
TiDB 慢日志在伴鱼的实践
作者简介
刘江,伴鱼英语数据库负责人,TUG 2020 年度 MOA。负责伴鱼数据库运维、大数据运维以及数据库平台化建设。
本文来自于伴鱼英语 DBA 组负责人刘江在「能量钛」第二期活动的分享,刘江为大家分享了 TiDB 慢日志在伴鱼的实践。本文将从以下三个方面展开:
第一部分是背景与需求,首先介绍伴鱼做 TiDB 慢日志系统的背景,以及基于这个背景,要把慢日志系统做成什么样子; 第二部分介绍下慢日志系统具体是怎么做的;
第三部分通过几个线上案例,看看慢日志系统是如何定位线上问题的。
背景与需求
今年上半年,阿里云发布了新一代 DAS(数据库自治服务)服务,里面谈到数据库的问题,90% 以上的问题都是来源于数据库的异常请求。其实在我们日常的数据库问题场景,大部分的问题也都是异常 SQL 请求,像数据库的 bug 或者是机器导致的故障问题,平时遇到还是相对较少的。对于异常 SQL 的定位,数据库的慢日志分析,是一种特别有效的手段。
那么我们在平时利用慢日志分析问题的时候,会有哪些痛点?在做慢日志系统之前,集群的慢日志是分布在多台机器上面的,如果数据库出现了问题,就需要登录到多台机器一台台的去分析,问题处理的效率很低。特别是当集群规模特别大的时候,基本上没办法去快速定位问题。
当然,TiDB 在 4.0 版本支持了 Dashboard,我们可以通过 Dashboard 查看整个集群的慢日志信息,比如最近 15 分钟的或者最近半个小时的慢日志。但当系统真正出现问题的时候,慢日志会特别多,Dashboard 会面临计算加载等性能问题,同时 Dashboard 不支持检索和分析统计,这不利于我们快速定位到异常 SQL。
