
企业BI项目落地最佳实践
今天做个有数BI项目实践分享,我们可以从项目阶段去思考BI的项目建设。这里将分成三个阶段分别为:
"落地前",最常见的4件事情:业务切割;数据选型;流程规范;和上游系统账号、权限体系打通;
"落地中",聚焦一些细节,以及规范落地问题;
"落地后",需要聚焦数据监控,监控分为资源监控,安全监控,使用规范监控。
下面将具体介绍。
落地前:业务切割
在有数BI中有域,项目,文件夹等概念。如下图:
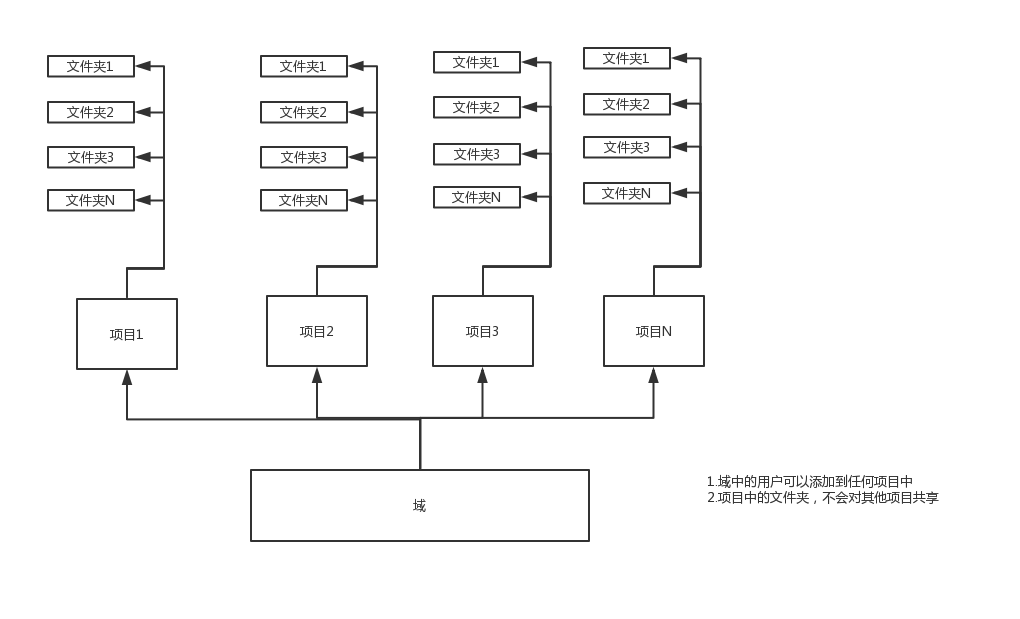
我们需充分利用当前概念,对业务模块切割。项目概念可以和数仓设计的主题一样。项目创建可以按照公司职能部门切割,也可以按照业务逻辑切割。在一个域中项目的切割也可以是混和型。
举个例子:电商公司的组织结构
按职能分:

如BI部门按照业务逻辑分:
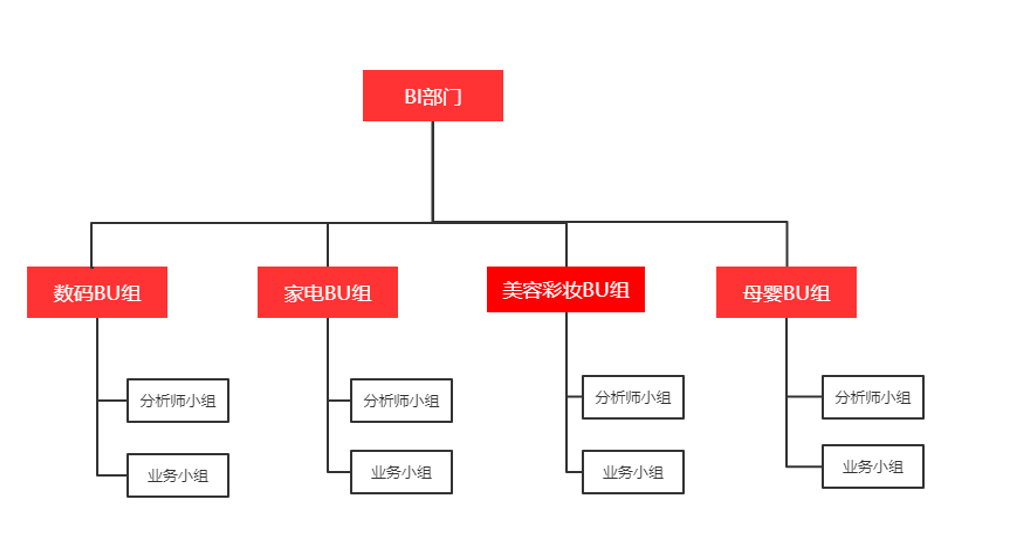
在当前情况下用,如果业务具有独立性,且单模块业务量大,也可以用项目隔离。所以个人喜欢采用混和模式,对于不同部门用项目隔离,但对于BI部门数据需求较大,可以对BI部门以业务模块创建不同项目。同时对于业务模块下存在细分业务可以用文件夹切分。如果业务分支很细,可以用文件夹层级区分。
落地前:数据选型
数据选型原则:适合自己业务的才是最好的。一般面对成熟的中大型BI项目基本没有数据选型余地。因为一般只需对接数仓的应用层或者BI层。但是如果从数仓设计和BI设计都是你自己。如果希望在BI中做大数据量的分析。如果你的业务部门要求高并发高性能,那就可以用Kylin和Druid,这两个都是预计算的套路,你给他设定好分析路线,kylin建CUBE,Druid做各种group by的计算,业务部门分析的时候就等于是直接查询已经计算好的结果。速度和并发量的表现都非常棒。缺点是吃存储,分析路径比较死,加一个维度得改模型。如果你的业务部门人不多,就内部用,但是比较挑剔,要非常高的自由度,那就可以用ClickHouse。这几种数据源在网易内部的音乐,传媒,教育等部门普遍使用。
落地前:流程规范
流程规范主要有资源创建规范,命名规范,权限分配规范。
1.资源创建规范:上面讲到的业务切割,也是一种资源创建规范的一种。在有数BI的项目中资源有数据连接,数据模型,报告。对于这些创建原则尽量用文件夹隔离,业务细分用子文件夹。对于一些公共业务模块可以见公共文件夹块。
2.命名规则规范:要做到顾名思义。在资源创建的时候,首先面临的是命名规范。
(1)资源创建命名规范:对于一些小型主题分析,尽量数据连接、模型、报告的文件夹命名保持一致。如图所示:

如果在小型主题分析中有多个细分业务。由于数据连接支持1级文件夹,数据模型和报告支持多级文件夹创建。所以命名规范如下:
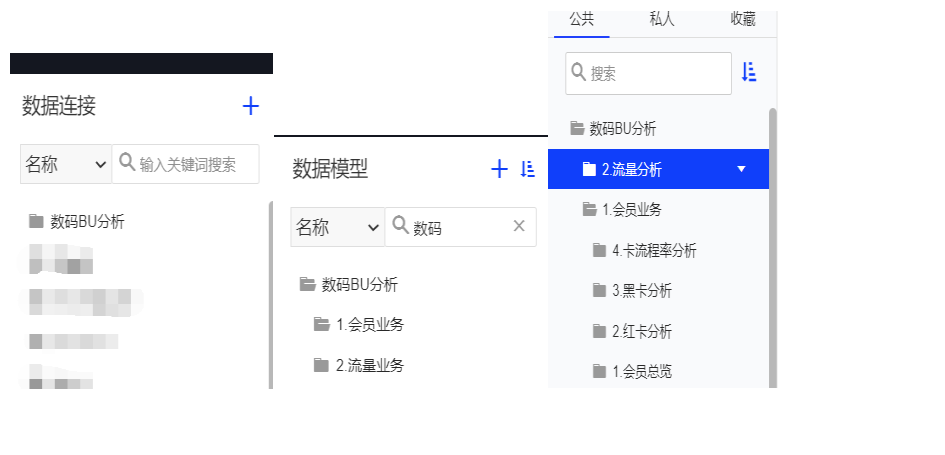
为什么命名规则不采用:如一级业务-二级业务-具体业务-创建日期-创建人 这样的方式命名?原因有两个:
逻辑虽然清晰,但是命名规范复杂。用文件分级形式有交互;
对于创建人,创建日期等信息可以通过后台监控方式获得,所以可以不用需要在命名中体现。
(2)字段(指标)命名规范:在BI项目中也非常重要,可以参考数仓设计字段命名规范。但是通常在大型项目中如果存在主题交叉的时候,但又要防止烟囱式开发,指标的复用是很突出的问题。

具体如何对指标进行管理,这里推荐一门课程,由郭忆老师在极客时间的《数据中台实践》。该课程在第五章具体介绍了指标管理的方法。
3.权限分配规范。如果在中大型企业中简单的权限分配往往满足不了需求。我们需要采用权限分级策略。系统内部权限设计如下:
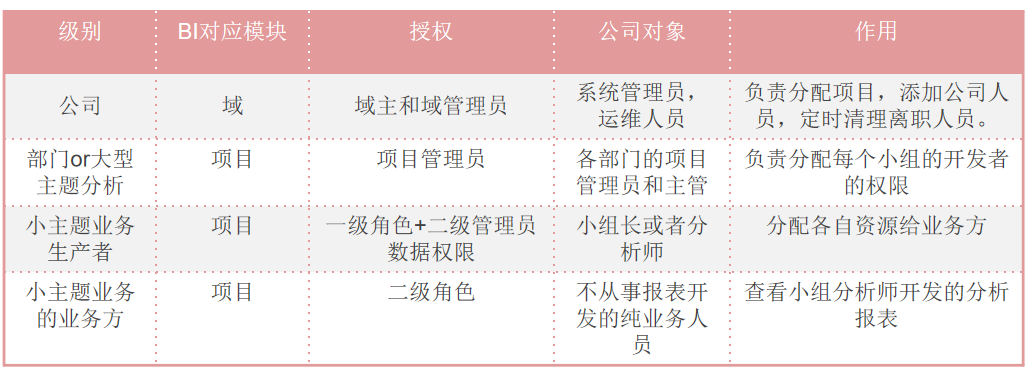
对于小主题业务生产者或者业务方。一般授予的是一级或者二级权限,以及数据权限。
所以命名规则主要是针对一级角色和二级角色以及数据权限的命名。
(1)角色权限命名规则:级别_文件夹名_团队_权限
如:一级角色_数据BU分析_数据分析师_编辑
(2)数据权限命名规范 数据链接名称_表_字段
如:超市系统_订单表_地区
落地前:和上游系统账号体系以及权限体系打通
有数BI可以通过单点登录方式同步账号体系,目前可以通过tokenlogin 方式;客户提供标准接口方式;以及我们开发页面的方式。当前方案已经非常成熟。对于上游系统的权限集成,我们外放多种创建权限接口。
落地中:聚焦细节
1.数据连接,如果在一个项目中业务较多,要考虑数据连接的复用性;同时对于数据权限的限制,优先考虑通过数据连接中的用户权限来控制。而不是用有数BI的权限控制。举个例子:如一个公司的重点业务数据都存在某一数据库下面,那么不同部门,不同团队关注的表是不一样的。此时建议先在数据库中创建用户。通过用户来控制业务范围。

