
2021数据科学就业市场最全分析:Python技能最重要,5到10年经验最吃香
分析了 3000 多个数据科学相关的岗位招聘内容,他们总结出了十点重要规律。

import pandas as pdimport numpy as npfrom selenium import webdriverfrom selenium.common.exceptions import NoSuchElementExceptionchromepath = r'D:\Drivers\Chrome Driver\chromedriver.exe'url_list = []for i in range(1, 50):print('Opening Search Pages ' + str(i))page_url = 'https://jobportalexample.com/data-scientist-jobs-'+str(i)driver = webdriver.Chrome(chromepath)driver.get(page_url)print('Accessing Webpage OK \n')url_elt = driver.find_elements_by_class_name("fw500")print('Success')for j in url_elt:url = j.get_attribute("href")url_list.append(url)driver.close()
为了简化此过程,URL 被保存为 pandas DataFrame。
url_list_copy_cleaned = [i for i in url_list]out_company_df = pd.DataFrame(url_list_copy_cleaned, columns=['Website'])out_company_df.head()

数据框
现在,变量 `url_list_copy_cleaned` 有超过 3000 个岗位 list 的 URL,下一步是点击所有 1000 页,提取详细信息。被抓取的信息包括企业、位置、经验、角色、技能。
jobs={'roles':[],'companies':[],'locations':[],'experience':[],'skills':[]}driver = webdriver.Chrome(chromepath)for url in out_company_df['Website']:driver.get(url)try:name_anchor = driver.find_element_by_class_name('pad-rt-8')name = name_anchor.textjobs['companies'].append(name)except NoSuchElementException:jobs['companies'].append(np.nan)try:role_anchor = driver.find_element_by_class_name('jd-header-title')role_name = role_anchor.textjobs['roles'].append(role_name)except NoSuchElementException:jobs['roles'].append(np.nan)try:location_anchor = driver.find_element_by_class_name('location')location_name = location_anchor.textjobs['locations'].append(location_name)except NoSuchElementException:jobs['locations'].append(np.nan)try:experience_anchor = driver.find_element_by_class_name('exp')experience = experience_anchor.textjobs['experience'].append(experience)except NoSuchElementException:jobs['experience'].append(np.nan)try:skills_anchor = driver.find_elements_by_class_name("chip")each_skill = []for skills in skills_anchor:each_skill.append(skills.text)jobs['skills'].append(each_skill)except NoSuchElementException:jobs['skills'].append(np.nan)driver.close()
需要注意 NoSuchElementException 错误。因为一些 URL 会直接跳到企业主页,而不是同一工作门户网站的另一个详细信息页面。在这种情况下,要寻找的 HTML 元素可能不存在,将引发错误。
为了更好地进行数据处理和预处理,最好将数据固化为 Pandas DataFrame。在完成所有预处理步骤之后,将清洗后的数据集带入 Tableau 以实现最佳可视化效果。(Tableau 是专注于商业智能的交互式数据可视化软件)

有数据科学家招聘需求的企业

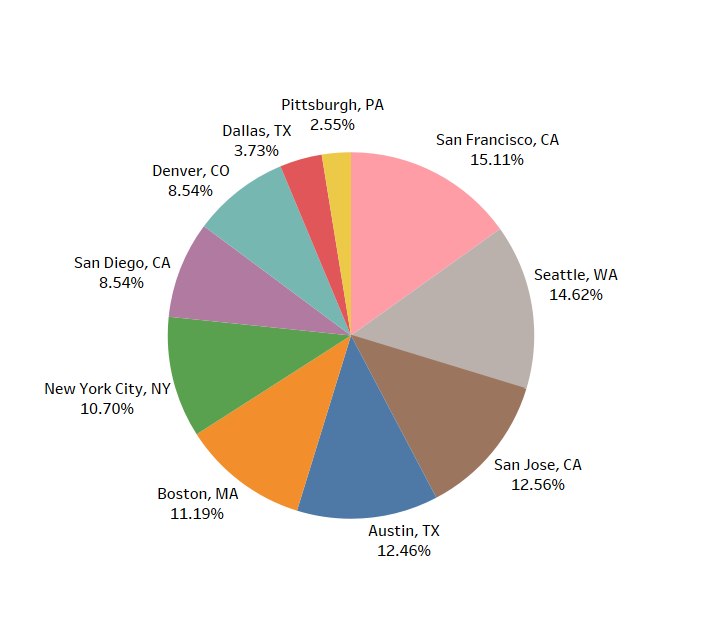
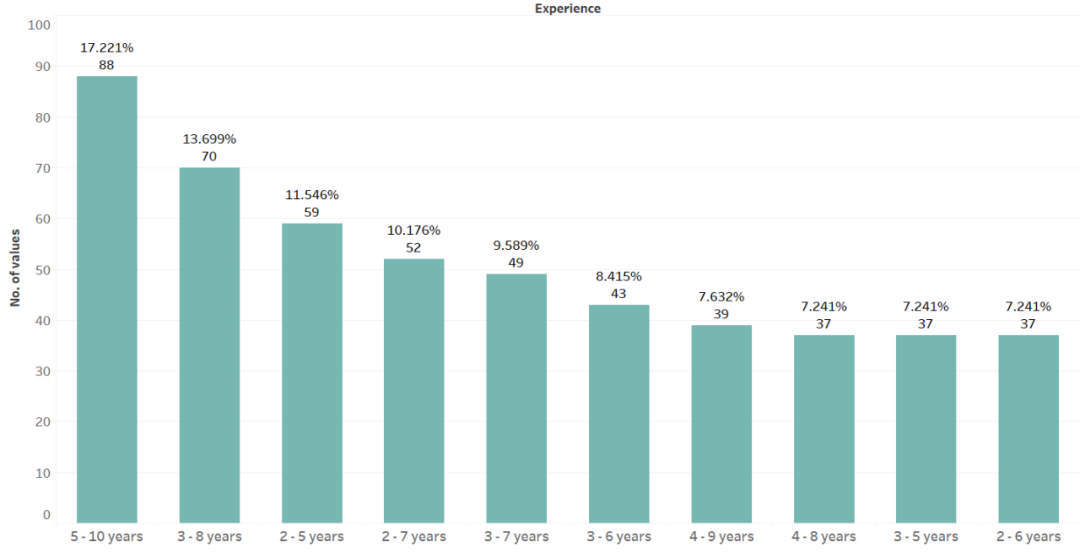




