机器之心 & ArXiv Weekly Radiostation参与:杜伟、楚航、罗若天
本周的重要论文包括来自微软 Cloud+AI 部门的 DeepDebug,一种使用大型预训练模型 transformer 进行自动调试的方法;UC 伯克利等机构提出的 APPS(Automated Programming Progress Standard),一个代码生成基准,该基准测试能够衡量模型的代码生成能力,并检查代码是否符合问题要求等研究。
DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons?
Measuring Coding Challenge Competence With APPS
DeepViT: Towards Deeper Vision Transformer?
?ChoreoMaster: Choreography-Oriented Music-Driven Dance Synthesis
One-Shot Voice Conversion Based on Speaker Aware Module
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
ERNIE-Doc: A Retrospective Long-Document Modeling Transformer
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons 摘要:本地化 Bug 并修复程序是软件开发过程中的重要任务。在本篇论文中,来自微软 Cloud+AI 部门的研究者介绍了 DeepDebug,一种使用大型预训练模型 transformer 进行自动调试的方法。研究者基于 20 万个库中的函数训练了反向翻译模型。接下来,他们将注意力转向可以对其执行测试的 1 万个库,并在这些已经通过测试的库中创建所有函数的 bug 版本。这些丰富的调试信息,例如栈追踪和打印语句,可以用于微调已在原始源代码上预训练的模型。最后,研究者通过将上下文窗口扩展到 bug 函数本身外,并按优先级顺序添加一个由该函数的父类、导入、签名、文档字符串、方法主体组成的框架,从而增强了所有模型。在 QuixBugs 基准上,研究者将 bug 的修补总数增加了 50%以上,同时将误报率从 35%降至 5%,并将超时从 6 小时减少到 1 分钟。根据微软自己的可执行测试基准,此模型在不使用跟踪的情况下首次修复了 68%的 bug;而在添加跟踪之后,第一次尝试即可修复 75%的错误。
推荐:bug 的修补总数增加了 50%以上,误报率从 35%降至 5%,超时从 6 小时减少到 1 分钟。论文 2:Measuring Coding Challenge Competence With APPS摘要:随着深度学习的兴起,AI 让许多行业实现了自动化,包括将 AI 用于编程。人们在编程时通常会使用大量的有意识和潜意识思维机制发现新问题并探索不同的解决方案,然而大多数机器学习算法都需要定义明确的问题和大量带有注释的数据才能够开发出解决相同编程问题的模型,因此用 AI 编程并非易事。此外,准确地评估模型的代码生成性能可能是很困难的,并且很少有既灵活又严格的方式来评估代码生成的研究。基于此,来自 UC 伯克利等机构的研究者提出了 APPS(Automated Programming Progress Standard),一个代码生成基准,该基准测试能够衡量模型的代码生成能力,并检查代码是否符合问题要求。与公司评估候选软件开发人员的方式类似,该研究通过检查生成的代码在测试用例上的结果来评估模型。基准测试包括 10,000 个问题,包含单行代码解决的简单问题和具有大量代码的复杂算法挑战等多多种问题。上述 AI 生成代码示例在 APPS 数据集中被视为「面试级别」的问题。
