
深度学习领域最常用的10个激活函数,一文详解数学原理及优缺点
选自medium
作者:Sukanya Bag
机器之心编译
编辑:小舟、蛋酱
激活函数是神经网络模型重要的组成部分,本文作者Sukanya Bag从激活函数的数学原理出发,详解了十种激活函数的优缺点。



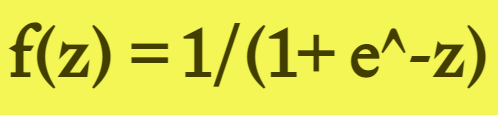
Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化;
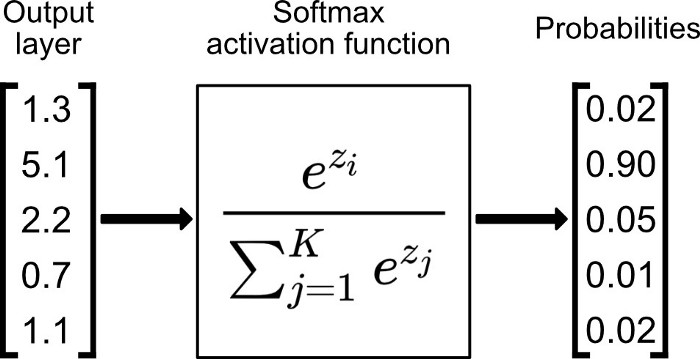
用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适;
梯度平滑,避免「跳跃」的输出值;
函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率;
明确的预测,即非常接近 1 或 0。
倾向于梯度消失;
函数输出不是以 0 为中心的,这会降低权重更新的效率;
Sigmoid 函数执行指数运算,计算机运行得较慢。
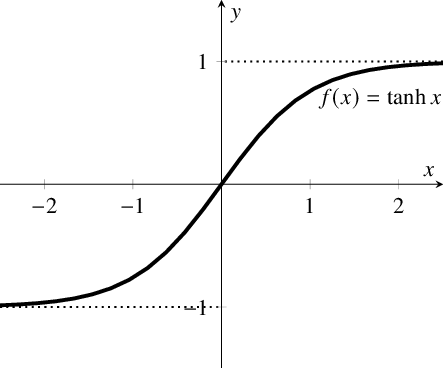
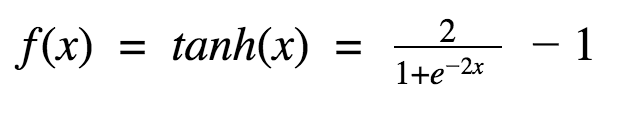

首先,当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二者的区别在于输出间隔,tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好;
在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。
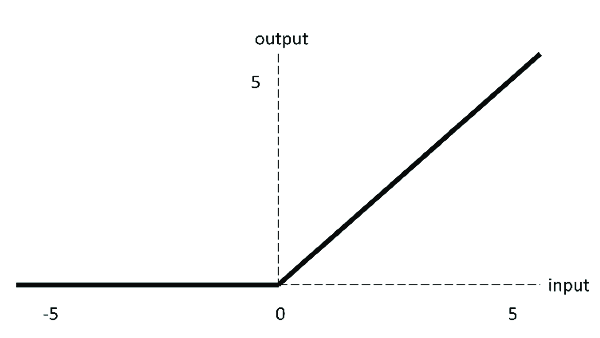

当输入为正时,不存在梯度饱和问题。
计算速度快得多。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快。
Dead ReLU 问题。当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题;
我们发现 ReLU 函数的输出为 0 或正数,这意味着 ReLU 函数不是以 0 为中心的函数。
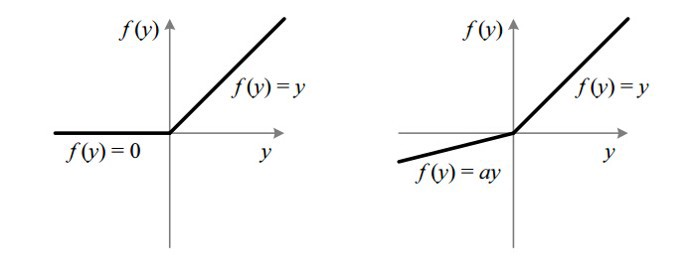

