
MSRA的Transformer跨界超越CNN,还解决了计算复杂度难题
鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
谈到Transformer,你可能会想到一众NLP模型。
但现在,Transformer其实还能替CNN把活给干了,并且干得还不赖。
比如微软亚研院最新提出的Swin Transformer,就在COCO数据集的分割检测任务上来了个跨领域超车,一举达到SOTA。

那么,问题来了。
关注NLP的盆友想必就会问,用Transformer做CV任务,这个想法早已有之,也没见对CNN的地位有什么动摇,Swin Transformer又有何不同?
这就涉及到Transformer的CV应用存在的两个主要问题:
首先,基于Transformer的模型,token的长度是固定的。这对于NLP里的单词当然没有什么问题,但到了CV领域,视觉元素的比例各异,比如同一个场景中会存在大小不同的物体。
其次,图像中的像素与文本中的文字相比,对分辨率的要求更高。而常规的自注意力的计算复杂度,是图像大小的平方,这就导致其在像素级别进行密集预测时会出现问题。
而Swin Transformer,就旨在解决这些NLP和CV之间差异带来的问题。
通过移动窗口计算的分层Transformer

Swin Transformer的诀窍,核心是两板斧:
基于分层特征图,利用特征金字塔网络(FPN)或U-Net等技术进行密集预测
将自注意力计算限制在不重叠的局部窗口中,同时允许跨窗口连接,从而带来更高的效率。

这第二板斧,也就是基于移动窗口的自注意力:
如上图所示,在l层,采用常规的窗口分区方案,在每个窗口内计算自注意力。
在下一层l+1,窗口分区会被移动,产生新的窗口。新窗口中的自注意力计算跨越了l层中窗口的边界,提供了新的关联信息。
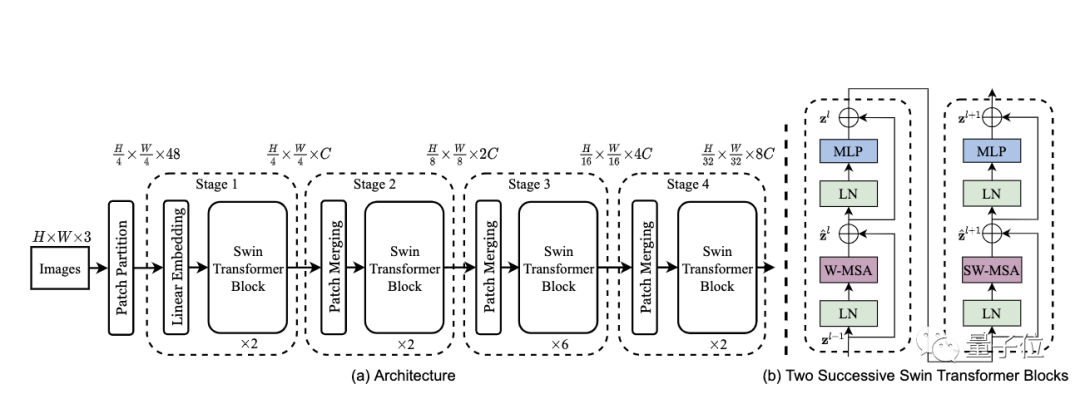
具体而言,Swin Transformer的整体架构是酱婶的:
将RGB图像分割成不重叠的图像块(token);
应用MLP(多层感知机)将原始特征转化为任意维度;
应用多个修改了自注意力计算的Swin Transformer块,并保持token的数量;
下采样层:通过合并2×2窗口中的相邻图像块来减少token的数量,并将特征深度增加一倍。
实验结果
研究人员让Swin Transformer分别挑战了ImageNet-1K、COCO和ADE20K上的图像分类、对象检测和语义分割任务。
其中,用于预训练的是ImageNet-22K数据集,ImageNet-1K数据集则用于微调。
结果显示,在COCO的分割和检测任务,以及ADE20K的语义分割任务上,Swin Transformer都超越了CNN,达到了SOTA。
而在ImageNet-1K的分类任务上,虽然没能超越EfficientNet,但效果相当且速度更快。

论文笔记就分享到这里,如果想要了解更多细节,请戳文末传送门。
也期待你的读后感分享哟~
传送门
论文地址:
https://arxiv.org/abs/2103.14030
开源地址:
https://github.com/microsoft/Swin-Transformer
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/mfo8xo/r_swin_transformer_new_sota_backbone_for_computer/
[2]https://xzcodes.github.io/posts/paper-review-swin-transformer
—?完?—
本文系网易新闻?网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
推荐阅读


有奖问卷 | 智能汽车哪家强

量子位?QbitAI · 头条号签约作者
?'?' ? 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 量子位
量子位
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675