如上图,我们可以创建3个数据连接,分别授予不同部门的同事。而对于同一部门同事关注的不同表可以通过有数BI模型层面权限来控制。
2.数据模型,(1)和数据连接一样要考虑到复用性。(2)数据建模可以通过多表的关联实现复杂建模,但是实现不等于最优实践。BI数据建模一般一个模型中建议不超过5个表关联。这个主要出于后期维护考虑。如果存在特殊场景,需要10几张表做可视化建模,建议用自定义sql 先把一些复杂的逻辑在自定义sql完成。用自定义sql在可视区域建模。数据模型最后是以宽表展示,理论上一个宽表字段不要超过30个,以服务客户的经验来说,一般模型层字段在报告上使用在5-30个之间。这里也要说一下性能,性能提升有很多种方式,最笨的方法就是在每个细节部分都注意到。对于不需要用到的字段尽量的不要在宽表中展示,这也是复杂场景下,推荐用自定义sql的原因。对于数据层面,可用范围要极尽缩减,做到用多少取多少。举个例子:如果你要分析本月的订单数据,但实际上提供的表是所有订单数据。此时建议在模型层对数据进行缩减。
3.报告,是BI的核心,一句话总结:报告是一个商业产出可以用价值衡量,所以要看性价比,因此大方向上需要做到4点。
做报告的人需要大局观。举个例子:某天老板需要看一下需要看本月的销售额,以便下月做战略调整。小明接到需求把不同渠道的业务进行精确核算。最后花了20天的时间把报告实现。虽然已经做完了,但是已经失去战略决策意义了。结论:不同人看数的角度不一样,也许有些数据是允许有误差的,提供范围即可。要站在他人角度思考。
做报告的人需要灵活变通。举个例子:小张是社区运营,需要统计用户活跃度。小张分析了本周的活跃度,还想看历史趋势情况。为了保证模型复用性,把两种分析行为都放在一个模型中。导致整张报告的性能不理想。虽然功能实现了,但是性能不好。针对当前例子,我们需要思考本周活跃度是一个高频查看行为,对于历史趋势是一个低频行为。
做报告的人需要边界明确。举个例子:小赵是一个做报告高手,技能专业非常过关,经常把一些数仓的工作在报告上实现。由于报告上逻辑太多,所以性能不理想。因此这里我想说的是,什么样的事情在什么阶段做最优,我们应该保障最优路线。
做报告的人需要适当的拒绝需求。如果完成10个需求只需1天,但是完成11个需求,需要3天。如果额外的1个需求不是刚需,我们应该学会拒绝。
以上4点是我对报告大方向上的理解。对于小方向上报告需要技能上配合。我们需要知道报告实质是sql,所以对报告的优化就是对sql的优化。基于对有数BI,有5条建议。
1个报告的模型尽量不要超过10个。如果超出,可以考虑分报告实现,模型尽量复用。
报告是加载当前页面的组件,所以一个报告页组件不要超过20个。能分报告页,尽量不要用tab页组件。
筛选器等组件尽量不要用数据量较大的数据模型。建议用维表。
对于开发阶段建议把报告放在私人文件夹下开发。等报告验证完成复制到公共区域。
对于离线分析报告,建议做预加载处理。
落地后:需要做好数据监控
数据监控分为资源监控、安全监控、使用规范监控。数据监控的目的是为了节省成本和提前预警,保证数据安全,规范使用流程。下图为监控体系构建示例。

好啦,本期的分享就到这里,下期将以售后部门为例,用有数BI实现部门全链路数据化。谢谢大家!
作者简介:千鱼,目前主要负责有数BI售后工作。由于长期服务不同行业客户,对客户产品使用的痛点非常了解。同时面对各种客户的复杂业务场景,有着非常丰富的解决经验。
转自:网易有数?公众号;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675