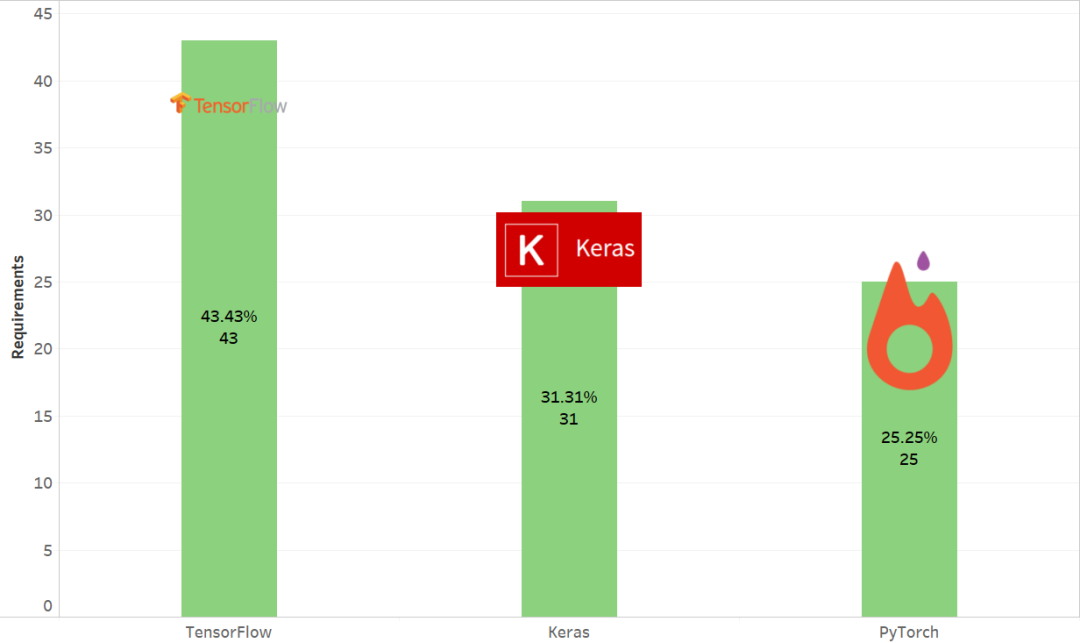
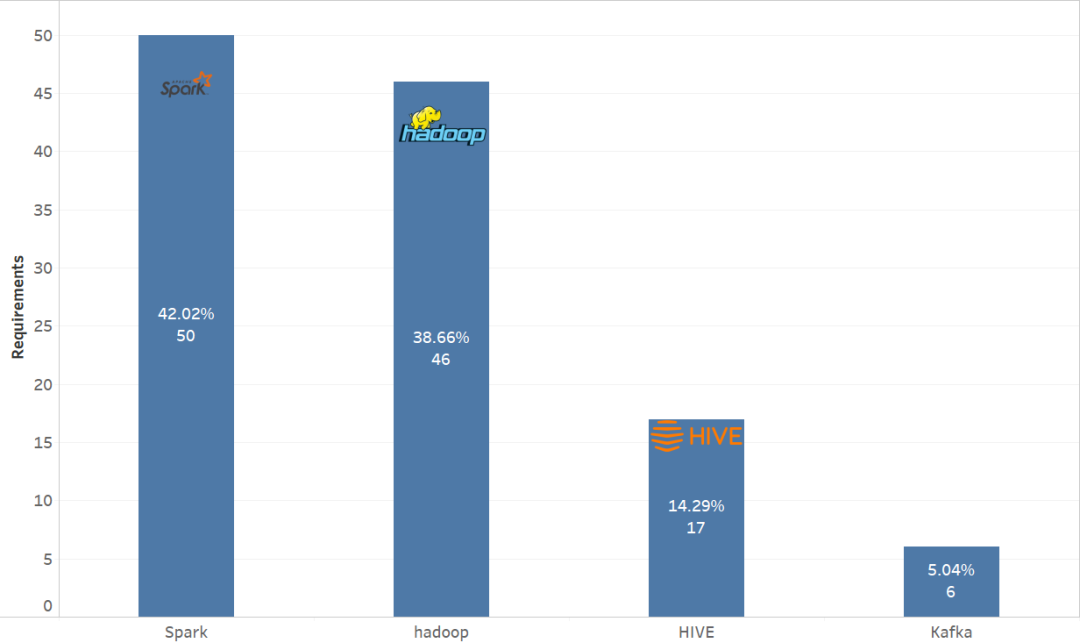

原文链接:
https://pub.towardsai.net/current-data-science-job-market-trend-analysis-future-4184f03a04ca
转自:机器之心;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
「完」
数据分析(ID :?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675