
随着互联网技术对抗环境日益复杂化,各大网络平台页面可供用户上传并做展示的内容,都可能面临恶意攻击,例如黑灰产团伙会发布色情等不良图片和视频,以及发布可能涉嫌抄袭侵权的商品或其他违规信息,甚至一些黑灰产团伙还会通过技术手段,对发布的内容进行干扰,绕开平台的违规内容检测算法。阿里安全图灵实验室围绕行业痛点、难点技术问题,涉及文本变异对抗、图像、视频内容风控以及AI小样本研究的4个团队,分别与中国科学技术大学、浙江大学、华中科技大学等知名高校研究人员合作,研发包括“内容安全、文本反垃圾、AI模型鲁棒性、营商环境治理”4项新一代安全架构核心AI安全技术成果,均被国际会议ICASSP(International Conference on Acoustics, Speech and Signal Processing)2021收录。
小样本训练对抗血腥暴力视频
在实际应用场景中,AI安全技术能有效解决数据量大的头部风险,但对数据量极少或者新增的风险,现有AI模型往往难以胜任。在2018年“扫黄打非”专项整治中,就出现了一波名为“邪典”的风险(软色情、血腥暴力),主要为一些对青少年有不良导向的视频,此类相关内容清理有害信息就多达37万余条。随着短视频火爆发展,变异极快的“儿童邪典视频”极易死灰复燃。?累积此类别的数据供原有模型训练需要一定时间,而小样本方法恰好能填补“变异-模型未更新”的真空期。阿里安全图灵实验室高级算法工程师雍秦认为,使用小样本方法,可很好地在真空期中覆盖这种新风险,维护网络清朗空间环境。?“之前发表的小样本方法大都集中于优化小样本元学习阶段,该研究主要集中研究小样本方法中的预训练问题,我们AI安全团队提出了一种简单有效的方法,使用自监督方法预训练一个更深的网络,具有很好的鲁棒性和泛化性。”雍秦说。?该backbone具有很好的鲁棒性和泛化性,使用简单的元学习方法对其进行优化就可以在两个经典小样本数据集MiniImageNet和CUB数据集上都得到state-of-the-art结果。同时,研究者使用本文中提出的方法在跨域小样本测试的四个数据集上进行了测试,同样取得了state-of-the-art结果。
自监督学习的核心理念是对无标签数据的进行学习,而且学习的是无标签数据的数据结构或者特性,因此不需要标签结果,这样打造的AI模型对新鲜样本的适应能力比较强。?在医疗、生物等行业安全领域,都普遍存在“样本标注困难”“成本高”问题。雍秦坚信,小样本自监督学习能很好改善这些困境。
阿里&浙大:增强AI对抗垃圾文本变异的稳定性和识别力
李进锋等阿里安全算法专家经常会遇到发送大量垃圾文本的恶意用户,黑灰产试图通过对抗的手段规避阿里安全内容风控智能AI系统检测。?以文本内容为例,恶意用户可通过对文本中的违规内容进行变形变异,从而达到绕开模型识别检测的目的。由于文本对抗门槛和成本低,文本内容风控场景中的对抗异常激烈,对抗给智能风控体系带来了巨大挑战。
为应对挑战,解决对抗场景中风控模型性能衰减的问题,阿里安全图灵实验室与浙江大学提出了基于对抗关系图的文本对抗防御技术。?
在本研究中,研究者首次提出了基于图模型来建模对抗知识。研究者首先采用知识+数据驱动的方式,基于语言学和语音学知识来构建对抗关系图,图中的每个节点表示一个字符,如果两个字符音近或者形近,则对应的节点之间形成一条边,表示存在对抗变异关系。?接着,研究者利用图嵌入算法学习每个节点的向量表示来表征对抗关系图中的对抗知识。最后通过融合对抗表征和语义表征实现对抗知识注入,达到增强模型鲁棒性的目的。与与现有的技术相比,阿里安全图灵实验室的优势在于,阿里安全的内容风控系统建模的是对抗关系,这种关系是与场景无关的,因此学到的对抗知识表征是通用的,可以直接复用到各个场景。对抗关系图构建和对抗知识表征可以离线完成,并且只需训练一次即可应用到各个场景;基于对抗关系图,可以解决更复杂的多跳变异问题,如微 (wei) à?威 (wei) à?崴 (wai)。?与现有技术相比,阿里安全的内容风控系统建模与场景无关,只需训练一次即可应用到各个场景,基于对抗关系图,就可以解决更复杂的多跳变异问题,如微(wei)-威(wei)-崴(wai)。阿里安全团队将防御框架应用到了手机淘宝、旺旺反垃圾场景,取得了不错的应用效果。