论文 3:DeepViT: Towards Deeper Vision Transformer 摘要:视觉 transformer (ViT) 现已成功地应用于图像分类任务。近日,来自新加坡国立大学和字节跳动美国 AI Lab 的研究者表明,不同于卷积神经网络通过堆叠更多的卷积层来提高性能,ViT 的性能在扩展至更深时会迅速饱和。具体而言,研究者根据经验观察到,这种扩展困难是由注意力崩溃(attention collapse)引起的:随着 Transformer 加深,注意力图在某些层之后逐渐变得相似甚至几乎相同。换句话说,在 deep ViT 模型的顶层中,特征图趋于相同。这一事实表明,在更深层的 ViT 中,自注意力机制无法学习有效的表征学习概念,并且阻碍了模型获得预期的性能提升。基于以上观察,研究者提出了一种简单而有效的方法 Re-attention,它可以忽略计算和存储成本重新生成注意力图以增加其在不同层的多样性。借助于该方法,我们可以通过对现有 ViT 模型的微小修改来训练具有持续性能改进的更深的 ViT 模型。此外,当使用 32 个 transformer 块训练 DeepViT 模型时,在 ImageNet 数据集上实现了颇具竞争力的 Top-1 图像分类准确率。相较于 ViT-32B, 变体模型 DeepViT-32B 的 Top-1 准确率提升了 1.6%。
具有 N 个 transformer 块的原版 ViT 模型与该研究所提 DeepViT 模型的结构对比。
推荐:相较于 ViT-32B, 变体模型 DeepViT-32B 的 Top-1 图像分类准确率提升了 1.6%。论文 4:ChoreoMaster: Choreography-Oriented Music-Driven Dance Synthesis 摘要:舞蹈动画在游戏和影视行业已非常普遍,目前业内制作舞蹈动画大多采用的是手 K 或动捕,生产一段高质量的舞蹈动画依然需要耗费大量的时间和精力。因此 AI 合成舞蹈成为时下热门的研究课题。但舞蹈作为一种独立的艺术形式,其动作与配乐在风格、节奏和结构等方面无一不透露出编舞学的专业知识,想要稳定输出高质量的结果并非易事。尽管业界也曾出现过多项红极一时的研究成果,如 AI Choreographer 和 DanceNet3D,然而这些方案并未落地于实际商业生产应用。历经两年多的潜心研发,网易互娱 AI LAB 的研发团队提出了符合实际生产环境应用要求的 AI 舞蹈动画合成方案 ChoreoMaster。该方案的亮点在于:除了能够快速稳定地输出一段符合编舞美学、符合多种舞种风格、连贯自然的舞蹈动画以外,还灵活支持丰富的约束方式来指导算法按照用户期望的方向合成舞蹈动画,如可替换或删除指定片段、预设舞蹈轨迹和限制舞蹈范围等。
推荐:全球首个落地的舞蹈动画合成系统,入选 SIGGRAPH 2021。论文 5:One-Shot Voice Conversion Based on Speaker Aware Module摘要:语音转换(VC)是指在保证一句话内容不变的基础上,将原始语音中说话人音色迁移到目标说话人音色。语音转换在电影配音、角色模仿以及复刻人物音色等方面都有重要的应用。当前基于深度学习实现到特定目标说话人的语音转换已经取得很大的进步,例如基于 CycleGAN、VAE 以及 ASR 的语音转换方法都可以很好的实现到训练集内说话人的语音转换。然而,如果想要增加一个目标说话人音色,或者进行用户音色的自定义复刻,通常需要大量的说话人数据以重新训练一个以该说话人音色为目标音色语音转换模型,或者通过少量数据对现有模型进行自适应训练。实际应用中,数据库录制的周期和成本都比较高,而对于普通用户而言,也很难获得用户大量的语音数据。因此,小数据的语音转换成为亟待解决的热点问题。而来自快手负责音频技术研发部门 MMU 的研发人员提出了一种基于说话人感知模块(SAM)的单样本语音转换的解决方案。该方案仅通过说话人的单句语音样本提取用户的音色表征,就可以实现该说话人作为目标说话人音色的语音转换。
推荐:一句话复制你的音色,已被 ICASSP 2021 接收。论文 6:UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
摘要:大数据是深度学习取得成功的关键基础之一。当前的预训练方法,通常分别在各种不同模态数据上分别进行,难以同时支持各类语言和图像的任务。基于深度学习的 AI 系统是否也能像人一样同时学习各种单模、多模等异构模态数据呢?如果能够实现,无疑将进一步打开深度学习对大规模数据利用的边界,从而进一步提升 AI 系统的感知与认知的通用能力。为此,语言与视觉一体的模型 ERNIE-UNIMO 提出统一模态学习方法,同时使用单模文本、单模图像和多模图文对数据进行训练,学习文本和图像的统一语义表示,从而具备同时处理多种单模态和跨模态下游任务的能力。此方法的核心模块是一个 Transformer 网络,在具体训练过程中,文本、图像和图文对三种模态数据随机混合在一起,其中图像被转换为目标(object)序列,文本被转换为词(token)序列,图文对被转换为目标序列和词序列的拼接。统一模态学习对三种类型数据进行统一处理,在目标序列或者词序列上基于掩码预测进行自监督学习,并且基于图文对数据进行跨模态对比学习,从而实现图像与文本的统一表示学习。进一步的,这种联合学习方法也让文本知识和视觉知识互相增强,从而有效提升文本语义表示和视觉语义表示的能力。此方法在语言理解与生成、多模理解与生成,4 类场景、共 13 个任务上超越主流的文本预训练模型和多模预训练模型,同时登顶权威视觉问答榜单 VQA、文本推理榜单 aNLI。
