
2021海华AI挑战赛·中文阅读理解·技术组 Rank12

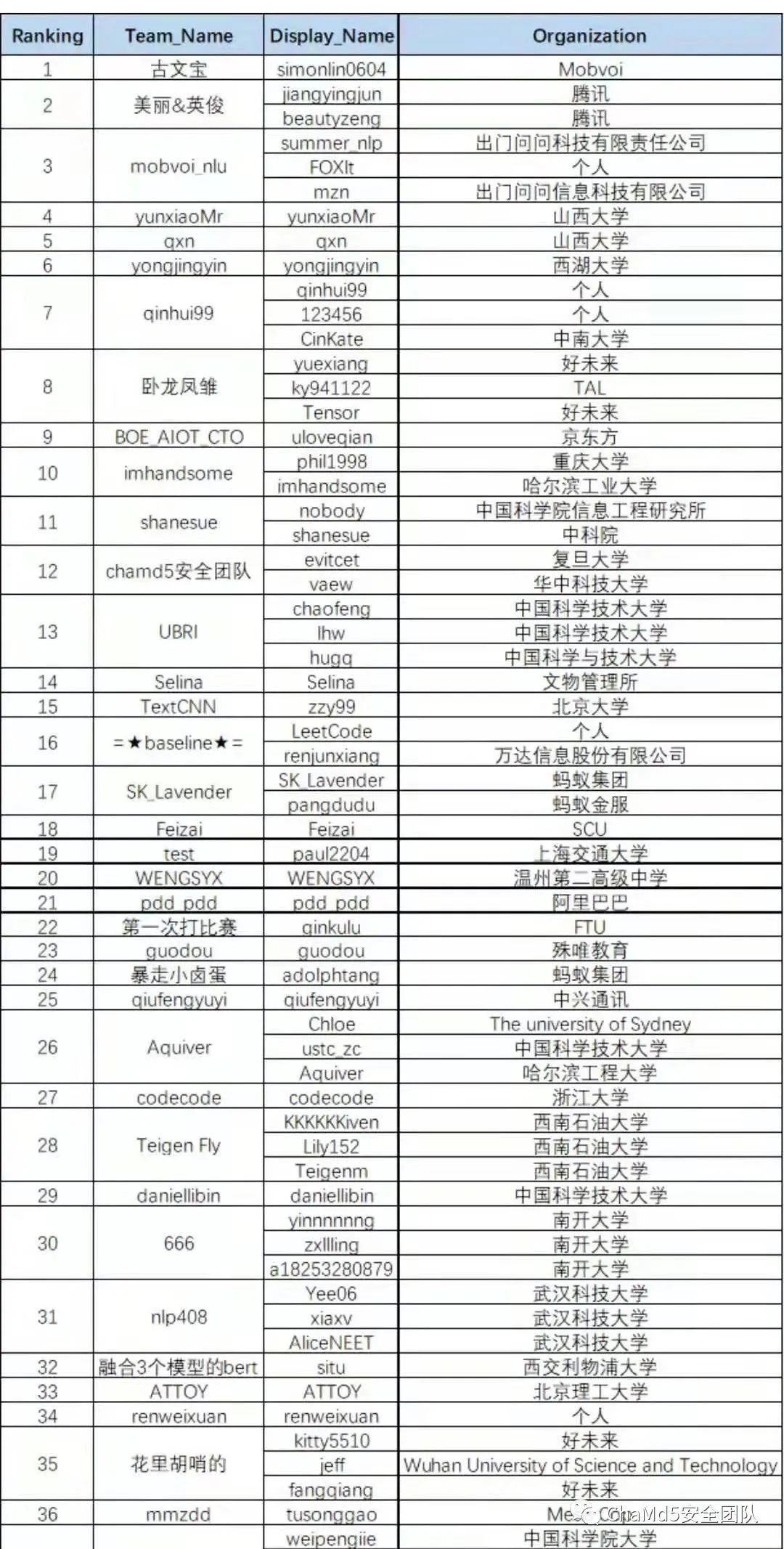
《2021海华AI挑战赛·中文阅读理解》大赛由中关村海华信息技术前沿研究院与清华大学交叉信息研究院联合主办,腾讯云计算协办,biendata比赛平台承办。大赛初赛刚刚于北京时间5月1日07:59:59完成,这次竞赛非常激烈,总共有1534名选手参与。其主要针对的问题是机器阅读理解。
机器阅读理解(Machine Reading Comprehension)是自然语言处理和人工智能领域的前沿课题,对于使机器拥有认知能力、提升机器智能水平具有重要价值,拥有广阔的应用前景。机器的阅读理解是让机器阅读文本,然后回答与阅读内容相关的问题,体现的是人工智能对文本信息获取、理解和挖掘的能力,在对话、搜索、问答、同声传译等领域,机器阅读理解可以产生的现实价值正在日益凸显,长远的目标则是能够为各行各业提供解决方案。本次比赛技术组的数据来自中高考语文阅读理解题库。每条数据都包括一篇文章,至少一个问题和多个候选选项。参赛选手需要搭建模型,从候选选项中选出正确的一个。
数据说明
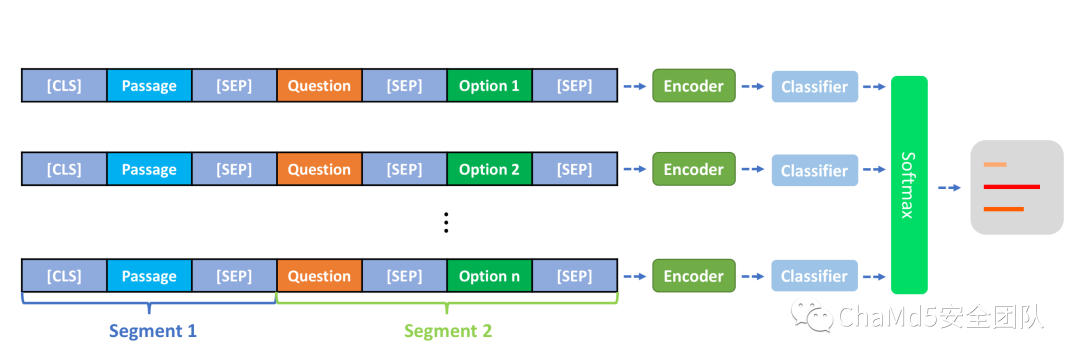
本次比赛技术组赛道共发布 8,000 篇阅读理解文章,数据格式为json。其中,Content为一个字符串,代表文章;Questions为问题列表,列表中都有一个或多个Q_id和Question,代表问题;一个Choices,代表问题的候选选项;Answer代表正确的选项,也是模型需要预测的对象;Type代表文本类别,具体包括 00 现代文 11文言文 22 古诗词 33现代诗词(在验证集中包含);Diff代表难度,具体包括 1 字词解释 2 标点符号作用 3 句子解释 4 填空 5选择正确读音 6 推理总结 7 态度情感 8 外部知识(在验证集中包含)。
一条样例数据:
{
????"ID":?"0001",