TiDB 系统库自带了一张表(INFORMATION_SCHEMA.SLOW_QUERY)来实时存储慢日志,我们也可以通过它来定位异常SQL,但这张表是一个关系型的表,本身是没有索引的,当日志量特别大的时候,多维检索和分析是特别慢的。同时,对于关系型表的多维检索和分析统计,也不是它所擅长的。
基于以上的痛点,伴鱼的慢日志系统需要满足以下几个需求:
首先,就是慢日志集中式收集,能够把线上多个集群甚至几十个集群的慢日志全部收拢在一起,便于集中分析,这样做入口就统一了。
其次,要保证收集的慢日志是准实时的。因为如果收集的慢日志延迟太大的话,对于处理线上问题和分析问题是没有帮助的。
然后,慢日志可以检索和统计分析。因为当出现问题的时候慢日志是特别多的,这个时候如果能够检索和统计分析的话,就可以快速定位到异常 SQL。
最后,慢日志系统需要支持监控和告警。
系统详解
基于以上的背景和需求,我们来看一下伴鱼的慢日志系统是怎么做的。
系统架构
伴鱼慢日志系统整体架构,如下图所示。我们在 TiDB Server 机器初始化时部署了 Filebeat 组件,通过它把采集的慢日志,写入到 Kafka,同时打上机器 IP 信息。然后通过 logstash 解析出我们关注的字段,存储到 ES。ES 本身是一个搜索引擎,做数据的分析和统计,速度是特别快的。同时我们通过 Kibana 查看 ES 里的慢日志数据,做可视化的统计和检索。
