为了让 GPT-3 模型可以更准确地对开放式问题进行回答,研究人员使用了基于文本的网络浏览器对 GPT-3 进行微调。微调后的 WebGPT 模型可以对人类实时回答问题的方法进行学习,比如提交搜索、跟踪链接并上下滚动网页。研究人员发现在模型中添加引用答案的来源,可以对答案进行追溯并提高准确性。研究者们很高兴开发更真实的人工智能[1]模型,但在遇到不熟悉的开放式问题时,还是存在很大挑战。GPT-3 语言模型可以在多个不同任务中起作用,但在完成一些需要现实世界之外知识[2,3]的任务时,往往会出现“令人困惑”的结果。为了解决这个问题,研究人员使用基于文本的网络浏览器对 GPT-3 训练。这种模型中包含开放式问题和浏览器状态信息,当人们发出诸如“搜索……”、“在页面中找到:……”或者“引用:……”等命令时,模型会通过收集网页上的文章来组成答案。WebGPT 是利用一般的通用方法从 GPT-3 中微调出来的模型,通过学习人类回答问题的方式,使用基于文本的浏览器回答问题。然后通过训练奖励模型来预测人类偏好,并使用强化学习或拒绝采样来进行优化,从而提高模型答案的可用性和准确性。
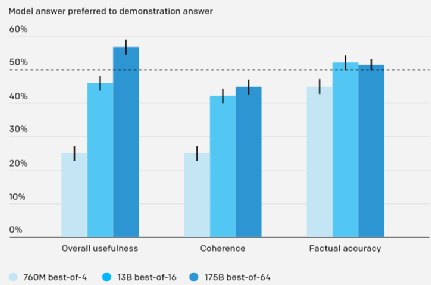
经过训练的 WebGPT 系统可以回答来自开放式数据集ELI5[4]的问题,例如数据集中“Explain Like I’m Five”版块的部分问题。研究人员训练了三个不同模型,对应于三种不同的推理时间。结果如下图所示,性能最好的模型,在 56% 的时间里比人类给出的答案更受欢迎,而且答案的事实准确性与人类基本相同。这是因为 WebGPT 模型虽然用相同类型的数据进行训练,但它能够通过人类反馈对答案进行改进,从而超过人类的原始答案。
模型与人类在 ELI5 测试集上的评价结果比较,根据计算效率选择拒绝采样数( best-of-n 中的 n)
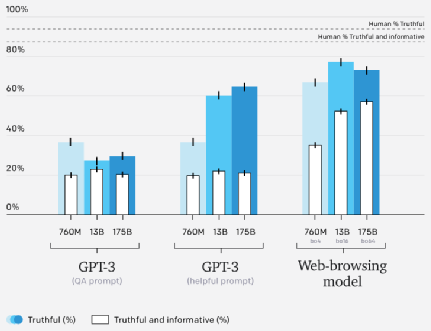
对于训练分布方面的问题,WebGPT 最佳模型的平均答案与人类演示者所写答案一样准确,但对于回答分布之外的问题还有一定困难。为此,研究者们在 TruthfulQA [5] 数据集上对模型进行评估。TruthfulQA 是由对抗性结构的简短问答题组成的数据集,旨在测试模型是否会受到常见错误的影响。模型会根据问题答案的真实性和信息性两部分进行评分,并且这两部分是相互制约的(例如,“无可奉告”被认为是真实的,但不具有信息丰富性)。
WebGPT 模型在 TruthfulQA 上的性能优于 GPT-3,具有更有利的缩放特性。但是 WebGPT 比人类的表现要差,一部分原因是因为它们有时会引用不可靠来源的信息。所以后续希望使用对抗训练等技术来减少这类错误。在 TruthfulQA 上的结果比较。GPT-3 模型中使用了 TruthfulQA 论文中的操作和自动评估方法,web-browsing 模型中对长句答案进行截断并使用人工评估(因为答案在可以自动评估的分布之外)
为了利用反馈提高模型的事实准确性,人类必须准确评估模型产生结果的事实准确性。
但结果可能是技术性的、主观的或模糊的,评估起来非常具有挑战性。为此,研究人员要求模型引用答案的来源[6],使人们可以通过检查答案来源的可靠性来评估事实准确性。这种方法使问题更容易处理,同时减少了问题的模糊性,对于减少错误标签方面非常重要。
但这种方法也引发了许多问题。比如哪些信息来源更可靠?哪些特别浅显的答案并不需要引用?如何在评估事实准确性和其他标准(如连贯性)之间进行权衡?这些问题是很难判断的。
研究者们认为目前的模型还没有能力注意到这些细微差别,所以仍然会犯一些低级错误。但随着人工智能系统的改进,这类问题的答案会越来越重要。因此需要通过交叉学科研究,来制定既实用又有理有据的标准。比如研究者们准备开始考虑模型的可理解性[1]。仅仅让模型引用答案的来源还不足以评估事实准确性。一个足够强大的模型会挑选出它认为有说服力的来源进行引用,即使没有证据证明这些来源的可靠性。这种情况已经正在发生,并且研究者们还希望使用类似辩论的方法来进行改善。
虽然 WebGPT 模型比 GPT-3 性能更好更真实,生成错误答案的频率更低,但它仍然存在风险。虽然带有引用的答案看起来比较权威,但这并不能掩盖模型仍然会犯基本错误的事实。并且模型也更倾向于强化用户已有的知识,而不是产生新知识。研究者们正在努力解决这些问题。
除了上述风险之外,在训练时让模型访问 web 的方法还会引入新风险。目前的浏览器环境不允许完全的网络访问,但允许模型向微软必应网络(Microsoft Bing Web Search API )发送查询,并跟踪网络上的链接。从使用 GPT-3 的经验来看,这可能会产生副作用,因为模型还没有足够的能力去减少错误使用。并且这些风险会随着模型能力的增加而增加,所以需要努力建立内部保障措施来避免这些风险。
人类反馈和网络浏览器等工具为实现可靠、通用的人工智能系统提供了一条光明之路。虽然目前的系统仍在困难或不熟悉的环境中不断挣扎,但仍然称得上是一次重大进步。
[1]O. Evans, O. Cotton-Barratt, L. Finnveden, A. Bales, A. Balwit, P. Wills, L. Righetti, and W. Saunders. Truthful AI: Developing and governing AI that does not lie. arXiv preprint arXiv:2110.06674, 2021.[2]J. Maynez, S. Narayan, B. Bohnet, and R. McDonald. On faithfulness and factuality in abstractive summarization. arXiv preprint arXiv:2005.00661, 2020.[3]K. Shuster, S. Poff, M. Chen, D. Kiela, and J. Weston. Retrieval augmentation reduces hallucination in conversation. arXiv preprint arXiv:2104.07567, 2021.[4]A. Fan, Y. Jernite, E. Perez, D. Grangier, J. Weston, and M. Auli. ELI5: Long form question answering. arXiv preprint arXiv:1907.09190, 2019.[5]S. Lin, J. Hilton, and O. Evans. TruthfulQA: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021. [6]D. Metzler, Y. Tay, D. Bahri, and M. Najork. Rethinking search: Making experts out of dilettantes. arXiv preprint arXiv:2105.02274, 2021.
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








![陈巨可爱包饺子偷懒被抓住了[衰]](https://imgs.knowsafe.com:8087/img/aideep/2022/3/25/5c16c934d55a773840683c5d05181115.jpg?w=250)




 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




