
六个深度学习常用损失函数总览:基本形式、原理、特点
来源:极市平台 本文共4500字,建议阅读8分钟 本文将介绍机器学习、深度学习中分类与回归常用的几种损失函数。
目录
前言
均方差损失 Mean Squared Error Loss
平均绝对误差损失 Mean Absolute Error Loss
Huber Loss
分位数损失 Quantile Loss
交叉熵损失 Cross Entropy Loss
合页损失 Hinge Loss
总结
前言
在正文开始之前,先说下关于 Loss Function、Cost Function 和 Objective Function 的区别和联系。在机器学习的语境下这三个术语经常被交叉使用。
- 损失函数 Loss Function 通常是针对单个训练样本而言,给定一个模型输出??和一个真实??,损失函数输出一个实值损失? - 代价函数 Cost Function 通常是针对整个训练集(或者在使用 mini-batch gradient descent 时一个 mini-batch)的总损失? - 目标函数 Objective Function 是一个更通用的术语,表示任意希望被优化的函数,用于机器学习领域和非机器学习领域(比如运筹优化)
一句话总结三者的关系就是:A loss function is a part of a cost function which is a type of an objective function.
由于损失函数和代价函数只是在针对样本集上有区别,因此在本文中统一使用了损失函数这个术语,但下文的相关公式实际上采用的是代价函数 Cost Function 的形式,请读者自行留意。
均方差损失 Mean Squared Error Loss
基本形式与原理
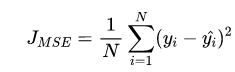

背后的假设

进一步我们假设数据集中 N 个样本点之间相互独立,则给定所有??输出所有真实值??的概率,即似然 Likelihood,为所有??的累乘
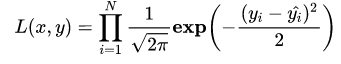
通常为了计算方便,我们通常最大化对数似然 Log-Likelihood
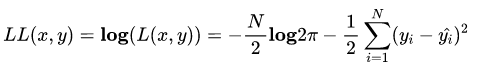
去掉与??无关的第一项,然后转化为最小化负对数似然 Negative Log-Likelihood

平均绝对误差损失 Mean Absolute Error Loss
基本形式与原理

同样的我们可以对这个损失函数进行可视化如下图,MAE 损失的最小值为 0(当预测等于真实值时),最大值为无穷大。可以看到随着预测与真实值绝对误差??的增加,MAE 损失呈线性增长

背后的假设

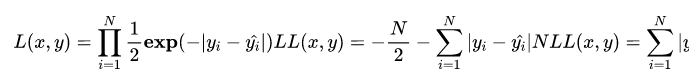
MAE 与 MSE 区别
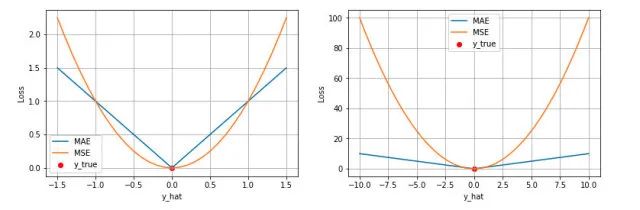
第一个角度是直观地理解,下图是 MAE 和 MSE 损失画到同一张图里面,由于MAE 损失与绝对误差之间是线性关系,MSE 损失与误差是平方关系,当误差非常大的时候,MSE 损失会远远大于 MAE 损失。因此当数据中出现一个误差非常大的 outlier 时,MSE 会产生一个非常大的损失,对模型的训练会产生较大的影响。
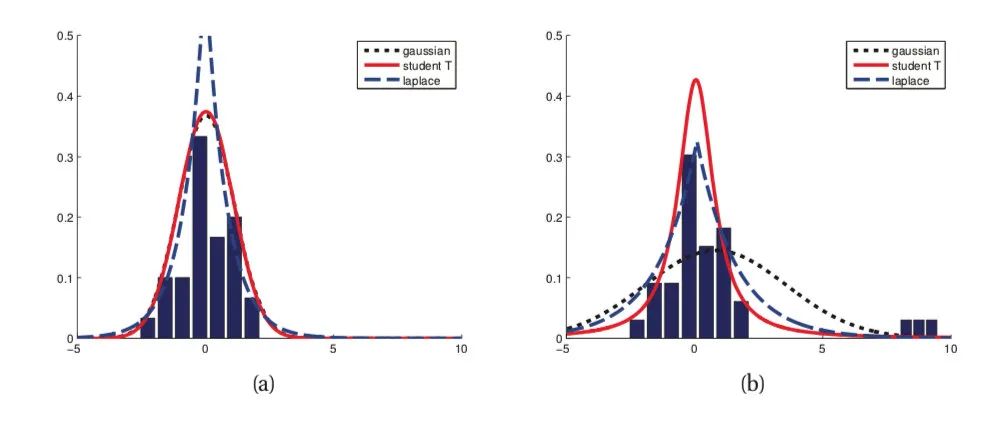
第二个角度是从两个损失函数的假设出发,MSE 假设了误差服从高斯分布,MAE 假设了误差服从拉普拉斯分布。拉普拉斯分布本身对于 outlier 更加 robust。参考下图(来源:Machine Learning: A Probabilistic Perspective 2.4.3 The Laplace distribution Figure 2.8),当右图右侧出现了 outliers 时,拉普拉斯分布相比高斯分布受到的影响要小很多。因此以拉普拉斯分布为假设的 MAE 对 outlier 比高斯分布为假设的 MSE 更加 robust。
Huber Loss