????"Content":?"春之怀古张晓风春天必然曾经是这样的:从绿意内敛的山头,一把雪再也撑不住了,噗嗤的一声,将冷面笑成花面,一首澌澌然的歌便从云端唱到山麓,从山麓唱到低低的荒村,唱入篱落,唱入一只小鸭的黄蹼,唱入软溶溶的春泥——软如一床新翻的棉被的春泥。",
????"Questions":?[
??????{
????????"Q_id":?"000101",
????????"Question":?"鸟又可以开始丈量天空了。”这句话的意思是???(???)",
????????"Choices":?[
??????????"A.鸟又可以飞了。",
??????????"B.?鸟又要远飞了。",
??????????"C.鸟又可以筑巢了。"
????????],
????????"Answer":?"A"
??????},
??????{
????????"Q_id":?"000102",
????????"Question":?"本文写景非常含蓄,请读一读找一找哪些不在作者的笔下有所描述",
????????"Choices":?[
??????????"A.冰雪融化",
??????????"B.?蝴蝶在花间飞舞",
??????????"C.白云在空中飘",
??????????"D.小鸟在空中自由地飞"
????????],
????????"Answer":?"C"
??????}EDA分析
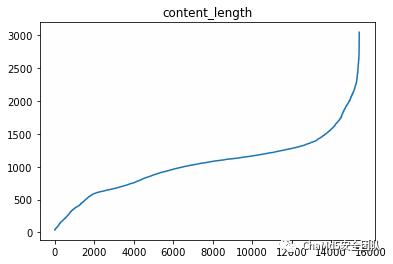
通过对数据做EDA分析我们发现,每条Content的长度都非常长,绝大部分都大于512:
通过对选项做统计,发现绝大多数是四个选项,且C选项较多

4????15329
3???????71
2???????25
Name:?num_choices,?dtype:?int64基本思路
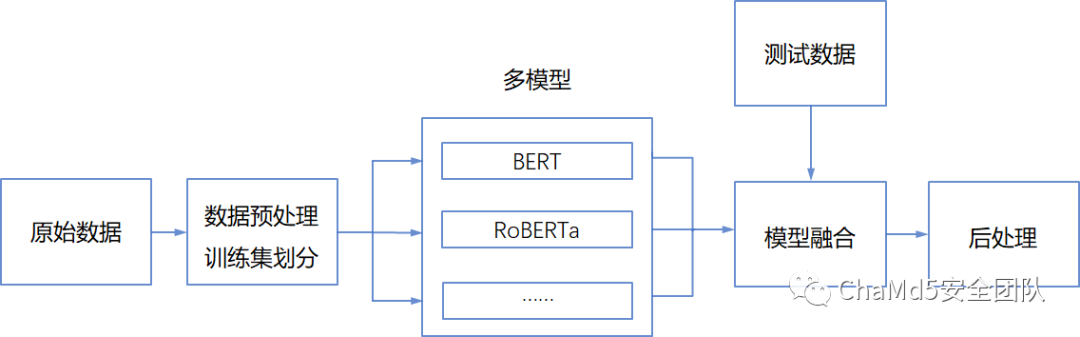
本题其实有三个非常关键的地方,一是模型的选定,不同模型对于此文本的效果上下浮动大约5~7个点;二是模型的融合策略,此处我们基于投票的方式对三个模型进行融合;第三是数据的扩充,此处我们尝试了对选项做shuffle,效果不是很好,最后选用了打伪标签的策略;总的来说我们的思路如下:
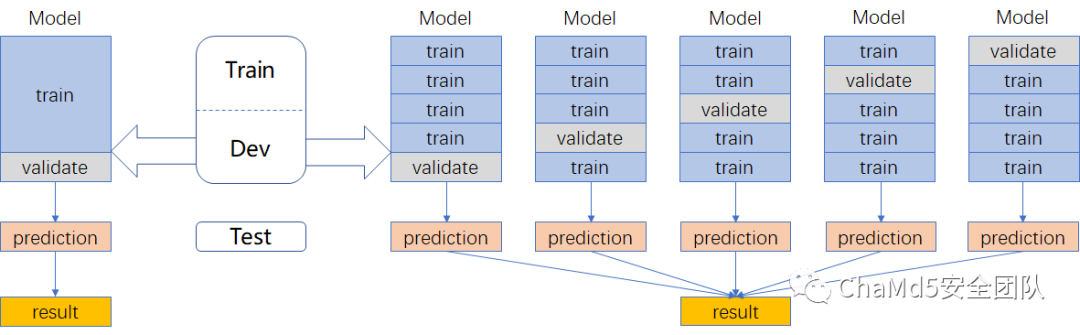
数据划分
使用五折交叉验证,最终融合训练的模型的方式,线上可以上涨4个点左右:
?利用全部数据,获得更多信息
?降低方差,提高模型性能
模型设计
此处我们直接使用https://huggingface.co/上的预训练模型,之后基于本次比赛的训练集进行再训练,最终完成推理。而模型的选择我们尝试了以下几种模型:
bert
macbert
guwenbert
roberta
xlnet我们发现guwenbert虽然是针对古文设计的,但是在此题中效果不是很好,而xlnet则 由于过大的原因,我们担心在后续过程中不满足模型大小要求,因此最后也没有选用,最终我们选用的模型是:
bert
macbert
roberta模型融合
这里的模型融合我们没有采用简单加权的方式,而是使用了一种投票的方式。我们认为bert,roberta,macbert为三个不同的学生,依据他们三个人的答案对每个选择题进行投票,每个模型给一定的权重,如果权重大于一个阈值则选定某个答案,反之则相信macbert所选定的答案,这种方法线上可以涨2个点;
半监督训练
在此题中数据量的扩充其实非常重要,由于可以使用无标签的网络语料,因此此处我们爬取了一定数量的语料,然后对其打上伪标签,之后再将打上伪标签的数据加入训练集中进行训练。具体的如下图所示:

总结
由于本次比赛只有前三才能拿奖,考虑到与前排差距有些许大,我们放弃了参加复赛,但是本次比赛我们也学到了很多东西。
end
招新小广告
ChaMd5?Venom?招收大佬入圈
新成立组IOT+工控+样本分析+AI?长期招新
欢迎联系admin@chamd5.org

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 Chamd5安全团队
Chamd5安全团队
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675