
7 Papers & Radios | 索尼AI赛车手登上Nature封面;牛津大学博士论文阐述神经微分方程
本周论文包括:哈佛大学和埃默里大学的科学家研发的一种「合成鱼」装置,登上了顶级学术期刊《Science》;索尼 AI 赛车手登上 Nature 封面等研究。
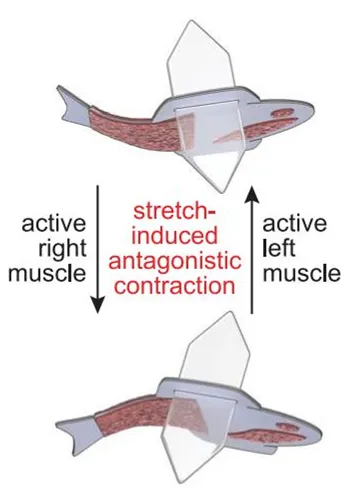
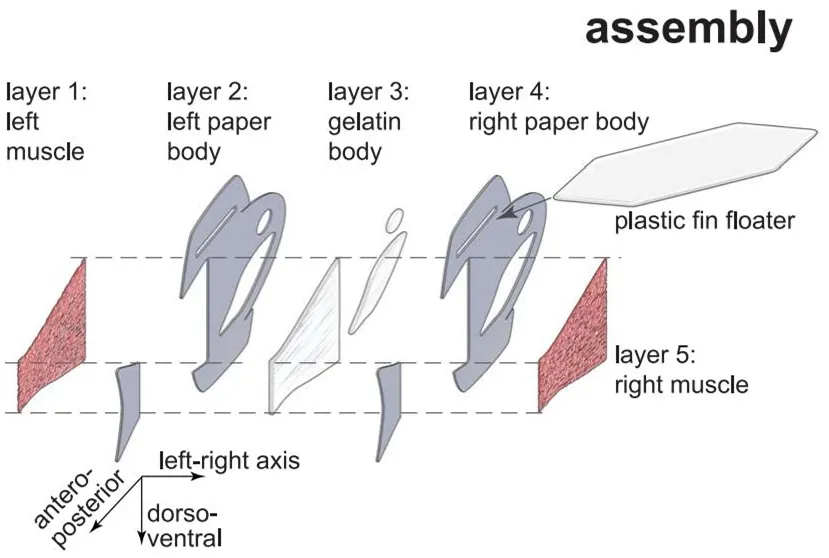
An autonomously swimming biohybrid fish designed with human cardiac biophysics
A Model-Agnostic Causal Learning Framework for Recommendation using Search Data?
Outracing champion Gran Turismo drivers with deep reinforcement learning
On Neural Differential Equations?
SLIP: Self-supervision meets Language-Image Pre-training
MESSAGE PASSING NEURAL PDE SOLVERS?
pNLP-Mixer: an Efficient all-MLP Architecture for Language?
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
作者:KEEL YONG LEE、SUNG-JIN PARK 等
论文链接:https://www.science.org/doi/10.1126/science.abh0474

作者:Zihua Si 、 Xueran Han 、 Xiao Zhang 等
论文链接:https://arxiv.org/abs/2202.04514

作者:Peter R. Wurman、Samuel Barrett 等
论文链接:https://www.nature.com/articles/s41586-021-04357-7
超现实模拟器
新型强化学习技术
分布式训练平台
大规模训练基础设施


作者:Patrick Kidger
论文链接:https://arxiv.org/pdf/2202.02435.pdf
神经常微分方程(neural ordinary diffeqs):用于学习物理系统,作为离散架构的连续时间限制,包括对可表达性的理论结果;
神经受控微分方程(neural controlled diffeqs):用于建模时间序列函数、处理不规则数据;
神经随机微分方程(neural stochastic diffeqs):用于从复杂的高维随机动态中采样;
数值法(numerical methods):一类新的可逆微分方程求解器或布朗重建(Brownian reconstruction)问题。
作者:Norman Mu 、 Alexander Kirillov 等
论文链接:https://arxiv.org/pdf/2112.12750v1.pdf


