
Redis进阶秘籍,速看!
Redis 大家用的不少,但是我们大多数人可能都只是关注业务本身,对于底层的细节则经常忽略,久而久之,对个人的成长帮助甚少。

Redis 基础数据结构
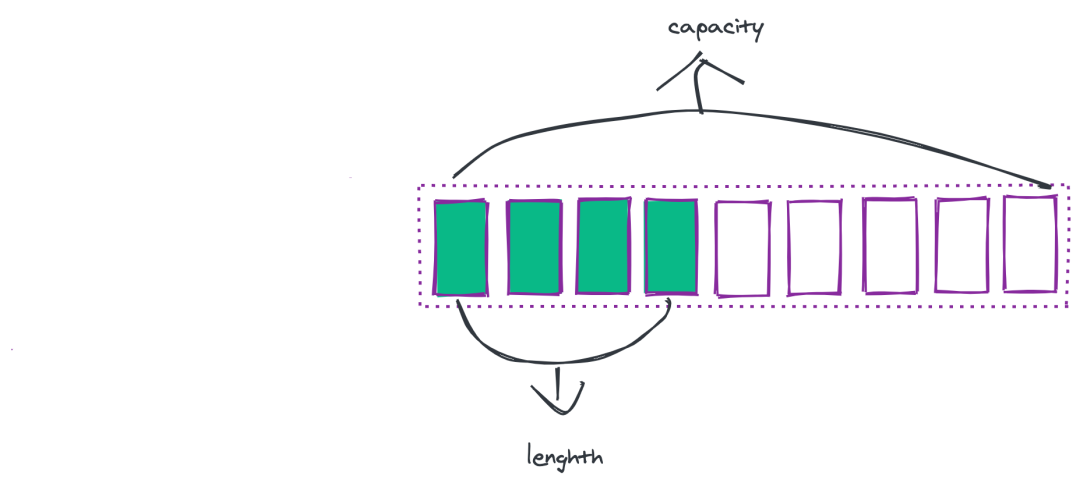
至于如何扩容,方法大致如下:当 length 小于 1M 的时候,扩容规则将目前的字符串翻倍;如果 length 大于 1M 的话,则每次只会扩容 1M,直到达到 512M。
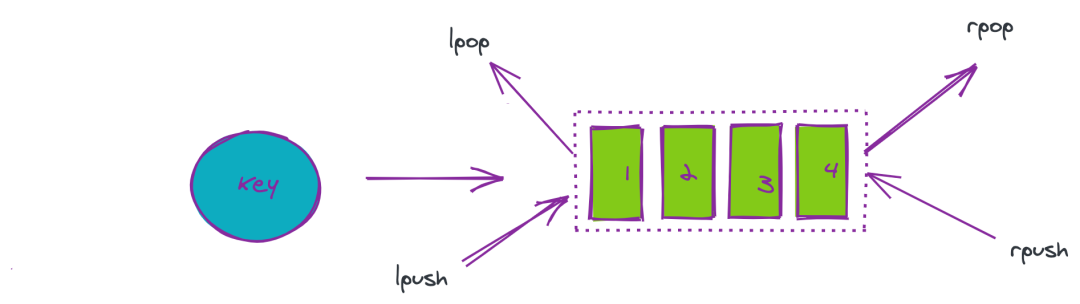
可运用的场景:在业务中异步队列使用 rpush/lpush 操作队列,使用 lpop 和 rpop 出队列,具体结构如下图所示:
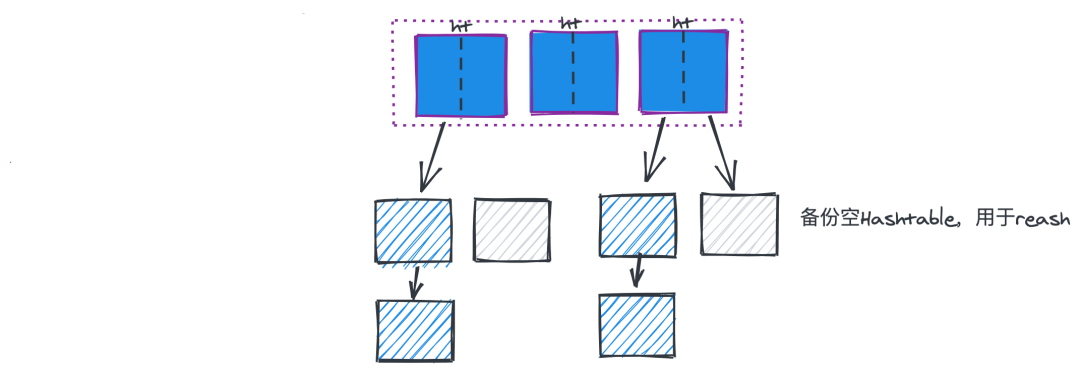
可运用场景:记录业务中的不同用户/不同商品/不同场景的信息:如某个用户的名称,或者用户的历史行为。
可运用场景:榜单,总榜,热榜。