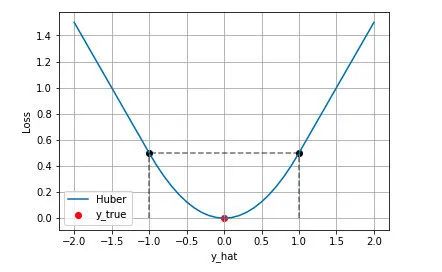
Huber Loss 的特点
分位数损失 Quantile Loss
分位数回归 Quantile Regression 是一类在实际应用中非常有用的回归算法,通常的回归算法是拟合目标值的期望或者中位数,而分位数回归可以通过给定不同的分位点,拟合目标值的不同分位数。例如我们可以分别拟合出多个分位点,得到一个置信区间,如下图所示(图片来自笔者的一个分位数回归代码 demo Quantile Regression Demo)

分位数回归是通过使用分位数损失 Quantile Loss 来实现这一点的,分位数损失形式如下,式中的 r 分位数系数。

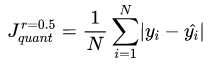

交叉熵损失 Cross Entropy Loss
上文介绍的几种损失函数都是适用于回归问题损失函数,对于分类问题,最常用的损失函数是交叉熵损失函数 Cross Entropy Loss。
二分类
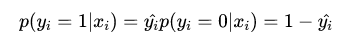


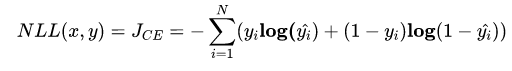
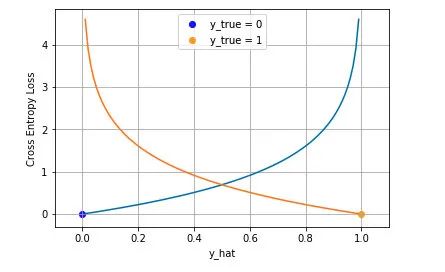
多分类
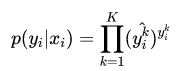
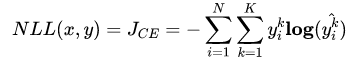

Cross Entropy is good. But WHY?
分类中为什么不用均方差损失?上文在介绍均方差损失的时候讲到实际上均方差损失假设了误差服从高斯分布,在分类任务下这个假设没办法被满足,因此效果会很差。为什么是交叉熵损失呢?有两个角度可以解释这个事情,一个角度从最大似然的角度,也就是我们上面的推导;另一个角度是可以用信息论来解释交叉熵损失:
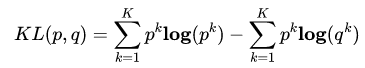
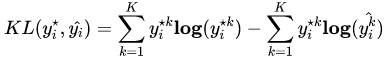
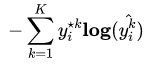
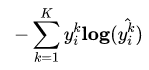
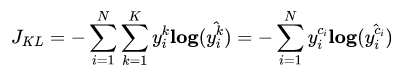
可以看到通过最小化交叉熵的角度推导出来的结果和使用最大 化似然得到的结果是一致的。
合页损失 Hinge Loss
合页损失 Hinge Loss 是另外一种二分类损失函数,适用于 maximum-margin 的分类,支持向量机 Support Vector Machine (SVM) 模型的损失函数本质上就是 Hinge Loss + L2 正则化。合页损失的公式如下

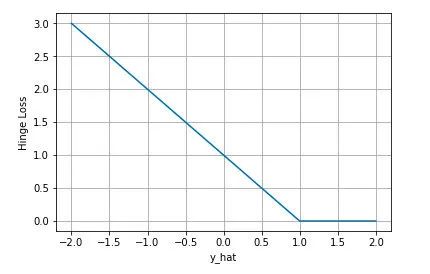
总结
本文针对机器学习中最常用的几种损失函数进行相关介绍,首先是适用于回归的均方差损失 Mean Squared Loss、平均绝对误差损失 Mean Absolute Error Loss,两者的区别以及两者相结合得到的 Huber Loss,接着是应用于分位数回归的分位数损失 Quantile Loss,表明了平均绝对误差损失实际上是分位数损失的一种特例,在分类场景下,本文讨论了最常用的交叉熵损失函数 Cross Entropy Loss,包括二分类和多分类下的形式,并从信息论的角度解释了交叉熵损失函数,最后简单介绍了应用于 SVM 中的 Hinge 损失 Hinge Loss。本文相关的可视化代码在 这里。
受限于时间,本文还有其他许多损失函数没有提及,比如应用于 Adaboost 模型中的指数损失 Exponential Loss,0-1 损失函数等。另外通常在损失函数中还会有正则项(L1/L2 正则),这些正则项作为损失函数的一部分,通过约束参数的绝对值大小以及增加参数稀疏性来降低模型的复杂度,防止模型过拟合,这部分内容在本文中也没有详细展开。读者有兴趣可以查阅相关的资料进一步了解。
转自:?极市平台;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

![李杨璐 懒到只想发live……[二哈]](https://imgs.knowsafe.com:8087/img/aideep/2021/10/29/6e9ea3de3e8cce7ab3108418431620c9.jpg?w=250)




 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675