作者:Johannes Brandstetter 、 Daniel E. Worrall
论文链接:https://arxiv.org/pdf/2202.03376.pdf
提出一个基于神经消息传递(message passing, MP)的端到端全神经 PDE 求解器,其灵活性能够满足典型 PDE 问题的所有结构需求。这一设计的灵感来源于一些经典求解器(有限差分、有限体积和 WENO 格式)可以作为消息传递的特例;
提出时间捆绑(temporal bundling)和前推(pushforward)技巧,以在训练自回归模型中鼓励零稳定性(zerostability);
在给定类中实现跨多个 PDE 的泛化。在测试期间,新的 PDE 稀疏可以成为求解器的输入。

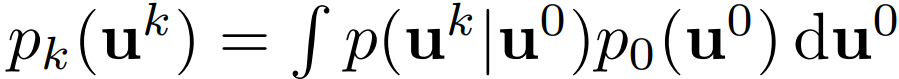
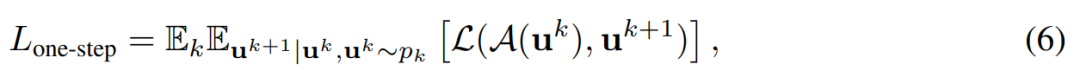

作者:Francesco Fusco 、 Damian Pascual 等
论文链接:https://arxiv.org/pdf/2202.04350.pdf


1. TaxoEnrich: Self-Supervised Taxonomy Completion via Structure-Semantic Representations. (from Jiawei Han)
2. Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. (from Jiawei Han)
3. Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations. (from Jiawei Han)
4. Zero-Shot Aspect-Based Sentiment Analysis. (from Bing Liu)
5. Evaluating natural language processing models with generalization metrics that do not need access to any training or testing data. (from Kannan Ramchandran, Michael W. Mahoney)
6. Cross-Platform Difference in Facebook and Text Messages Language Use: Illustrated by Depression Diagnosis. (from Lyle Ungar)
7. AdaPrompt: Adaptive Model Training for Prompt-based NLP. (from Yang Liu)
8. No Parameters Left Behind: Sensitivity Guided Adaptive Learning Rate for Training Large Transformer Models. (from Jianfeng Gao)
9. Interactive Mobile App Navigation with Uncertain or Under-specified Natural Language Commands. (from Kate Saenko)
10. LEAPMood: Light and Efficient Architecture to Predict Mood with Genetic Algorithm driven Hyperparameter Tuning. (from Sumit Kumar)本周 10?篇 CV 精选论文是:
1. Learning with Neighbor Consistency for Noisy Labels. (from Cordelia Schmid)
2. MaskGIT: Masked Generative Image Transformer. (from Ce Liu, William T. Freeman)
3. Residual Aligned: Gradient Optimization for Non-Negative Image Synthesis. (from Serge Belongie)
4. Advances in MetaDL: AAAI 2021 challenge and workshop. (from Isabelle Guyon)
5. Point-Level Region Contrast for Object Detection Pre-Training. (from Alan Yuille, Alexander C. Berg)
6. Causal Scene BERT: Improving object detection by searching for challenging groups of data. (from Kyunghyun Cho)
7. FEAT: Face Editing with Attention. (from Daniel Cohen-Or)
8. Self-Conditioned Generative Adversarial Networks for Image Editing. (from Daniel Cohen-Or)
9. Ada-NETS: Face Clustering via Adaptive Neighbour Discovery in the Structure Space. (from Ming Lin)
10. GiraffeDet: A Heavy-Neck Paradigm for Object Detection. (from Ming Lin)本周 10?篇 ML 精选论文是:
1. Image-to-Image Regression with Distribution-Free Uncertainty Quantification and Applications in Imaging.? (from Jitendra Malik)
2. Conformal prediction for the design problem.? (from Michael I. Jordan)
3. Transferred Q-learning.? (from Michael I. Jordan)
4. Reward-Respecting Subtasks for Model-Based Reinforcement Learning.? (from Richard S. Sutton)
5. Robust Hybrid Learning With Expert Augmentation.? (from Guillermo Sapiro)
6. Evaluation Methods and Measures for Causal Learning Algorithms.? (from Huan Liu)
7. LTU Attacker for Membership Inference.? (from Isabelle Guyon)
8. Hidden Heterogeneity: When to Choose Similarity-Based Calibration.? (from Thomas G. Dietterich)
9. Predicting Human Similarity Judgments Using Large Language Models.? (from Thomas L. Griffiths)
10. Can Humans Do Less-Than-One-Shot Learning?.? (from Thomas L. Griffiths)

??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675