
Google Research吐嘈tensorflow!TF-Ranking迎来大更新:兼容Keras更容易开发

??新智元报道??
??新智元报道??
来源:Google AI
编辑:LRS
【新智元导读】Github 2200星,备受好评的排序库tensorflow ranking最近又迎来大更新:新的架构,支持更多Tensor库!尤其是Keras,官方直言:用Keras可以让开发人员更方便地开发和部署。
Google Research出品的排序模型(LTR, learning-to-rank)库又迎来大更新,这次兼容Keras了和其他常见的tensor库,官方说:这会让用户更容易开发和部署!
?
2018年12月时,Google推出一个基于 tensorflow 的开放源代码库TF-Ranking,主要用于开发可扩展的神经网络LTR模型。给定一个用户查询(query),LTR模型可以根据这个查询在全部条目中搜索并返回一个有序列表。
?

?
LTR 模型与标准的分类模型不同,标准的分类模型一次只对一个条目(item)进行分类,LTR 模型接收一个完整的条目列表作为输入,并学习一个排序算法,使整个列表的效用(utility)最大化。
?
虽然搜索和推荐系统是 LTR 模型最常见的应用,但是自从TF-Ranking发布以来,它也被广泛应用于搜索之外的各种领域,包括电子商务(e-commerce)、 SAT 解算器和智能城市规划。
?

?
在2021年5月,Google对 TF-Ranking 发布一次大更新,开始支持使用 Keras (TensorFlow 2的一个高级 API)本地构建 LTR 模型。
?
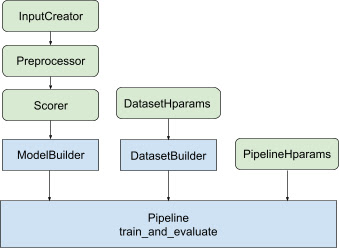
原生 Keras 的排序模型有一个全新的工作流设计,包括一个灵活的 ModelBuilder、一个用于设置训练数据的 DatasetBuilder 和一个用于使用所提供的数据集训练模型的 Pipeline。
?
?
这些组件使得更方便地构建定制的 LTR 模型,并且有助于快速探索用于生产和研究的新模型结构。
?
即便是 Ragget Tensors 的忠实用户,现在TF-Ranking 现在也可以兼容。
?
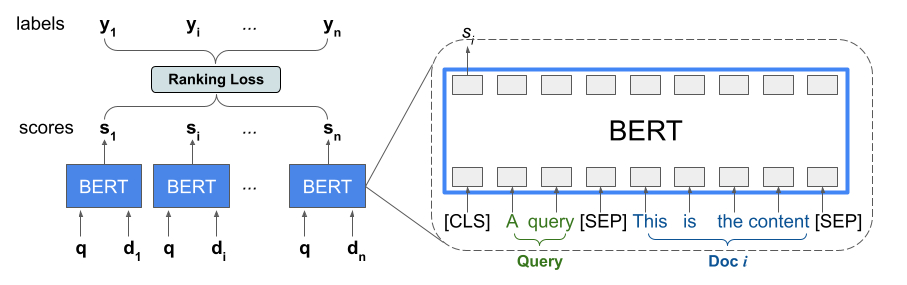
自BERT横空出世之后,像 BERT 这样经过预训练的语言模型已经在各种语言理解任务上取得了最好的成绩。为了捕捉这些模型的表达能力,TF-Ranking 实现了一种新颖的 TFR-BERT 体系结构,该体系结构将 BERT 与 LTR 的能力结合起来,可以用来优化列表输入的顺序。
?
考虑一个查询和一个应该查询的 n 个文档的列表。LTR 模型没有为每个 < query,document > ?pair 学习一个独立的 BERT 表示,而是应用一个排序损失来共同学习一个 BERT 表示,这个 BERT 表示最大化了整个排序列表相对于真实标签(ground truth)的作用。
?
首先,将响应查询的 n 个文档的列表合并为一个列表 < query,document > 元组,把这些元组输入到一个预训练的语言模型(如,BERT)。
?
然后对整个文档列表的合并 BERT 输出与 TF-Ranking 中可用的一个专门的排名损失进行联合微调。
?
?
经验和实验结果表明,这个 TFR-BERT 架构能够对预训练语言模型性能有重大改进,并在几个常见的排序任务中取得sota性能。如果是多个预训练语言模型集成起来,性能提升更加明显。
?
透明性和可解释性在确定贷款资格评估、广告定位或指导医疗决策等LTR模型开发中是非常重要的因素。在这些情况下,每个特征对最终排名的贡献应该是可以检验和理解的,以确保结果的透明度、可问责(accountability)和公平性。
?
想要实现这一点,一个可用的方法是广义加性模型(Generalized Additive Models, GAMs),它本质上可解释的机器学习模型,该模型是由单个特征的光滑函数线性组成的。然而,尽管 GAMs 已经在回归和分类任务中得到了广泛的研究,但是如何在排名环境中应用它们还不是很清楚。
?
例如,GAMs 可以直接应用于为列表中的每个单独条目建模,但是为条目相互作用和这些条目排序的环境建模是一个更难的研究问题。
?
为此,Google开发了一个神经网络排序 GAM ーー可以将GAM用在排序问题上的扩展。
?