推荐:首次验证了通过非平行的文本与图像单模数据,能够让语言知识与视觉知识相互增强。论文 7:ERNIE-Doc: A Retrospective Long-Document Modeling Transformer摘要:Transformer 是 ERNIE 预训练模型所依赖的基础网络结构,但由于其计算量和空间消耗随建模长度呈平方级增加,导致模型难以建模篇章、书籍等长文本内容。受到人类先粗读后精读的阅读方式启发,ERNIE-Doc 首创回顾式建模技术,突破了 Transformer 在文本长度上的建模瓶颈,实现了任意长文本的双向建模。通过将长文本重复输入模型两次,ERNIE-Doc 在粗读阶段学习并存储全篇章语义信息,在精读阶段针对每一个文本片段显式地融合全篇章语义信息,从而实现双向建模,避免了上下文碎片化的问题。此外,传统长文本模型(Transformer-XL 等)中 Recurrence Memory 结构的循环方式限制了模型的有效建模长度。ERNIE-Doc 将其改进为同层循环,使模型保留了更上层的语义信息,具备了超长文本的建模能力。ERNIE-Doc 显著提升了长文本的建模能力,可以解决很多传统模型无法处理的应用难题。例如在搜索引擎中,ERNIE-Doc 可以对网页整体理解,返回用户更加系统的结果。在智能创作中,ERNIE-Doc 可以用来生成更加长篇、语义丰富的文章。超长文本理解模型 ERNIE-Doc 在包括阅读理解、信息抽取、篇章分类、语言模型等不同类型的 13 个典型中英文长文本任务上取得最优的效果。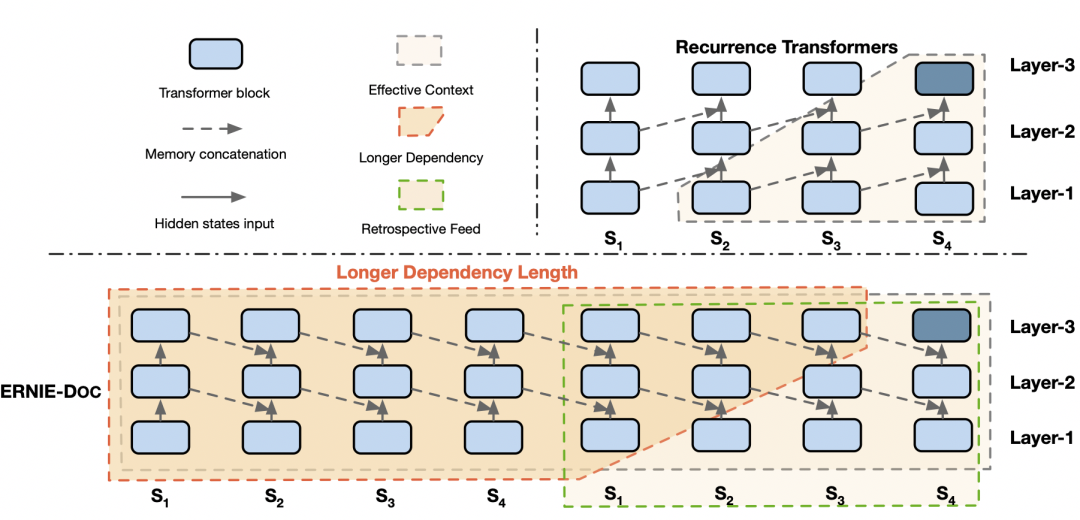
ERNIE-Doc 中的回顾式建模与增强记忆机制。
ArXiv Weekly Radiostation机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Extending rational models of communication from beliefs to actions.? (from Thomas L. Griffiths)2. True Few-Shot Learning with Language Models.? (from Kyunghyun Cho)3. Measuring Fine-Grained Domain Relevance of Terms: A Hierarchical Core-Fringe Approach.? (from Kevin Chen-Chuan Chang, Wen-mei Hwu)4. Neural Machine Translation with Monolingual Translation Memory.? (from Deng Cai)5. Dynamic Semantic Graph Construction and Reasoning for Explainable Multi-hop Science Question Answering.? (from Deng Cai)6. Prosodic segmentation for parsing spoken dialogue.? (from Mark Steedman)7. Retrieval Enhanced Model for Commonsense Generation.? (from Yang Liu)8. Distantly-Supervised Long-Tailed Relation Extraction Using Constraint Graphs.? (from Yang Liu)9. Unsupervised Sentiment Analysis by Transferring Multi-source Knowledge.? (from Jian Liu)10. Focus Attention: Promoting Faithfulness and Diversity in Summarization.? (from Ryan McDonald)1. ADNet: Attention-guided