Redis 进阶使用
①布隆过滤器
命令使用:
bf.add?#添加元素
bf.exists?#判断元素是否存在
bf.madd?#批量添加
bf.mexists?#批量判断是否存在
原理如下图:

②分布式锁
命令如下:
setnx?lock:mutex?ture?#加锁
del??lock:mutex?#删除锁
深入原理
①IO 模型
同时 Reids 给每一个客户端的套件字关联一个响应队列,Redis 服务器通过响应队列来将指令的接口返回给客户端。

Redis IO 处理模型
②通信协议
当然这种协议也有一个弊端就是:会存在浪费,哪怕一个节点之前被通知到了,下次被广播后仍然会重复转发。

③持久化
RDB:是对当前 Redis 的存储数据进行一次快照(具体原理和如何做,限于篇幅这里不做过多复述了)。
AOF:日志只记录 Redis 对内存修改的指令记录,Redis 提供了一个 bgrewriteaif 的指令对 AOF 进行压缩。
原理就是:开辟一个子进程对内存进行遍历后,转换成一系列对 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。
系列化完成后再将发送的增量 AOF 日志追加到这个新的 AOF 日志中,追加完成后用新的 AOF 日志代替旧的。
混合持久化:由于单纯 RDB 的话,可能存在数据的丢失,而频繁的 AOF 又会影响了性能,在 Redis 4.0 之后,支持了混合持久化。
也就是每次启动时候通过 RDB+增量的 AOF 文件来进行回复,由于增量的 AOF 仅记录了开始持久化到持久化结束期间发生的增量,这样日志不会太大,性能相对较高。
④主从同步
Redis 的同步方式有:主从同步、从从同步(由于全部都由 master 同步的话,会损耗性能,所以部分的 slave 会通过 slave 之间进行同步)。
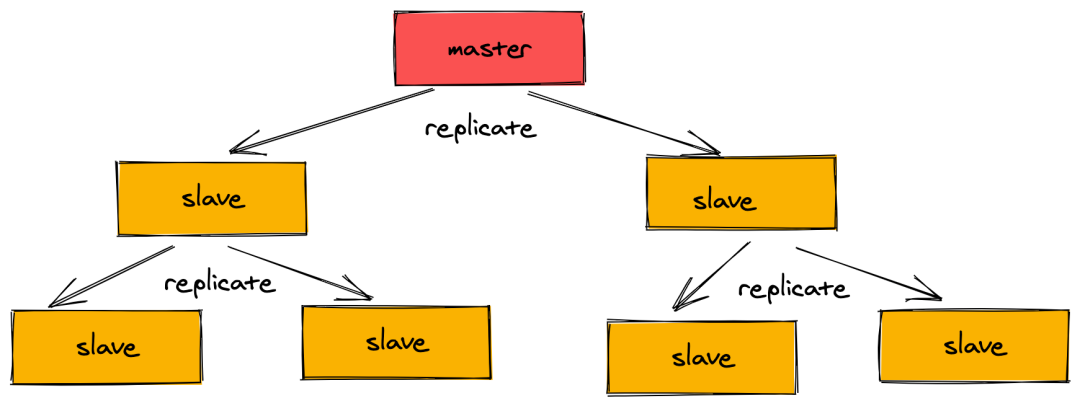
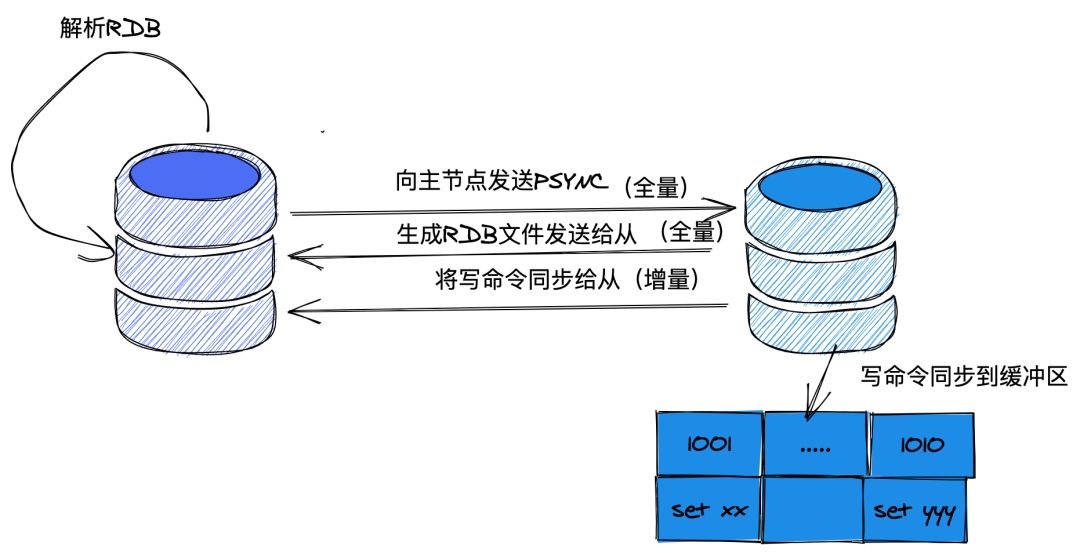
同步过程如下:
建立连接,然后从库告诉主库:“我要同步啦,你给我准备好”,然后主库跟从库说:“收到”。
从库拿到数据后,要把数据保存到库里。这个时候就会在本地完成数据的加载,会用到 RDB 。
主库把新来的数据 AOF 同步给从库。
⑤Sentinel

