
大数据文摘授权转载自AI科技评论
作者 | 琰琰
在不少玩家眼中,GTA 5(GTA V)称得上是一款旷世神作!
GTA 也叫“侠盗猎车手”,是R星旗下一款超高人气动作冒险类游戏,目前已经发售至第五版。这款以犯罪为主题的经典游戏极具真实感,它的背景是以美国洛杉矶和南部加州为原型,三位角色也有着和人类相同的世界观,玩家可以任意选择或者切换角色,每个角色都有独立的人格和故事。
更有意思的是,这款游戏在剧情和动作设计堪称一部好莱坞大片,疾驰的赛车、激烈的枪战、精彩的追逐,让不少玩家欲罢不能。如果硬要给这款游戏提点改进意见,可能就是提升提升场景的真实感,毕竟,哪个玩家不想在现实世界上演“速度与激情”呢
没想到,英特尔AI 实验室真的把这个奢望变成了现实。最近,该实验室研究团队提出了一种增强合成图像的新方法,该方法把GTA中的城市街景变成了真实世界的场景。画面中的汽车、天空、路面变得更加平滑,更有光泽感。这种增强图像方法并非1:1还原了游戏中的原始街景,而是在此基础上渲染和生成了一个全新的城市样貌。研究人员介绍,其AI算法使用了来自德国真实街景的Cityscapes数据集,通过对该数据集的训练,AI“脑补”出了不存在的汽车、街道和建筑物等使其场景更具真实感。
这项研究成果出自Intel AI 实验室发表的一篇名为“Enhancing photorealism enhancement”的研究论文。这篇论文对图像增强的实际工作原理提供了深入、彻底的理解。
论文地址:https://arxiv.org/pdf/2105.04619.pdf用AI渲染游戏人物和场景的概念并不新鲜,但现有方法大多会产生严重的伪影,不稳定,或者渲染速度太慢。
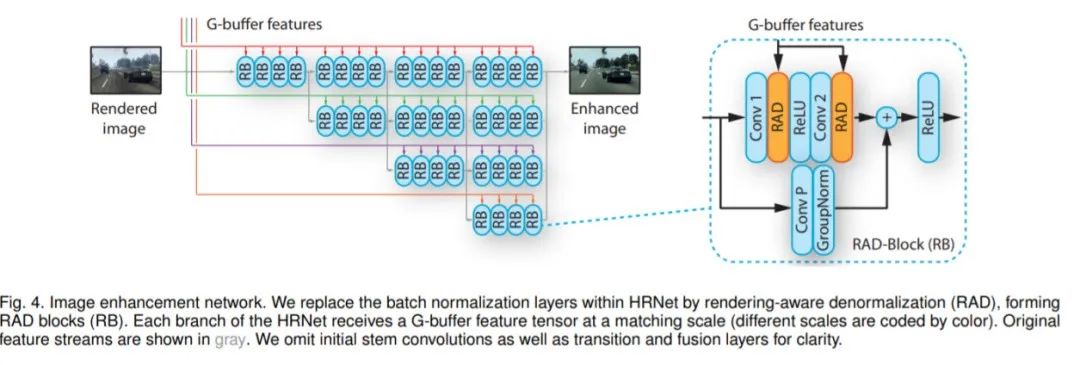
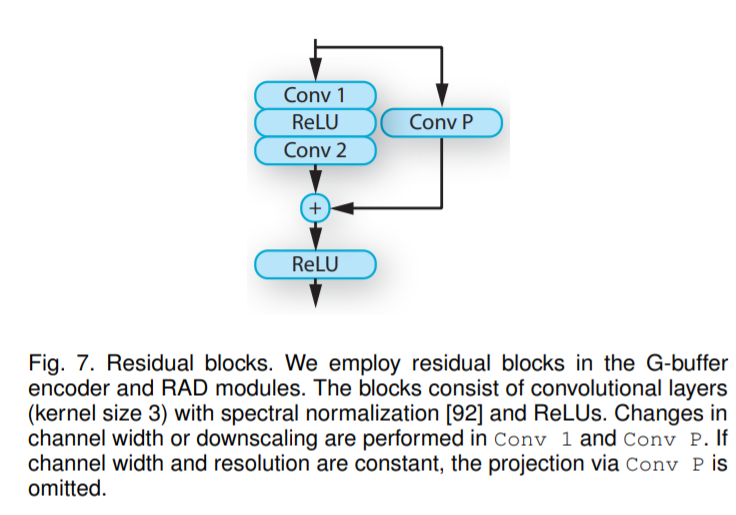
在本篇论文中,研究人员提出了一种基于卷积网络的增强合成图像真实感的新方法。具体来说,卷积网络利用传统渲染管道生成中间表示,通过新的对抗目标训练,在多个感知层次上提供强大的监督。在训练过程中对图像块进行采样,以消除图像伪影。最后经过对深层网络模块的多种体系结构的改进。实验结果表明,与最近的图像到图像转换方法和各种其他基线相比,该方法在稳定性和真实性方面取得了实质性进展。为了提高输出图像的真实感,研究人员在该网络中添加了额外输入。具体来说,他们从图像管道中提取了中间渲染缓冲区(intermediate rendering buffers ,G-buffers)。G-buffer经过编码器网络处理后,能够提供图像场景中关于景深、形状、光照、透明度、材质等特征信息。这些特征将作为图像增强网的输入,用来调制图像特征。图像增强网络采用HRNetV2架构,它在各种密集预测任务上表现出了很强的性能。HRNet能够以不同分辨率运行的多个分支处理图像。同时以较高的分辨率呈现更精细的图像结构。在篇工作中,研究人员对其进行了如下调整:第一,用regular卷积代替初始的strided 卷积,使网络在全分辨率下运行,并保留更精细的细节。第二,在每个分支中的residual blocks 中,通过渲染感知非规范化(rendering-aware denormalization ,RAD)模块来替换批处理规范化层。Residual blocks由卷积层(核大小为3)、光谱归一化(spectral normalization)和ReLUs组成。它在Conv 1和Conv P中执行通道宽度的改变或缩小。如果通道宽度和分辨率不变,则省略Conv P的推理环节。RAD模块和G-buffer编码器中均有使用Residual blocks。RAD模块通过几何图形、材料、光照等来自G-buffer的语义信息来调制图像特征张量。这些图像特征通过group normalization进行标准化,然后再通过元素权重(γ, β)进行缩放和移位。每个RAD模块中有三个Residual blocks来变换G-buffer特征,可以更好地适应权重变化。第一,用LPIPS loss评估输入和输出图像之间的差异。
