
注意力机制YYDS,AI编辑人脸终于告别P一处而毁全图
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
“Attention is all you need!”
这句名言又在新的领域得到了印证。
来自深圳大学和特拉维夫大学的最新成果,通过在GAN中引入注意力机制,成功解决了编辑人脸时会产生的一些“手抖”问题:
比如改变人的发型时把背景弄乱;

加胡子时影响到头发、甚至整张脸都不太像是同一个人了:

这个有了注意力机制的新模型,修改图像时清清爽爽,完全不会对目标区域之外产生任何影响。

具体怎么实现?
引入注意力图
此模型名叫FEAT?(Face Editing with Attention),它是在StyleGAN生成器的基础上,引入注意力机制。
具体来说就是利用StyleGAN2的潜空间进行人脸编辑。
其映射器(Mapper)建立在之前的方法之上,通过学习潜空间的偏置(offset)来修改图像。
为了只对目标区域进行修改,FEAT在此引入了注意图?(attention map),将源潜码获得的特征与移位潜码的特征进行融合。

为了指导编辑,模型还引入了CLIP,它可以用文本学习偏移量并生成注意图。
FEAT的具体流程如下:
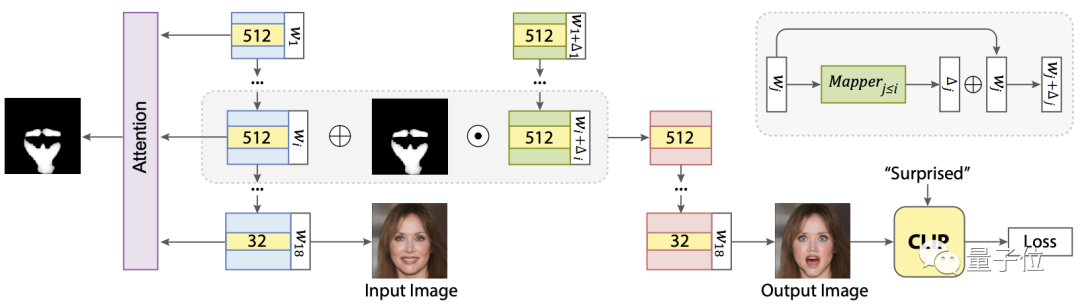
首先,给定一张具有n个特征的图像。如上图所示,浅蓝色代表特征,黄色部分标记通道数量。
然后在文字提示的指导下,为所有能预测相应偏置(offset)的样式代码(style code)生成映射器。
这个映射器通过潜码加偏置(wj+ Δj)修改,生成映射图像。
再接着,用注意力模块生成的attention map将原始图像和映射图像的第i层特征进行融合,生成我们要的编辑效果。
其中,注意力模块的架构如下:
左侧是用于特征提取的StyleGAN2生成器,右为用于制作注意图的Attention Network。

不修改目标区域之外的图像
在实验对比环节中,研究人员首先将FEAT与最近提出的两种基于文本的操作模型进行比较:TediGAN和StyleCLIP。
其中TediGAN将图像和文本都编码到StyleGAN潜空间中,StyleCLIP则实现了三种将CLIP与StyleGAN相结合的技术。

可以看到,FEAT实现了对面部的精确控制,没有对目标区域以外的地方产生任何影响。
而TediGAN不仅没有对发型改变成功,还把肤色变暗了(第一行最右)。
在第二组对表情的改变中,又把性别给改了(第二行最右)。

StyleCLIP整体效果比TediGAN好很多,但代价是变得凌乱的背景?(上两张图中的第三列,每张效果的背景都受到了影响)。
接着将FEAT与InterFaceGAN和StyleFlow进行比较。
其中InterfaceGAN在GAN潜空间中执行线性操作,而StyleFlow则在潜空间中提取非线性编辑路径。
结果如下:

这是一组加胡子的编辑,可以看到InterfaceGAN和StyleFlow在此操作之余对头发和眉毛做了细微改动。
除此之外,这两种方法还需要标记数据进行监督,不能像FEAT一样进行零样本操作。
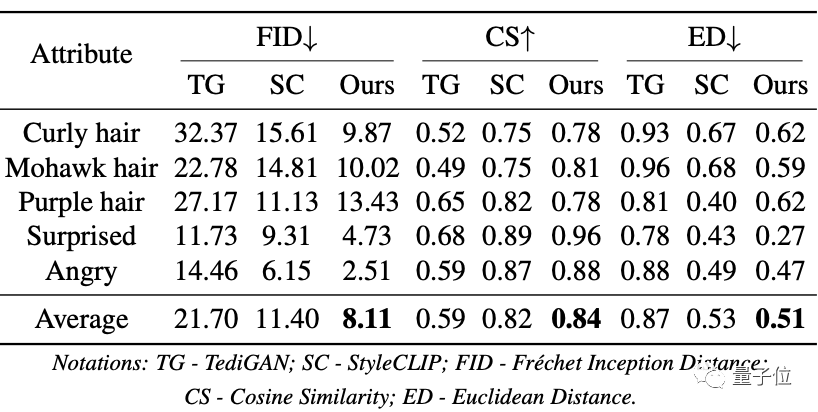
在定量实验中,FEAT也展现出了它的优越性。
在五个属性的编辑结果中,FEAT比TediGAN和StyleCLIP在视觉质量(FID得分)和特征保留(CS和ED得分)方面表现更佳。
关于作者
一作侯贤旭来自深圳大学。

他本科和硕士毕业于中国矿业大学地理学和地质学专业,博士毕业于诺丁汉大学计算机科学专业,主要研究方向为计算机视觉和深度学习。
通讯作者为沈琳琳, 深圳大学模式识别与智能系统专业硕士生导师, 目前研究方向为人脸/指纹/掌纹等生物特征识别、医学图象处理、模式识别系统。
他本硕毕业于上海交大应用电子专业,博士也毕业于诺丁汉大学。其谷歌学术引用次数已达7936次。
论文地址:
https://arxiv.org/abs/2202.02713
— 完 —
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里 关注公众号:拾黑(shiheibook)了解更多 [广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 量子位
量子位
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675