一文读懂丨AI芯片:未来将走向何方?

AI芯片基本知识及现状
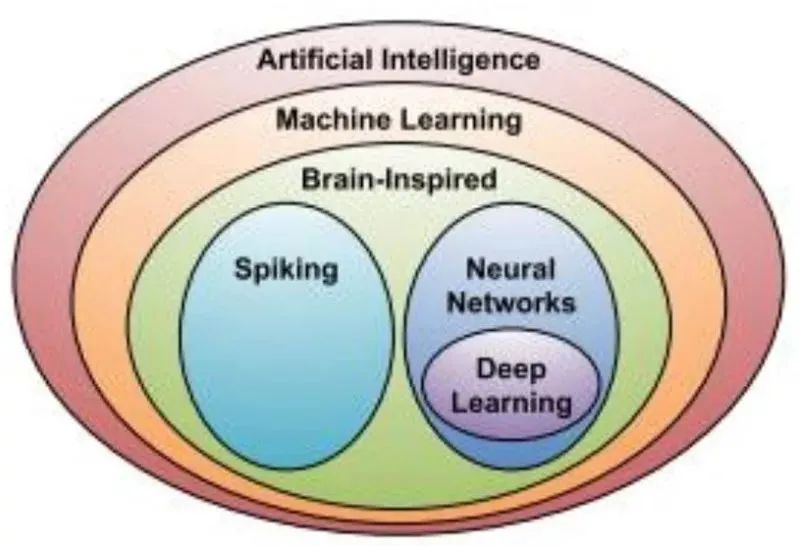



AI 芯片的分类及技术
1、传统 CPU

2、并行加速计算的 GPU
 ▲CPU 及 GPU 结构对比图(引用自 NVIDIA CUDA 文档)
▲CPU 及 GPU 结构对比图(引用自 NVIDIA CUDA 文档) ▲GPU 芯片的发展阶段
▲GPU 芯片的发展阶段 ▲FPGA 在人工智能领域的应用
▲FPGA 在人工智能领域的应用
趋势结论:短期内GPU仍将主导AI芯片市场,长期三大技术路线将并存。长期来看,GPU 主要方向是高级复杂算法和通用型人工智能平台,FPGA 未来在垂直行业有着较大的空间,ASIC 长远来看非常适用于人工智能,尤其是应对未来爆发的面向应用场景的定制化芯片需求。
AI芯片产业及趋势
1、AI芯片应用领域
随着人工智能芯片的持续发展,应用领域会随时间推移而不断向多维方向发展,这里我们选择目前发展比较集中的几个行业做相关的介绍。

2、AI芯片国内外代表性企业

3、技术趋势
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 中法友谊蕴山水 7904040
- 2 你以为的进口尖货 其实早已国产了 7808542
- 3 张荣恭:敢宣布“台独”大陆立刻动手 7713248
- 4 盘点2025大国重器新突破 7617557
- 5 中美合拍《我的哪吒与变形金刚》首播 7520942
- 6 “两人挑一担 养活半栋楼” 7426771
- 7 美军承认:击落美军战机 7327742
- 8 尖叫之夜直播 7233065
- 9 美国称将调整与中国经济关系 7141986
- 10 周末去哪玩?雪场“不打烊” 7045649