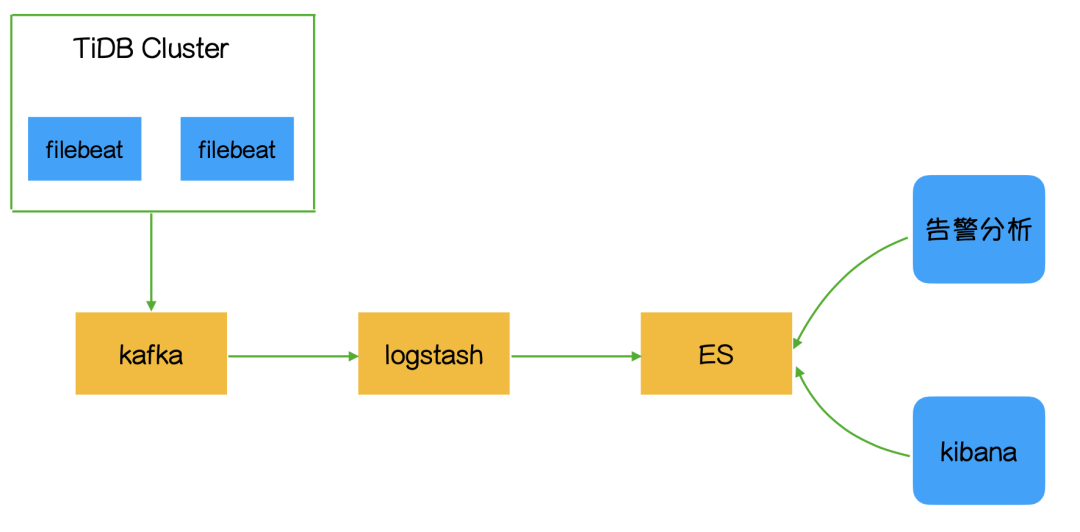
因为伴鱼的慢日志系统做得比较早,所以采用的是 ELK 的架构。
首先,Filebeat 足够轻量。我们在线上对几百兆文件做过解析测试,结论是对数据库的性能基本上没有影响。
其次,当线上出现问题时,瞬时的日志量是特别大的,如果把慢日志直接写入到 Logstash,会对 Logstash 机器负载造成冲击,所以通过 Kafka 来消峰。
当 Logstash 解析慢日志的时候,应尽量少用模糊匹配的规则。因为用模糊匹配的规则去解析慢日志,会导致机器 CPU 飙高的问题。
然后,ES 索引本身就是 Schema Free 的,然后加上倒排索引这种数据结构,这种特性非常适合统计分析类场景。
同时,通过 Kibana 做可视化检索和统计分析。
最后,我们每 2 分钟读取一次 ES 的慢日志数据,做监控报警。
日志采集
接下来看一下每个组件的细节,左边是 Filebeat 采集的配置,如下图所示。我们在部署 Filebeat 的时候,会把部署机器的 IP 给传进去,这样在后期统计的时候,就知道慢日志是来源于哪台机器。然后右边是 Kafka 的配置,数据收集好之后,会发送到 Kafka 集群。

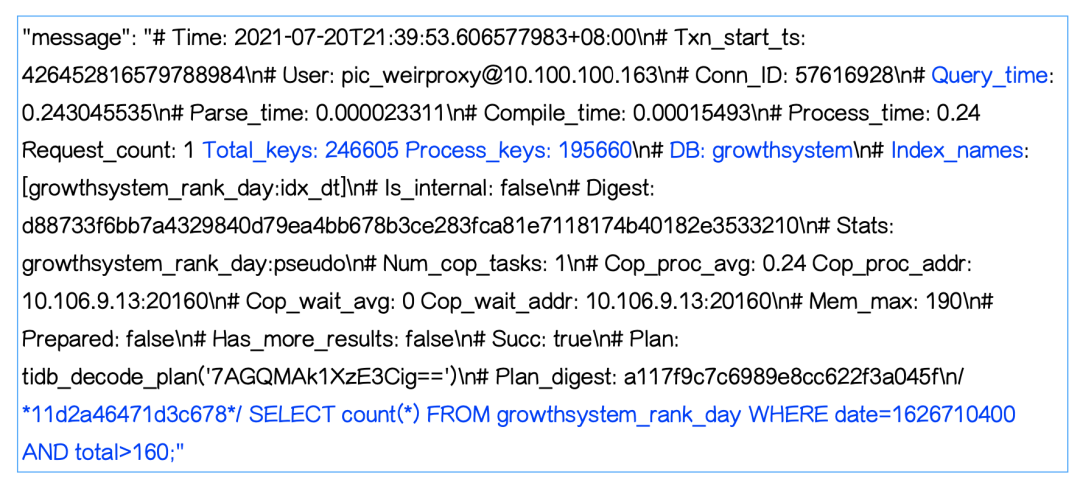
下面是一条 TiDB 慢日志的示例,格式是这样的。

字段筛选
