个结构映射 (structure-mapping) 过程。这个过程包含归纳,映射与检验三个步骤。我们以 E-KAR 中的一组数据为例(见图 4):1. 归纳 (Abduction):对于源域 (source domain) 与目标域 (target domain) 来说,首先设想出一个源结构 (source structure) ,这个结构也可能适用于目标域,在该数据集中,源域是问题,而目标域是每个选项,源结构是问题词之间的隐含关系,在例子中则是茶壶和茶杯都是盛放茶叶的容器,茶壶将茶叶输送到茶杯中;2. 映射 (Mapping):接着将这种结构映射到目标域,也就是说,将每个选项的词映射到查询中的源结构中;3. 检验 (Validation):最后,检查映射的有效性,并解释映射是否正确。在示例中,只有选项 C :"人才:学校:企业" 满足问题中的源结构。因为学校和企业是人才的组织,学校将人才运送到企业。
因此,该研究将结构映射的过程改写为自然语言文本,从而使类比推理的过程可解释,也就是 E-KAR 的可解释性。该研究利用机翻加人工后编辑的方式,将中文版的 E-KAR 翻译为了英文版本。在英文数据中,研究者手动删除了那些具有中文特征的数据(成语、典故等),以更好的方便非中文背景的研究者。由于这些数据具有高度的中国文化背景,研究者在中文数据集中保留了这部分数据以促进中文 NLP 的发展。最后,得到了 1655 条中文数据集和 1251 条英文数据集,各自有 8275 句和 6255 句自然语言形式的解释文本。E-KAR 的最终目标是使得模型能够做出正确的选择,同时产生合理的解释。为此,该研究在 E-KAR 中定义了两个共享任务:类比推理问答任务(Question Answering, QA)和类比解释生成任务(Explanation Generation, EG):该研究基于 E-KAR 在这两个任务上进行了一些初步实验,发现:该研究首先基于词嵌入和预训练语言模型 (BERT、RoBERTa) 进行了类比推理问答任务 (QA) 的实验,结果如图 5 所示,这表明无论是静态词嵌入还是目前最先进的语言模型,要想完成 E-KAR 这种复杂和知识密集型的类比推理任务都很困难。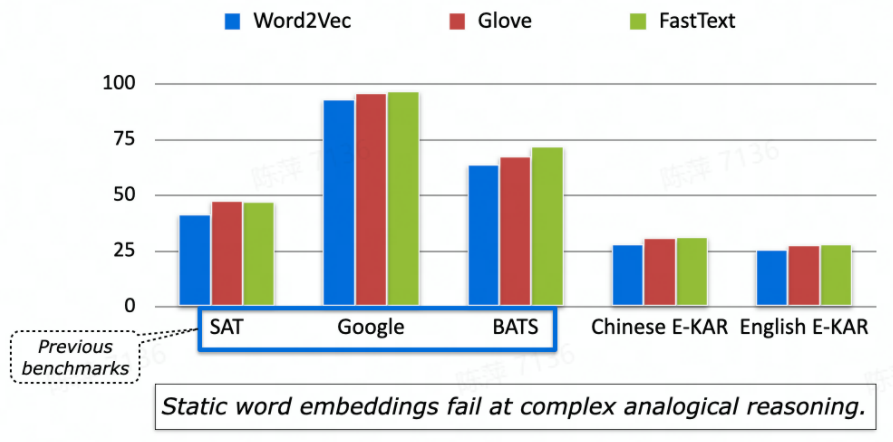
图 5 词嵌入在 E-KAR 和简单类比数据集上的准确率作为对比,人类能够达到 78% 的准确率,而表现最好的语言模型 (RoBERTa large) 只能达到 50%(图 6)。
图 6 词嵌入、语言模型和人类在简单类比与复杂类比上的准确率对比该研究对结果进行了错误分析(图 7),发现大多数错误发生在语义关系上,如 is_a、part_of、juxtaposition_of 等。这些类型的关系通常需要大量的常识和事实知识的参与。
该研究的类比解释生成可以生成每个问题和选项的对应解释,再将这些解释用于类比推理问答任务 (QA),这也是体现可解释性的关键步骤,然而一系列实验表明,语言模型并不能生成对类比推理问答任务(QA) 很有帮助的解释。首先,用该研究事先标注好的解释去作为额外的输入,能帮助类比推理问答任务 (QA) 达到接近完美准确率。然而替换成生成的解释时,结果却差很多(图 8)。
图 8 事先标注的解释与模型生成的解释对 QA 任务的帮助对比该研究也对类比解释生成任务 (EG) 进行了错误分析(图 9),发现问题主要出现在这三个方面:其中,该研究对否定词的生成特别感兴趣。结果显示约有 90% 的错误选项的人工标注解释,包含了否定词 "不",而在生成的解释中,这一数字则下降到约 20%。这似乎表明目前的生成模型不知道如何生成一个被否定但却是正确的事实。由于许多解释含有否定词,研究者探讨否定词的生成是否影响了模型的判断,为此该研究删除了测试集中含有否定词 NOT 的句子,结果发现准确率只下降了一点。因此,另一个结论是,当给出人工标注的解释时,类比推理问答 (QA) 任务的模型似乎并不偏向于否定词。图 9 展示了一个基本涵盖了上述几乎所有错误类型的例子。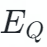 代表问题的解释,
代表问题的解释,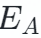 代表选项 A 的解释,
代表选项 A 的解释,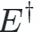 表示为模型 (BART large) 生成的,不带
表示为模型 (BART large) 生成的,不带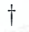 的是事先标注好的,可以看到,对于否定句,模型不知道盐和氯化钠都不是只由一种元素组成的,生成的解释偏向于 “A 是 B” 的模式。
的是事先标注好的,可以看到,对于否定句,模型不知道盐和氯化钠都不是只由一种元素组成的,生成的解释偏向于 “A 是 B” 的模式。
在这篇文章中,研究者提出了一个新的类比推理数据集 E-KAR,它具有挑战性,双语性和可解释性,同时研究者定义了两个该数据集的共享任务:类比推理问答任务 (QA) 和类比解释生成任务 (EG) ,用于教会模型如何学会类比的能力。该研究希望这项工作能补充现有的自然语言推理研究,特别是类比推理和可解释的 NLP 的相关研究。E-KAR 数据集中很多题目依赖于外部知识,需要对常识、百科和文化知识有一定理解,因此如何注入外部知识提升推理能力是未来的一大方向。注入外部知识可以通过自由文本、知识图谱等形式,代替解释作为输入的一部分,模型可以分为检索部分和问答部分。检索部分负责在外部知识库中搜索相关词组,并重构其相关知识的表示,问答部分负责融合检索到的外部知识与原输入,提升模型推理能力。1.Gerhard Minnameier. 2010. Abduction, induction, and analogy. In Model-based reasoning in science and technology, pages 107–119. Springer.2.Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.3.Gladkova A, Drozd A, Matsuoka S. Analogy-based detection of morphological and semantic relations with word embeddings: what works and what doesn’t[C]//Proceedings of the NAACL Student Research Workshop. 2016: 8-15.4.Ethayarajh K, Duvenaud D, Hirst G. Towards understanding linear word analogies[J]. arXiv preprint arXiv:1810.04882, 2018.5.Ushio A, Espinosa-Anke L, Schockaert S, et al. BERT is to NLP what AlexNet is to CV: can pre-trained language models identify analogies?[J]. arXiv preprint arXiv:2105.04949, 2021.
??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