⑥Redis 集群工作原理
槽指派对应的二进制数组如下图所示:

当进行写的时候:
set?key?value
当然如果在节点 2 执行一条命令时,假设通过 CRC 计算后得到的值为 567,则其应该由节点 1 执行,此时命令会进行转向操作,将要执行的命令流转到节点 1 上去执行。

Redis 为什么变慢了
执行 SET、DEL 命令耗时也很久
偶现卡顿,之后又恢复正常了
在某个时间点,突然开始变慢了

原因分析:查看慢查询,由于笔者本身机器没有慢查询,所以这里看到是空(实在尴尬,这里没有可用的例子~~)
由于 Redis 在 IO 操作和对键值对的操作是单线程的,所以直接在客户端 Redis-cli 上执行的 Redis 命令有可能会导致操作延迟变大。
使用复杂的命令会让 Redis的处理变慢,以及CPU过高,例如 SORT、SUNION、ZUNIONSTORE 聚合类命令(时间负责度O(N) )。
查询的数据量过大,使得更多时间花费在数据协议的组装和网络传输过程中。
大 key 查询,比如对于一个很大的 hash、zset 等,这样的对象对 Redis 的集群数据迁移带来了很大的问题,因为在集群环境下,如果某个 key 太大,会导致数据迁移卡顿。
另外在内存分配上,如果一个 key 太大,那么当它需要扩容时,会一次性申请更大的一块内存,这也会导致卡顿。如果这个大 key 被删除,内存会一次性回收,卡顿现象会再一次产生。
集中过期,变慢的时间统一,所以业务中的 Key 过期时间尽量在统一的一个时间点加上一个随机数时间。
内存使用达到上限,当内存达到内存上限的时候,就不许淘汰一些数据,这个时候也可能导致 Redis 查询效率低。
碎片整理,Redis 在 4.0 版本后会自动整理碎片(由于内存回收过程中存在大量的碎片空间,不整理会导致 Redis 的空间少量浪费),而在整理碎片的过程中会消耗 CPU 的资源,从而影响了请求得到性能。
网络带宽,Redis 集群和业务混部,或者并发量过大以及每次返回的数据也很大,网卡带宽跑满的情况容易导致网络阻塞。
AOF 的频率过高,由于 AOF 需要将全部的写命令同步,如果同步的间隔比较短,也会影响到 Redis 的性能。
Redis 提供了 flushdb 和 flushall 指令,用来清空数据库,这也是导致 Redis 缓慢的操作。
Redis 安全
默认会监听 6379 端口,最好在 Redis 的配置文件中指定监听的 IP 地址,更进一步还可以增加 Redis 的 ACL 访问控制,对客户指定群组,并限限制用户对数据的读写权限。
访问 Redis 尽量走公司代理,由于 Redis 本身不支持 SSL 的链接,所以走公司代理可以保证安全。客户端登陆 Redis 必须设置 Auth 秘密登陆。
编辑:陶家龙
出处:转载自公众号云加社区(ID:QcloudCommunity)

精彩文章推荐:
我画了19张图,帮你彻底搞懂Redis
今天我才知道Redis有7种数据类型...
我拍了拍Redis,被移出了群聊···
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 51CTO技术栈
51CTO技术栈
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675