一条文本没法做统计分析和多维检索的,如果我们要做,就需要把这行文本里面的字段解析出来,那么我们关注哪些字段呢?首先来看一下 MySQL 5.7 的慢日志,如下图所示。我们在处理 MySQL 故障的时候,首先会看一条 SQL 的查询时间,如果该 SQL 查询时间比较长,我们认为它可能会是导致线上问题的原因。

但是当线上请求量比较大的时候,查询时间长并不能代表它就是引发问题的根本原因,还要结合其它关键字段来综合分析。比如慢日志里一个特别重要的关键字 Rows_examined,Rows_examined 代表了数据逻辑扫描的行数,通常我们通过 Query_time 和 Rows_examined 综合分析,才可以定位问题 SQL。
接下来,我们看一下 TiDB 的慢日志。首先来看一下 TiDB 3.0.13 走 KV 接口的慢日志,如下图所示。这里有一些比较重要的关键字,比如说 Query_time,DB,SQL 和 Prewrite_time,这些关键字对于定位线上问题是很有帮助的。
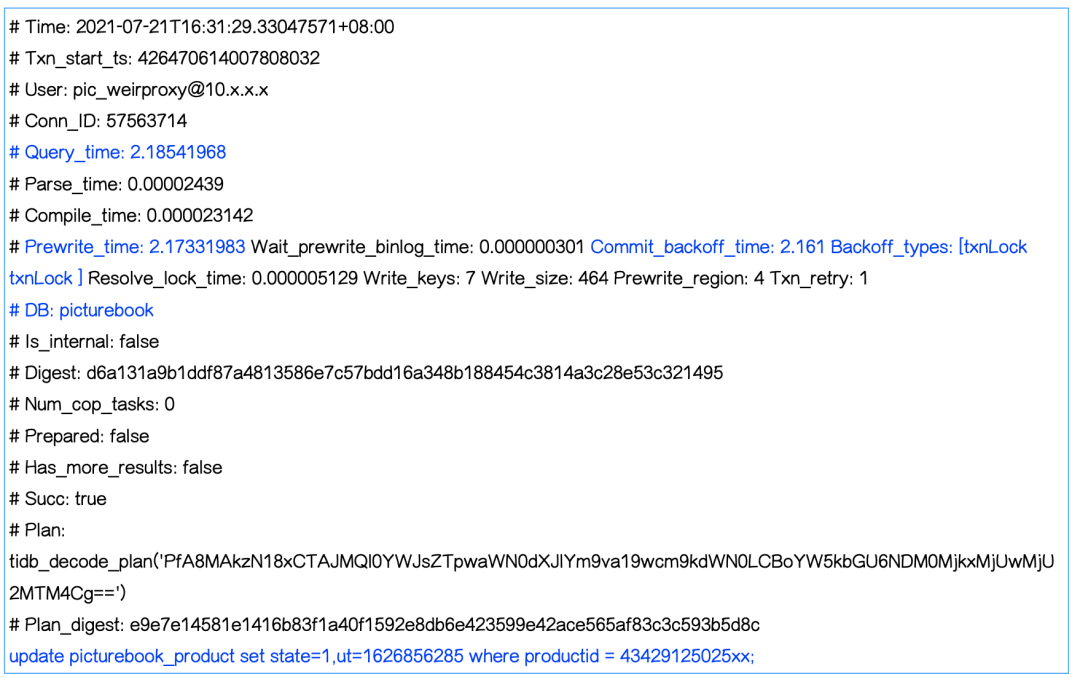
下面是另外一种格式的 TiDB 3.0.13 的慢日志,它是走 DistSQL 接口的,如下图所示。
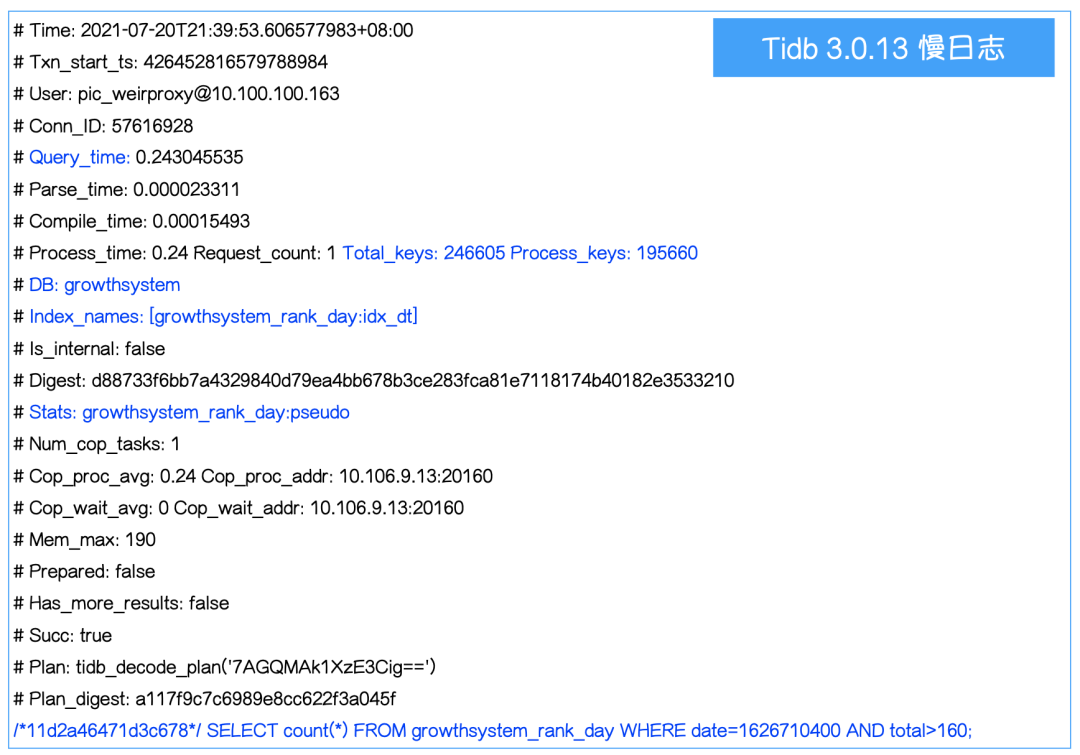
它除了把 Query_time、Total_keys 同时打印出来之后,还有 Index_names,代表这条 SQL 有没有走索引,同时 Index_names 字段里面还有表名等信息。