Leaky ReLU 通过把 x 的非常小的线性分量给予负输入(0.01x)来调整负值的零梯度(zero gradients)问题;
leak 有助于扩大 ReLU 函数的范围,通常 a 的值为 0.01 左右;
Leaky ReLU 的函数范围是(负无穷到正无穷)。
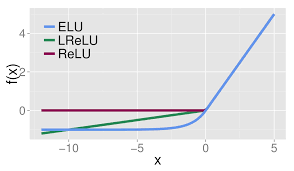
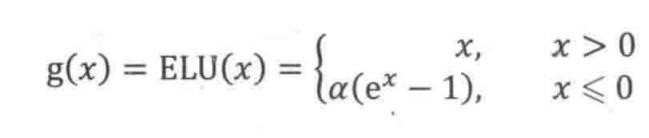
没有 Dead ReLU 问题,输出的平均值接近 0,以 0 为中心;
ELU 通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向零加速学习;
ELU 在较小的输入下会饱和至负值,从而减少前向传播的变异和信息。


如果 a_i= 0,则 f 变为 ReLU
如果 a_i> 0,则 f 变为 leaky ReLU
如果 a_i 是可学习的参数,则 f 变为 PReLU
在负值域,PReLU 的斜率较小,这也可以避免 Dead ReLU 问题。
与 ELU 相比,PReLU 在负值域是线性运算。尽管斜率很小,但不会趋于 0。

在零点不可微;
负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。
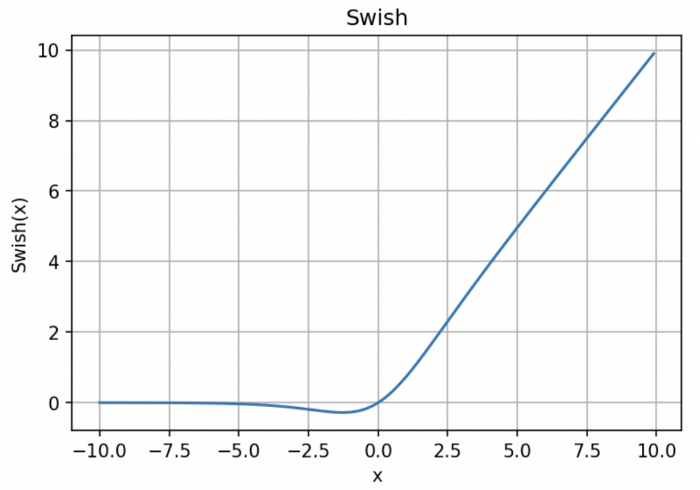
「无界性」有助于防止慢速训练期间,梯度逐渐接近 0 并导致饱和;(同时,有界性也是有优势的,因为有界激活函数可以具有很强的正则化,并且较大的负输入问题也能解决);
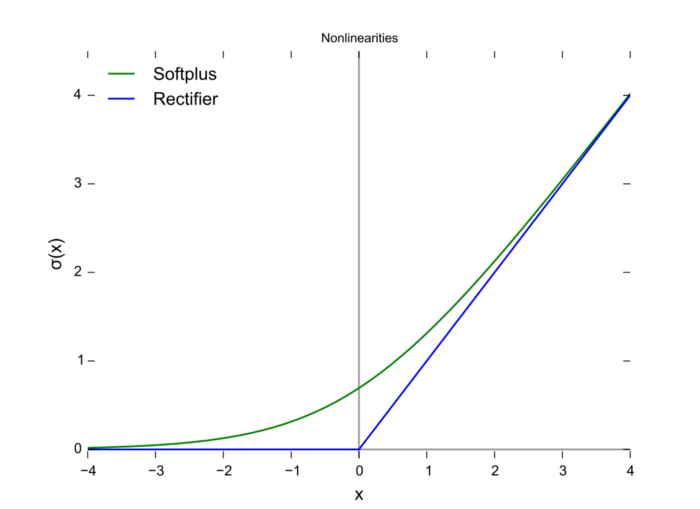
导数恒 > 0;
平滑度在优化和泛化中起了重要作用。



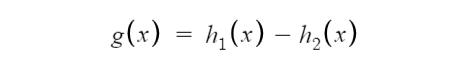

AWS白皮书《策略手册:数据、 分析与机器学习》
点击阅读原文,免费领取白皮书。

??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675