
综述:药物发现中的机器学习


药物设计应用
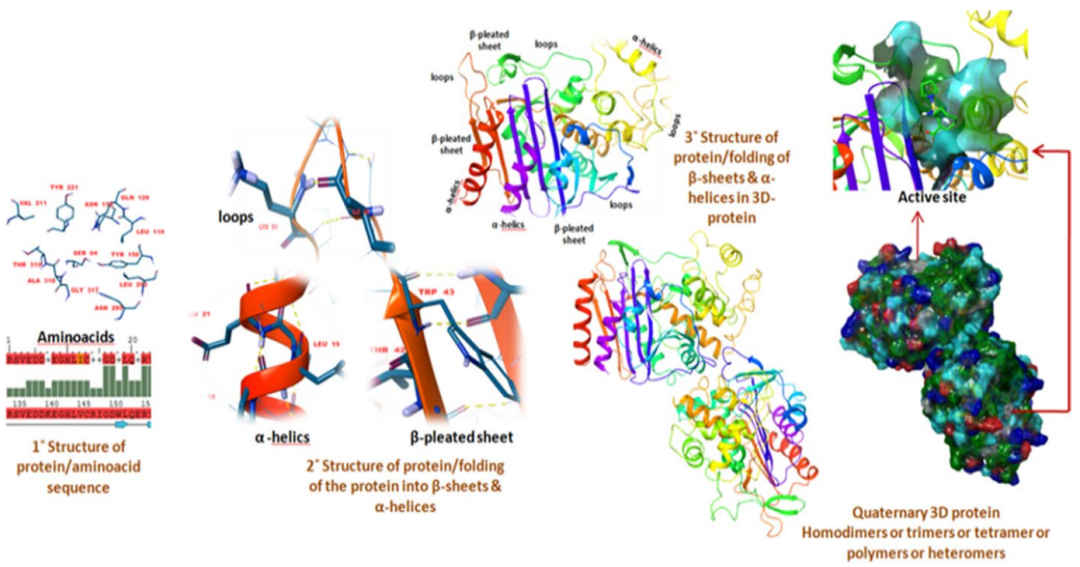
蛋白质与蛋白质相互作用的预测

Hit发现
分子对接技术的高吞吐量虚拟筛选和评分
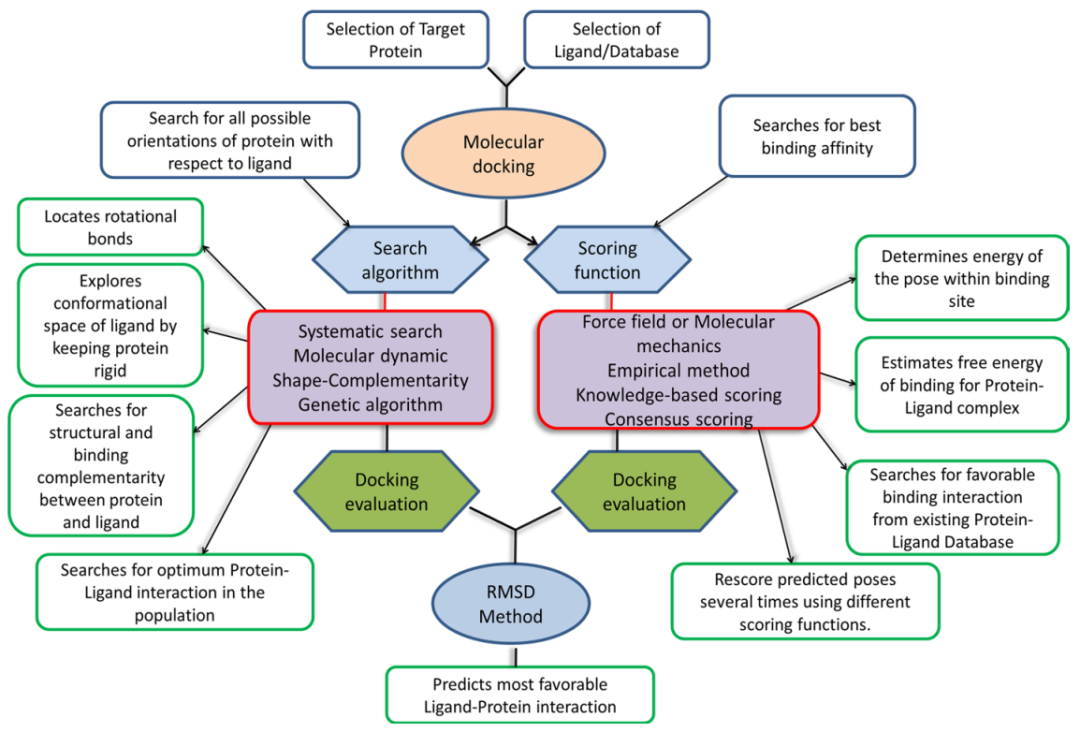
命中领先


先导优化
用于药物发现电子资源中的 ML

图示:药物发现平台电子资源中的机器学习。(来源:论文)
泛检测干扰筛查中的 ML (PAINS)?可以根据要求从 PAINS 数据库访问泛检测信息。从 Pubchem 库和筛选分析中编译出来的 Hit Dexter 2.0,可用于了解新设计化合物的生物学特性。 药物代谢物和代谢位点预测中的 ML??在进入临床实验之前,确定药物或新化学实体的代谢部位是非常必要的。药物代谢的预测可以通过动物模型(临床前研究)来完成,这是一个限制效率的步骤,而且成本高昂。利用机器学习模型可以解决这一问题,已经可以用于预测新陈代谢的工具有 ADMET预测器、FAME3、GLORY/GLORYx 等。 皮肤敏感参数预测中的 ML??皮肤敏感性的预测是评估新药/化合物安全性参数的基本标准之一。在这方面,基于随机森林的 MACCS(RF_MACCS)和基于支持向量机(SVM)的 PaDEL(SVM_PaDEL)算法等 AI 模型已经训练了大约 1400 个与局部淋巴结检测(LLNA)信息相关的配体。 天然产品标识中的 ML??用 265,000 个天然产物分离物和经 MCC 验证的合成文库训练的 ML,被用作基本预测模型 NP Scout 在线服务器,将揭示新发现的药物类似物的可能身份。NP Scout 在查询分子来源预测中的应用,可以提供有关其天然产物来源的信息,并可能成为基于天然产物的药物发现过程的重要组成。