看完了 TiDB 3.0.13 的慢日志,我们再来看一下 TiDB 4.0.13 的慢日志,慢日志内容相比 TiDB 3.0.13 版本又增加了一些字段,比如 KV_total,PD_total,Backoff_total 等信息。

通过上面的慢日志,我们可以发现其中包含了很多关键信息,我们甚至可以看到请求慢在数据库的哪个环节。如果我们把慢日志收集起来,通过某些关系进行检索,甚至聚合,对于发现问题是很有帮助的。
TiDB IP:在部署 Filebeat 的时候,会把机器的 IP 给传进去。有了这个 IP,我们可以知道日志的来源以及按照 IP 的维度进行统计;
DB:执行语句时使用的 DATABASE。我们可以按照 DB 维度进行统计,同时也可以通过内部系统将 DB 和具体的数据库集群映射起来;
TABLE:有些慢日志是可以解析出表名的,可按照表的维度进行统计;
IDX_NAME:除 Insert 语句 和走 KV 接口的语句外,慢日志信息记录了语句有没有走索引;
TOTAL_KEYS:Coprocessor 扫过的 Key 的数量;
PROCESS_KEYS:Coprocessor 处理的 Key 的数量;
QUERY_TIME:语句执行的时间;
SQL:具体的 SQL 语句。
字段解析
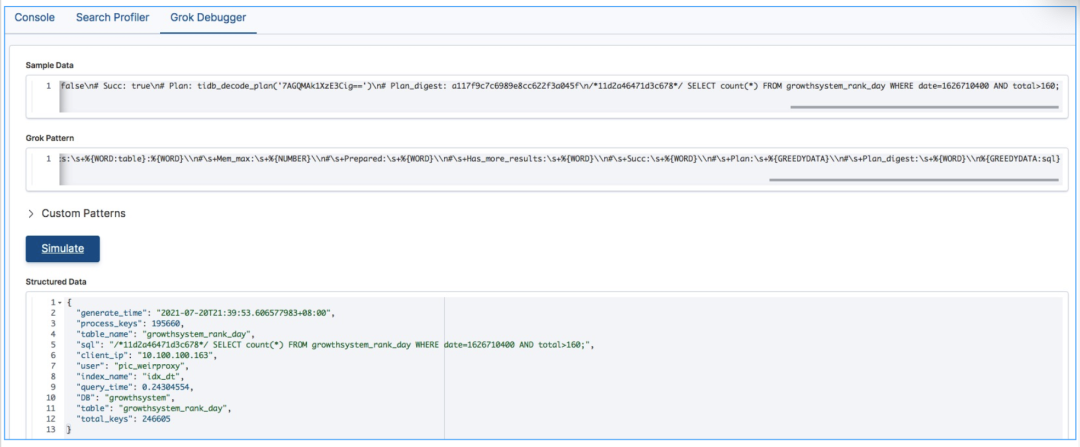
统计分析
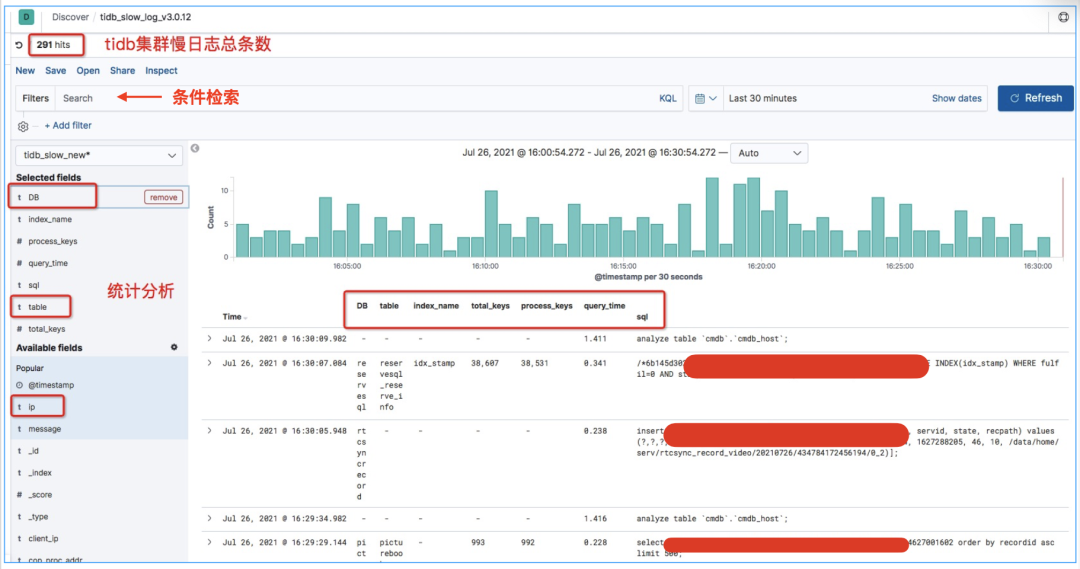