去年,阿里安全图灵实验室发布了一款“AI安全诊断大师”,对AI模型进行全面的安全性评估,并针对AI系统的缺陷,提出提升模型防御能力建议。?这种“AI安全防火墙”的一个关键技术就是对抗样本检测,对抗样本的重要特性之一是人眼无法区分,导致无法通过人工打标进行对抗样本的检测。?2020年,阿里安全图灵实验室提出了一种基于Transformer的对抗样本检测方法,改进了传统对抗样本检测方法只能检测特定攻击,难以泛化到其他攻击的缺陷。?此次研究解决的是对抗样本检测泛化性的问题,但针对非常小扰动和非常稀疏的对抗样本的检测,仍是目前研究的难点。为了既能识别扰动大而广的对抗样本,又能识别扰动比较小而稀疏的对抗样本,中科大和阿里的研究者提出了基于图像域和梯度域的双流对抗样本检测网络,图像域用于识别扰动大而广的对抗样本,梯度域则用于识别扰动比较小而稀疏的对抗样本。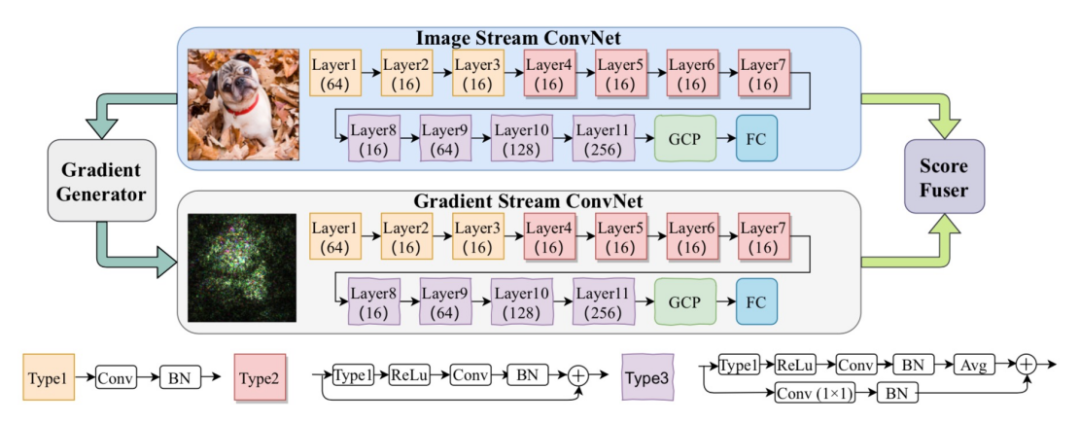
随着防御技术不断变强,攻击形态越来越多样。在真实应用场景中,阿里安全图灵实验室也发现了一些没有限制情况下的攻击形态,这类攻击很难应对。阿里安全图灵实验室高级安全专家越丰介绍,目前阿里希望能从攻防两端以及产学研集合的方式来应对这种威胁。阿里安全联合清华大学、UIUC(伊利诺伊大学厄巴纳-香槟分校)举办了CVPR2021的AML-CV workshop,产学研结合探讨AI安全的问题。另外,三方在workshop上联合天池一起举办了2个比赛:第六期-ImageNet无限制对抗攻击和防御模型的白盒对抗攻击。
电商平台的各种模态商品数据迅速增长,如何从中快速且准确地找出用户需要的商品是一个艰巨的挑战。基于内容的文本到商品图像的跨模态检索就是缓解这个挑战的关键技术之一。?传统的跨模态检索方法建立在单层次的特征表示和单粒度的相似度度量上,难以有效地解决商品图像检索的问题。?同时,文本到商品图像的跨模态检索任务更复杂,比如单是商品图像中的一类“服饰”已经表现出巨大的差异性,服饰可以穿在模特身上,也可以单独摆放,还可折叠起来展示,服饰图像背景往往也很复杂。不止如此,商品图像包含其它很多丰富的种类,并且一幅图像内往往呈现出多种物体,琳琅满目,难辨差异。?为此,阿里安全图灵实验室提出了一种基于多层次编码、多粒度相似性学习的跨模态检索模型,在融合多层次特征的基础上,结合物体、图像两种不同粒度的跨模态相似性,能够有效地提升跨模态检索模型在商品图像检索任务上的表现。?
在阿里安全图灵实验室实习的浙江大学硕士生马哲介绍,这次研究在文本-商品图像跨模态检索的场景下,提出了HSL网络和两种不同粒度的相似性度量方式,可显著提升商品图像检索的性能,并能适应复杂的商品内容检索。?
阿里安全图灵实验室资深算法专家华棠则强调,这种新研究不仅致力于提升用户搜索体验,也会用在平台内容治理上,谨防黑灰产利用看似合规的商品图片宣传“禁限售”类商品。?Github地址: https://github.com/liufh1/hsl
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







![一颗小酒:你们要的漫画还原身材2.0 抖音发不了的发这叭[doge] ](https://imgs.knowsafe.com:8087/img/aideep/2021/7/5/2eaac72aa2e0d34df5513af8e11b39cb.jpg?w=250)
![芊川一笑 到三亚了 海风好大[害羞]](https://imgs.knowsafe.com:8087/img/aideep/2021/11/27/dcf9c6d87de7bf15fecfb4efb3f756a0.jpg?w=250)



 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