鉴别器用来区分经过网络增强的图像和来自数据集的真实图像。它由健壮的语义分割网络、感知特征提取网络和多个鉴别器网络组成。研究人员采用MSeg进行语义分割,VGG16进行感知特征提取。这两个网络都是预训练的,在训练图像增强网络时没有进行优化。然后将分割网络应用于来自目标数据集的真实图像和未修改的渲染图像(这为真实图像和合成图像提供了兼容的语义信息)。将VGG特征提取网络应用于真实图像和增强图像。在被训练的过程中,鉴别器使用一种特定的采样策略来选择真实和合成的图像块,以显著减少常见的伪影。
论文中,研究人员进行了一组对照实验,具体评估了采样策略、G-buffers、使用G-buffers的架构以及对抗性损失的不同设置等指标。结果如下图:
在采样策略方面,通过对uniform采样与matching patch pairs采样在不同尺寸(196、256、400)下的对比,表明较小的patch减少了原始和目标图像数据之间的不匹配,较大的patch伪影更强,如下图第2列和第3列。较小的patch采样可显著降低sKVD。在matching patches采样中,中高层次的sKVD有所降低了,而最低层次上的sKVD略有增加。这可以解释为uniform采样patch的优势是可以被更高水平的分布不匹配所抵消。在引入G-buffers策略上对比了三种方法:第一,简单地将它们附加到渲染图像(Concat)中。它使用标准的HRNet架构进行图像增强(没有RAD模块或RAD块)。第二,将RAD模块替换为SPADE模块。第三,使用本篇论文的RAD模块。结果表明,简单的concatenation比SPADE模有更好的结果。SPADE模块在整个数据集中很不稳定,对比真实图像有明显的伪影和颜色偏差。如下图中间列:在鉴别器评估方面,比较了PatchGAN,它使用四个鉴别器网络,每个鉴别器网络以不同的比例摄取图像。实验表明,PatchGAN鉴别器的输出结果明显缺乏真实感。如下图,推理层和自适应反向传播都发挥了作用,但不在同一感知水平。如果移除自适应反向传播会降低最高层次上sKVD,移除推理层会增加高层次的sKVD。当考虑到所有层次时,推理和自适应反向传播相结合是有益的。推理层的效果如下图:总的来说,本篇论文的方法显著增强了渲染图像的真实感。针对真实数据集中具有清晰对应关系的物体和场景,它能够产生高质量的增强,这些增强在几何和语义上与输入图像一致,同时与相应数据集的样式相匹配。在 Geforce RTX 3090 GPU上,该方法在当前未优化的实现中推理需要半秒钟。由于用作输入的G-buffer是在GPU上生成的,因此可以更深入地集成到游戏引擎中,提高效率和真实感水平。
此外,该方法生成的图像在结构上与输入场景一致,这有助于使用可用于合成数据的基本事实注释。为了支持未来的研究,研究人员将发布GTAV和VIPER数据集的增强图像。https://www.theverge.com/2021/5/12/22432945/intel-gta-v-realistic-machine-learning-cityscapes-dataset
https://www.engadget.com/gta-v-ai-photorealism-135046313.html
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/























 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