下面这个图是我们所有集群在最近 30 分钟之内的慢日志情况。我们通过 Kibana,可以看到慢日志的总条数,可以通过 DB、Quwry_time、Total_keys 来进行检索,还可以按 DB、Table、IP 等维度进行统计。这样能够极大地提高定位问题 SQL 的效率。

监控告警
但是我们发现线上也存在执行频率特别低,但是执行时间特别长的情况,就没办法通过通用的规则去覆盖。所以后面又加了一条规则:执行时间超过 500 毫秒,告警阀值达到 2 条就告警。这样对于线上的慢 SQL 就基本上全覆盖了。


案例分享
讲完了慢日志系统是怎么做的,接下来看一下我们是如何通过慢日志系统去发现线上问题。
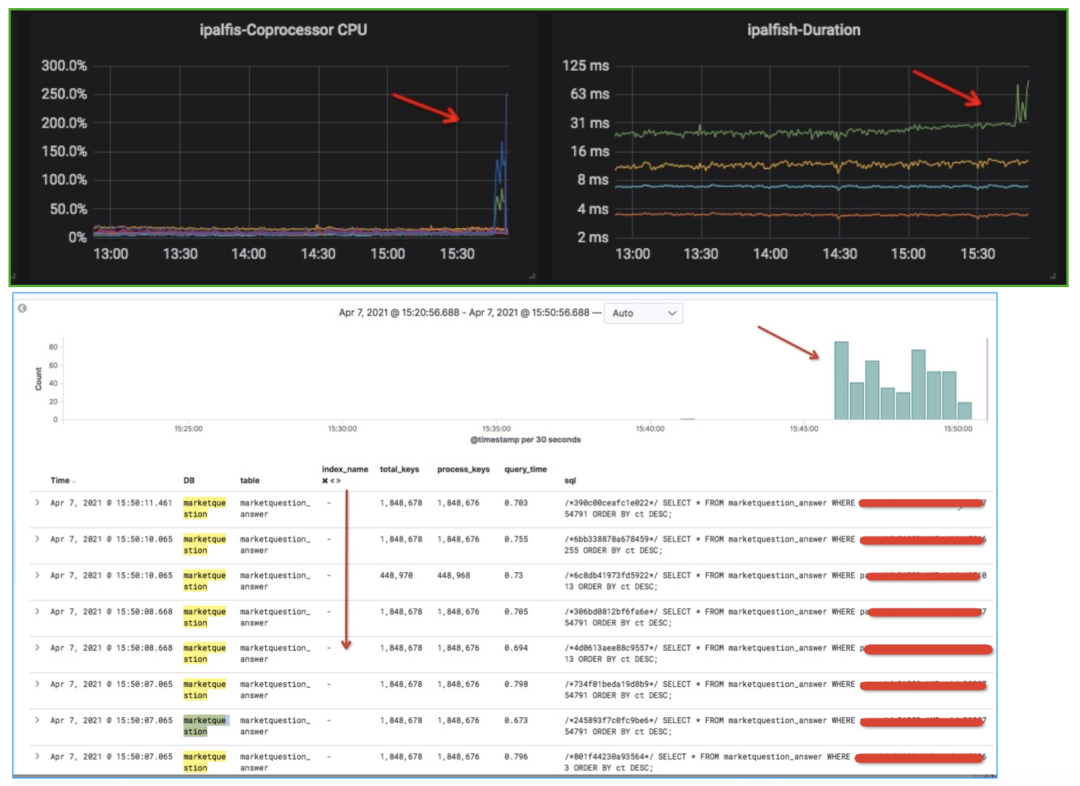
第一个案例,如下图所示。我们在某天发现集群的 Coprocessor CPU 上去了,同时对应着右边的延时也上去了,通过慢日志系统很快就能发现问题 SQL,它的 Total_keys 和 Process_keys 耗得比较多,另外它的 index_name 是空的,说明它没有走到索引。我们通过给这条 SQL 加上索引,性能问题就快速地解决了。

总结
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 PingCAP
PingCAP
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675