Deformable Convolutional Network for High Dynamic Range Imaging.? (from Jian Sun)2. PSGAN++: Robust Detail-Preserving Makeup Transfer and Removal.? (from Shuicheng Yan)3. Human-centric Relation Segmentation: Dataset and Solution.? (from Shuicheng Yan)4. PLM: Partial Label Masking for Imbalanced Multi-label Classification.? (from Mubarak Shah)5. Intriguing Properties of Vision Transformers.? (from Ming-Hsuan Yang)6. Unsupervised Part Segmentation through Disentangling Appearance and Shape.? (from Lei Zhang)7. Recent Standard Development Activities on Video Coding for Machines.? (from Wen Gao)8. ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search.? (from Xiaogang Wang)9. WSSOD: A New Pipeline for Weakly- and Semi-Supervised Object Detection.? (from Kai Chen)10. Few-Shot Learning with Part Discovery and Augmentation from Unlabeled Images.? (from Liang Wang, Tieniu Tan)本周 10?篇 ML 精选论文是:
1. Comment on Stochastic Polyak Step-Size: Performance of ALI-G.? (from Andrew Zisserman)2. DiBS: Differentiable Bayesian Structure Learning.? (from Bernhard Sch?lkopf, Andreas Krause)3. A Robust and Generalized Framework for Adversarial Graph Embedding.? (from Philip S. Yu)4. Anomaly Detection in Predictive Maintenance: A New Evaluation Framework for Temporal Unsupervised Anomaly Detection Algorithms.? (from Francisco Herrera)5. Robust Value Iteration for Continuous Control Tasks.? (from Shie Mannor, Jan Peters, Dieter Fox)6. A Precise Performance Analysis of Support Vector Regression.? (from Mohamed-Slim Alouini)7. Trimming Feature Extraction and Inference for MCU-based Edge NILM: a Systematic Approach.? (from Luca Benini)8. ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction.? (from John Wright)9. Causally Constrained Data Synthesis for Private Data Release.? (from Somesh Jha)10. Robust learning from corrupted EEG with dynamic spatial filtering.? (from Alexandre Gramfort)
??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




