
涂鸦智能选型 TiKV 的心路历程
本文来自涂鸦智能的刘筠松在 PingCAP DevCon 2021 上的分享,包括 TiDB 在 IoT 领域,特别是在智能家居行业的使用。
关于涂鸦智能
涂鸦智能是一个全球化 IoT 开发平台,?打造互联互通的开发标准,连接品牌、OEM 厂商、开发者、零售商和各行业的智能化需求。基于全球公有云,实现智慧场景和智能设备的互联互通。涵盖硬件开发工具、全球公有云、智慧商业平台开发三方面;?提供从技术到营销渠道的全面赋能,打造中立且开放的开发者生态。

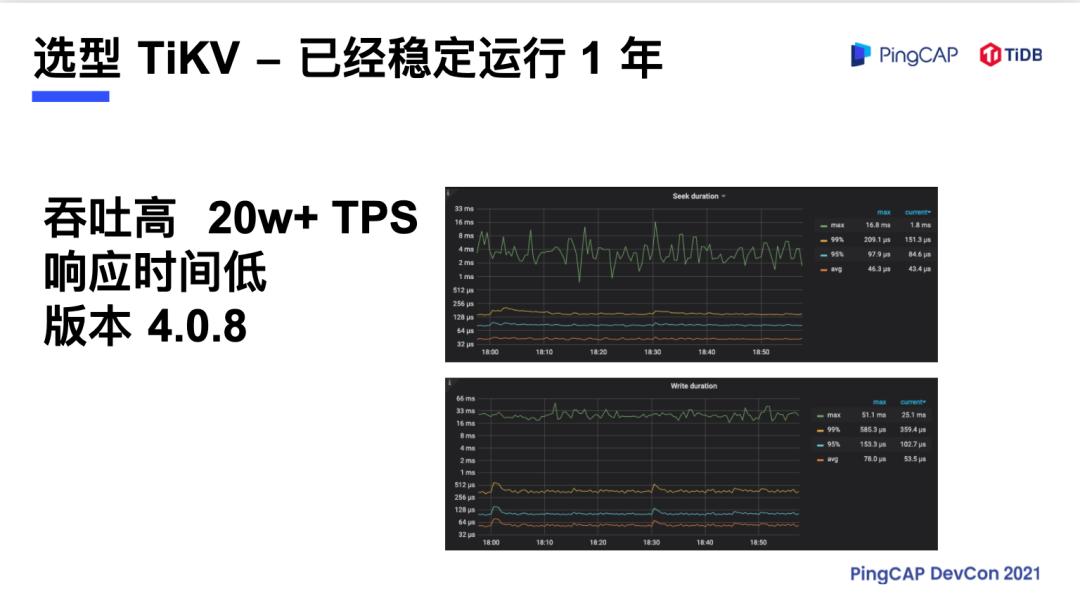
海量数据的实时响应:TiKV 选型历程
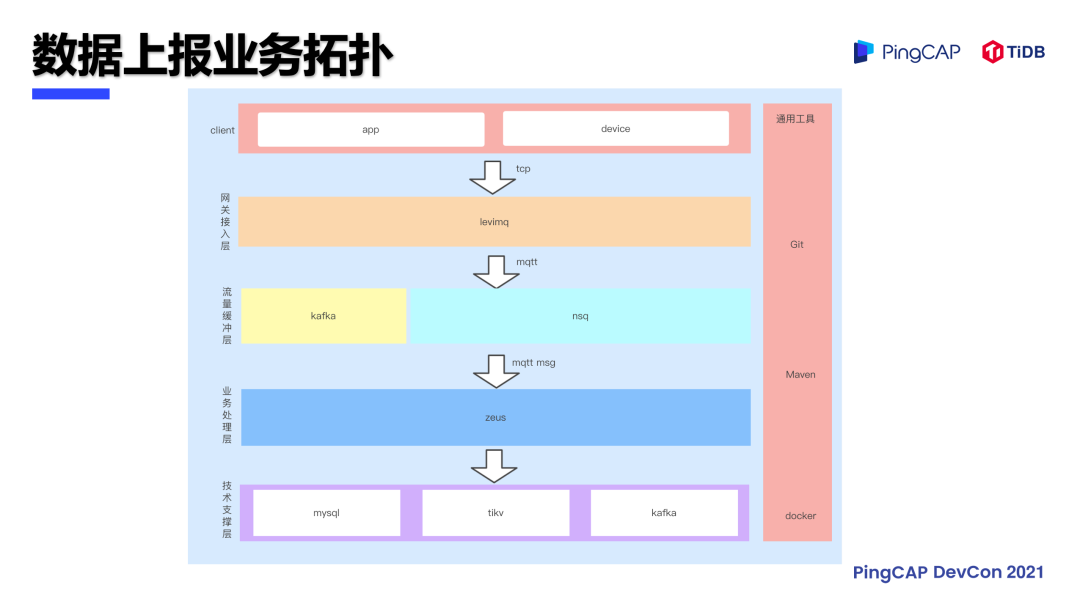
涂鸦的设备在全球每天处理 840 亿请求,平均处理高峰次数能达到?150 万 TPS,平均响应时间要求小于 10 毫秒。因为涂鸦是物联网行业,区别于传统行业,没有低峰点,写入量非常大,涂鸦用六年的时间不断选型尝试,探索最合适的数据架构。