?
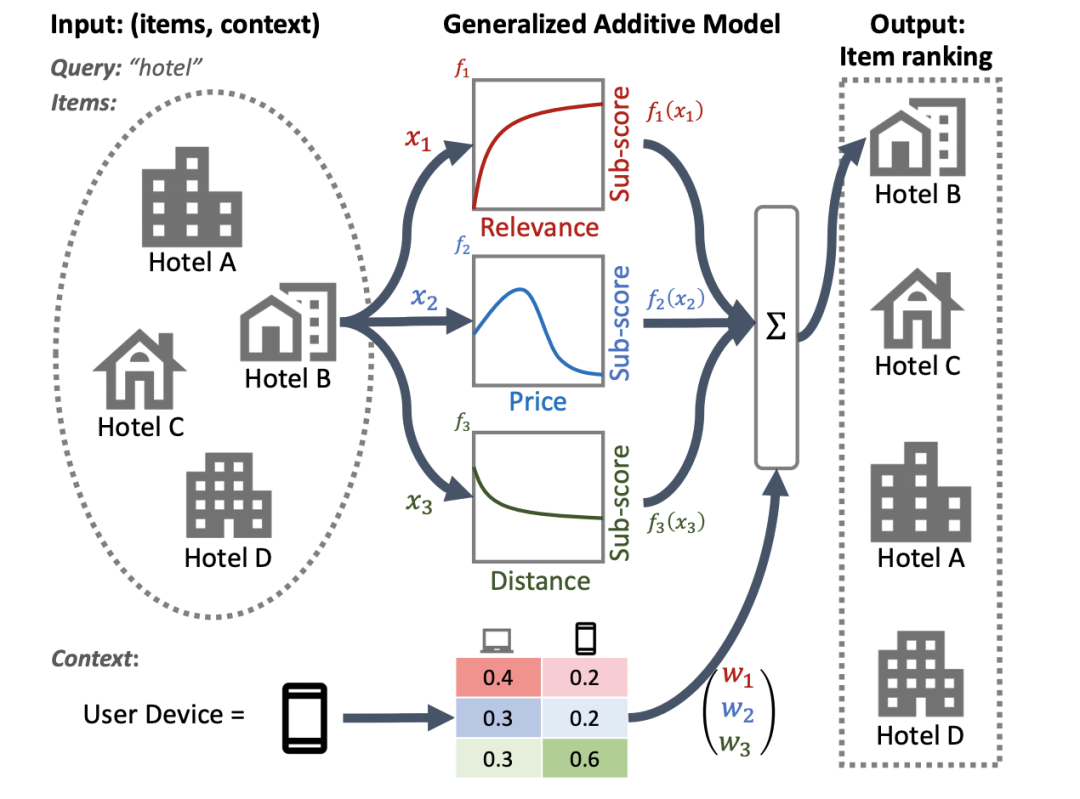
与标准的GAM不同,神经排序的GAM模型可以同时考虑被排序项目的特征和上下文特征(例如,query或user profile) ,从而得出一个可解释的、紧凑的模型。这不仅确保了每个条目级特征的贡献是可解释的,而且上下文特征的贡献也是可解释的。
?
例如,在下图中,使用神经网络排名的 GAM 可以看到距离、价格和相关性,在给定的用户设备上下文中,对酒店的最终排名有贡献。神经排序 GAM 现在可以作为 TF-Ranking 的一部分。
?
?
虽然神经模型已经在多个领域取得了最先进的性能,但是专门的梯度增强决策树(gradient boosted decision trees, GBDTs) ,如 LambdaMART,仍然是各种开放 LTR 数据集的基准。
?
GBDTs 在开放数据集中的成功有几个原因。首先,由于它们相对较小,神经模型容易对这些数据集过度拟合。其次,由于 GBDTs 使用决策树对其输入特征空间进行分区,它们自然更能适应排名数据中数值尺度的变化,这些数据通常包含 Zipfian 或其他倾斜分布的特征。然而,GBDTs 在更为现实的排名场景中确实有其局限性,这些场景通常同时结合了文本特性和数值特性。例如,GBDTs 不能直接应用于大型离散特征空间,如原始文档文本。一般而言,它们的可扩展性也不如神经排序模型。
?
自 TF-Ranking 版本发布以来,开发团队极大地加深了对如何最好地利用神经模型进行数值特征排序的理解。
?
并且在 ICLR 2021的一篇论文中描述了一个数据增强自我注意潜在交叉(Data Augmented Self-Attentive Latent Cross, DASALC)模型,这是第一个在开放的 LTR 数据集上建立奇偶校验的神经排序模型,在某些情况下有统计学意义上的显著改进。
?
这一改进包括一系列技术,如数据增强、神经特征转换、建模文档交互(document interaction)的自我注意力、列表排名损失(listwise ranking loss),以及类似于增强 GBDTs 的模型集合。DASALC 模型的体系结构完全使用 TF-Ranking 库实现。
?
最后,研究团队表示,基于Keras的TF-Ranking将更容易进行开发和部署LTR模型。(这是在暗示tensorflow不好用吗?)
?
TF-Ranking开发团队中包括许多华人,其中Honglei Zhuang以第一作者身份为TF-Ranking贡献多篇论文。他目前在 Google Research TF-Ranking团队工作,主要研究兴趣包括数据挖掘、机器学习和信息检索,具体的领域包括文本挖掘、异常检测/社交网络、众包和社交网络分析。在加入谷歌之前,他在伊利诺伊大学厄巴纳-香槟分校获得了博士学位,在清华大学获得了学士学位。
?

参考资料:
https://ai.googleblog.com/2021/07/advances-in-tf-ranking.html

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675