药物发现问题
目标验证
预测生物标志物
数字病理学
挑战
在训练期间有几个参数和结构会导致 ML 策略产生问题。特别是在训练期间数据不足的情况下,特定的算法不能满足精度和局部最优。 透明度问题是药物发现的另一个挑战。在不同分类模型中的决策规则是不清楚的。在药物开发中,机器学习模型需要理解多种机制来解释结果,并且需要多个组合特征来提高对可解释性的信任度 。 可以从许多参考文献中访问集成数据,尤其是「组学」区域。 同质数据会产生集成挑战。 在制药公司,研究从巨大的分子延伸到个体,并且通常依赖于异构数据的整合;这些数据需要在不同的背景和规模下维持其自身,这本书就是一项挑战。
结论和未来方向
深度学习方法的性能可以直接影响数据挖掘的创新,因为多个深度神经网络在大量数据上得到有效训练。主要目的是解决迁移学习的自动问题。 「黑盒」模型在深度学习概念中变得混乱。Local Interpretable Model-Explanations(LIME)是反事实调查的一个例子。LIME 被用来解锁黑盒模型。在这里,必须通过深度学习模型来解释受限数据。然而,通过深度学习技术揭示数据仅在初始阶段发挥作用。 许多参数在神经网络的训练期间进行了调整,但一些理论和实践框架无法优化这些模型。
人工智能?×?[?生物 神经科学?数学 物理 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675