选自DeepMind Blog
作者:?iga Avsec
机器之心编译
继蛋白质结构预测之后,一路领跑的 DeepMind 又将 AI 的触角伸向了 DNA。
当人类基因组计划成功地绘制出人类基因组的 DNA 序列时,整个国际研究界都为之一振。因为这样一来,人类就有机会进一步了解影响人类健康和发展的遗传指令。从眼球颜色到是否容易患某种疾病,DNA 携带着决定一切的基因信息。人体内大约有 2 万个 DNA 片段被确定为基因,其中包含有关蛋白质氨基酸序列的指令,这些蛋白质在我们的细胞中执行许多基本功能。然而,这些基因占整个基因组的比重还不到 2%。剩下的碱基对——占基因组 30 亿个「字母」的 98%——被称为「非编码」,包含一些不太为人所知的指令,这些指令让基因知道应该在何时、何地产生或表达。为了更好地完成人类遗传学的很多下游应用任务,我们必须弄清楚非编码区 DNA 如何决定不同细胞类型中的基因表达。10 月 4 日,DeepMind 与谷歌旗下生物科技公司 Calico 的一项研究登上了国际顶级方法学期刊《Nature Methods》。在这篇论文中,他们引入了一种叫做 Enformer 的神经网络架构,大大提高了根据 DNA 序列预测基因表达的准确性。为了进一步研究疾病中的基因调控和致病因素,研究者还公开了他们的模型及其对常见遗传变异的初步预测。
DeepMind 的研究者表示,「我们相信 AI 可以帮助我们深入理解这些复杂的领域,加速科学进步,并未人类健康带来潜在收益。」以往关于基因表达的研究通常使用卷积神经网络作为基本构建块,但这些网络在建模远端增强子(enhancer)对基因表达的影响方面存在局限。增强子是 DNA 上一小段可与蛋白质结合的区域,与蛋白质结合之后,基因的转录作用将会加强。增强子可能位于基因上游,也可能位于下游,且不一定接近所要作用的基因,这是因为染色质的缠绕结构,使序列上相隔很远的位置也有机会相互接触。因此,要想精确研究增强子对基因表达的影响,模型需要「阅读」尽可能长的 DNA 序列。DeepMind 表示,他们最初的探索依赖于 Calico 的 Basenji2 模型,它可以从相对较长的 DNA 序列(40, 000 个碱基对)中预测调控活性,但这个长度还是不够。基于这些认识,研究者意识到,要想捕获长序列,必须在基本架构层面进行改变。于是,他们开发了一个基于 Transformer 的新模型——Enformer,以利用自注意力机制处理更大范围的 DNA 上下文。和擅长阅读长文本的 Transformer 类似,改造后的 Enformer 能够「阅读」很长的 DNA 序列,可处理的序列长度达到之前的 5 倍(200, 000 个碱基对)。有了这样一个模型,研究者就能从更长的 DNA 序列上建模增强子对基因表达的影响。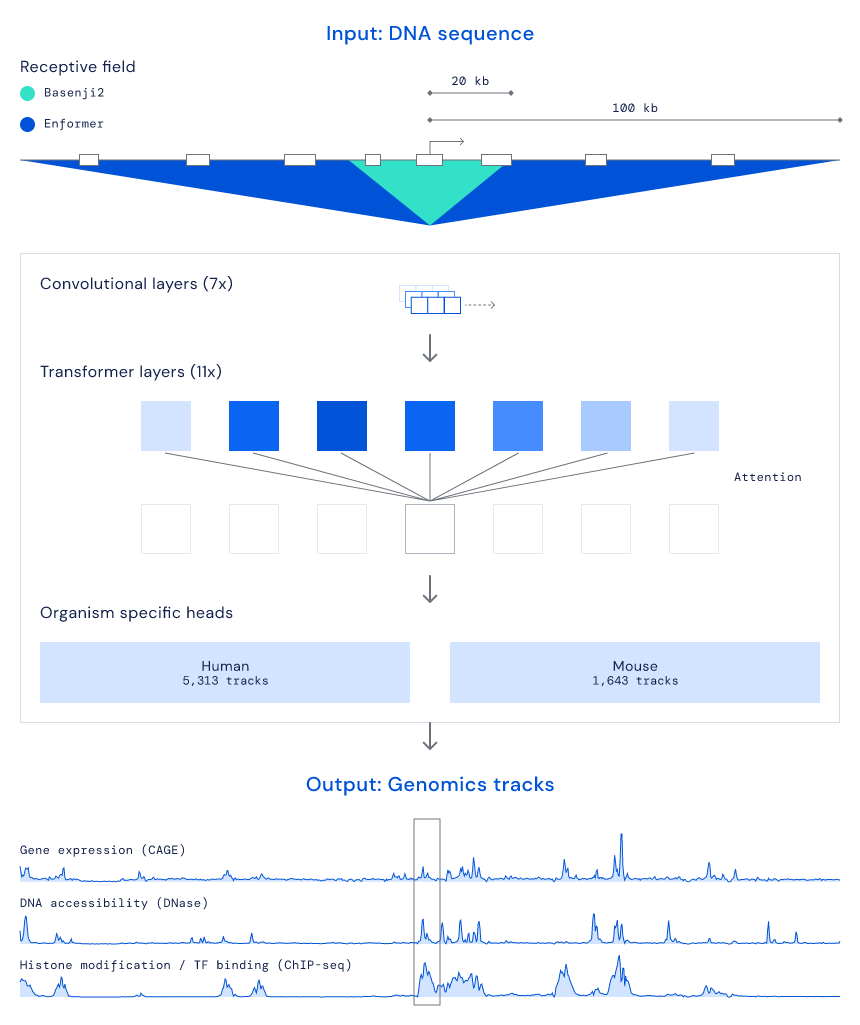