AWS Aurora

Apache Ignite

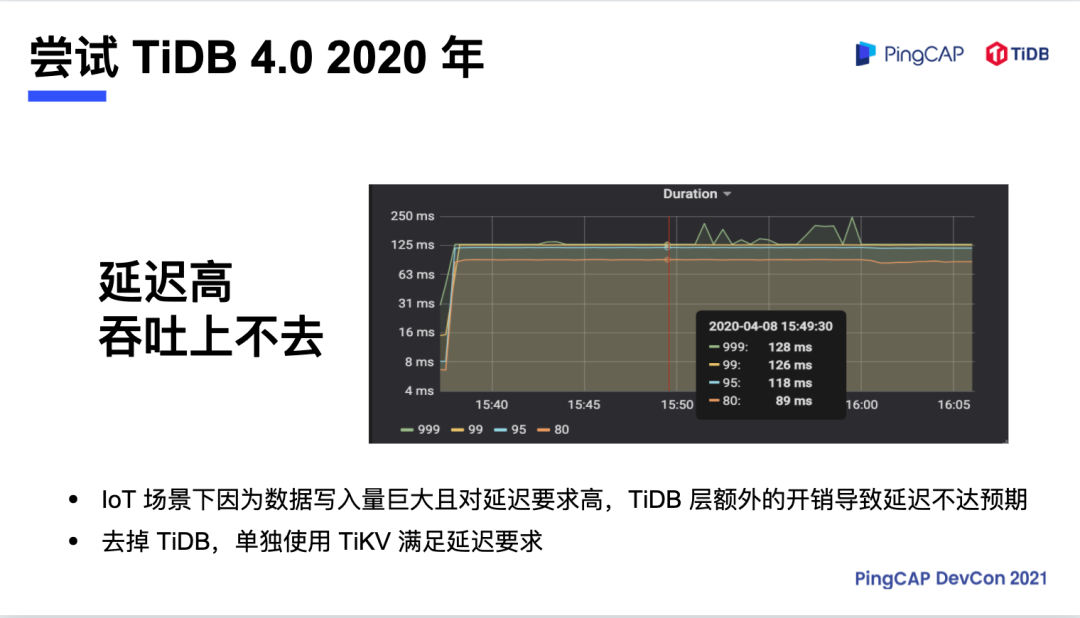
TiDB 3.0 和 4.0
新的挑战:跨区域部署

降本增效:从 X86 到 ARM 的架构升级
IoT 行业之所以注重降低成本,因为 IoT 行业的毛利率非常低,我们需要降低每一件模组的成本。在 2020 年 6 月,AWS 推出了 C6G 的产品,性价比宣称比上一代 C5 高出 40%,于是我们对 AWS 的 C6G 进行了尝试,但用 TiUP 编译直接部署的时候发现响应时间比 X86 架构慢 6 到 7 倍,即 TiUP 部署的是通用编译版本,跟硬件不是那么贴切。经过测试验证,发现现有的 TiKV 版本不支持 SSE 指令集,也就是说目前 TiKV 4.0 使用的 RocksDB 版本是不支持 SSE 指令集的。
业务展望
未来借助?TiDB 5.0 和 5.1,涂鸦有信心能够承接数倍的业务增长,预计年底 TiKV 的流量又会翻到现在的三到四倍。大数据平台也用了 TiDB 作为大屏展示,并且物联网的设备流水也正在考虑使用 TiKV 5.1 作为存储,更大程度上提高易用性,TiDB ARM 版本的部署也在下半年的规划之中。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 PingCAP
PingCAP
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675