研究者训练 Enformer 以预测功能性基因组数据,包括来自输入 DNA 的 200, 000 个碱基对的基因表达。上图的示例展示了 5000 多种可能的基因组轨迹中的 3 种。为了更好地理解 Enformer 是如何解释 DNA 序列以得到更准确的预测的,研究者使用贡献分(contribution score)来突出输入序列中对预测影响最大的部分。如同生物直觉一般,研究者发现即使距离基因超过 50000 个碱基对,模型也会注意到增强子。预测哪些增强子调控哪些基因仍然是基因组学中一个尚未解决的问题,研究显示, Enformer 的贡献分与专门为此任务开发的现有方法(使用实验数据作为输入)表现相当。此外,Enformer 还理解了绝缘子元件(insulator element),后者将 DNA 的两个独立调控区域分隔开。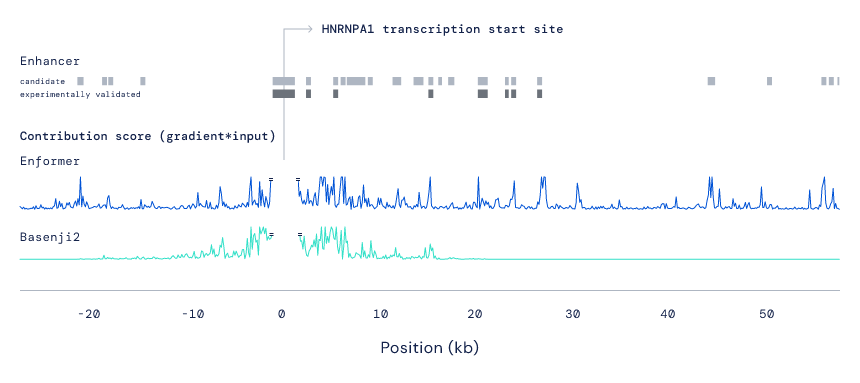
Enformer 注意到的相关的调控 DNA 区域(蓝色),增强子为灰色块。目前全面研究生物体的 DNA 已经成为了可能的事,但要想理解基因组还需要复杂的实验。尽管进行了大量的实验,大多数 DNA 对基因表达的控制仍然是个谜。借助人工智能技术,人类可以探索在基因组中发现模式的新的可能性,并提供关于序列变化的机制假设。与拼写检查器的原理类似,Enformer 能够部分理解 DNA 序列的「词汇」,因此能够「高亮」那些可能导致基因表达改变的编辑。这一新模型的主要应用是预测 DNA 字母的变化,也称为基因变异,它会改变基因表达。与以前的模型相比,Enformer 在预测变异对基因表达的影响方面更加准确,无论是自然遗传变异还是改变重要调控序列的合成变异。借助这一特性,我们可以对越来越多的疾病相关变异进行研究。要知道,与复杂遗传疾病相关的变异主要位于基因组的非编码区,可能通过改变基因表达引起疾病。但是由于变异之间的内在联系,这些疾病相关的许多变异只是虚假的联系,而非因果关系。现在,计算工具可以帮助区分真正的联系和假阳性。当然,人类基因组中仍有尚未解开的谜团,Enformer 只是在理解基因组序列的复杂性方面向前迈出了一步。DeepMind 的研究者希望这些进展能让与人类疾病相关的更高效的精细定位成为可能,并提供一个解释顺式调控演变的框架。参考链接:https://deepmind.com/blog/article/enformer机器之心招人啦!
为进一步生产更多的高质量内容,提供更好数据产品及产业服务,机器之心需要更多的小伙伴加入进来,共同努力打造专业的人工智能信息服务平台。
工作城市:北京市朝阳区酒仙桥 / 上海张江人工智能岛??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




