
cajviewer逆向分析与漏洞挖掘

前言
CAJViewer是一个论文查看工具,主要用于查看caj文件格式的论文。本文介绍对该软件进行逆向分析和漏洞挖掘的过程。
Fuzz测试
Windows版本
首先分析的是CAJViewer的Windows版本,由于我们的目的是挖掘软件的漏洞,通过介绍我们知道CAJViewer本质上是一个文件解析程序,因此该软件的高危模块应该是软件中解析文件数据的部分,因此首先应该大概定义软件数据处理部分所在位置,Windows平台下可以使用 process monitor来进行初步的分析。
首先打开process monitor并开始捕获事件,然后使用CAJViewer打开一个caj文件,等文件解析完成后停止捕获事件。

然后我们可以过滤一下需要查看的事件,比如上图设置了只查看文件操作并且只查看对?input.caj?文件的操作,该文件就是之前让CAJViewer打开的文件。
然后我们可以找一下读文件的操作(ReadFile),因为大部分文件解析逻辑应该读一部分文件内容解析一部分,因此通过查看读文件时的调用栈就可以大概定位解析数据的模块,然后双击就可以查看调用相应函数的调用栈。
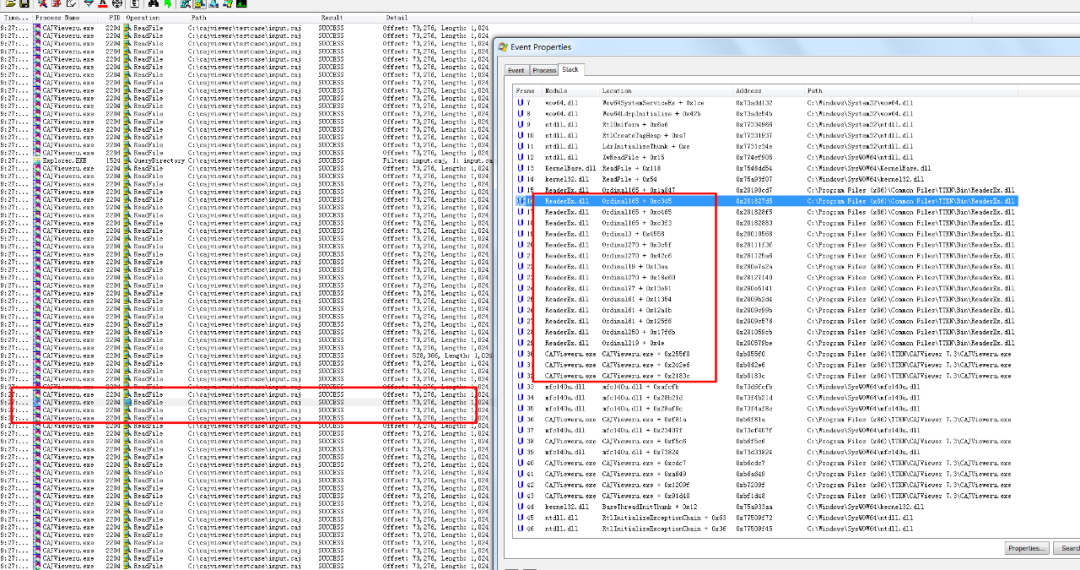
通过查看多个数据读取的调用栈,可以发现ReaderEx.dll在调用栈中出现多次,因此大概可以猜测ReaderEx.dll应该主要负责处理文件数据。
Linux版本
逆向了一会ReaderEx.dll后,发现CAJViewer今年还发布了Linux版本,于是下载下来分析了一下。下载下来后是一个可执行文件CAJViewer-x86_64-libc-2.24.AppImage,执行起来查看进程的maps发现其实软件会在tmp目录把打包好的二进制解压,然后去执行tmp目录下的二进制。

这里可以直接把/tmp/.mount_CAJVierjayBH/拷贝到一个目录,然后就可以直接执行?cajviewer了。

查看解压处理的二进制发现一个libreaderex_x64.so,看名字应该是ReaderEx.dll的Linux版本,然后使用IDA打开,发现比Windows版本的要好分析一点,信息也比ReaderEx.dll的多。于是接下来决定对Linux版本的二进制进行分析。
首先看看主程序cajviewer,查看main函数可以发现软件是用qt写的

之后翻了一下函数列表,发现了MainWindow::OpenFile,看名称应该是打开一个文件。
__int64?__fastcall?MainWindow::OpenFile(MainWindow?*this,?const?QString?*a2)
{
??v2?=?this;
??QString::toUtf8_helper(&v16,?a2);
??memset(v19,?0,?sizeof(v19));
??*v19?=?0x2D8;
??*&v19[4]?=?256;
??*&v19[8]?=?CAJFILE_CreateErrorObject(&v20);
??v3?=?*&v19[8];
??if?(?*v16?>?1?||?(v5?=?*(v16?+?2),?v4?=?v16,?v5?!=?24)?)
??{
????QByteArray::reallocData(&v16,?v16[1]?+?1,?*(v16?+?11)?>>?31);
????v4?=?v16;
????v5?=?*(v16?+?2);
??}
??v6?=?CAJFILE_OpenEx1(v4?+?v5,?v19);???????????//?打开文件
这里对输入的QString进行一些处理后,调用了CAJFILE_OpenEx1函数,该函数位于libreaderex_x64.so。
Fuzz CAJFILE_OpenEx1函数
函数代码如下

函数的第一个参数是要解析的文件路径,第二个参数是一块内存,这个参数的结构可以查看MainWindow::OpenFile调用点。
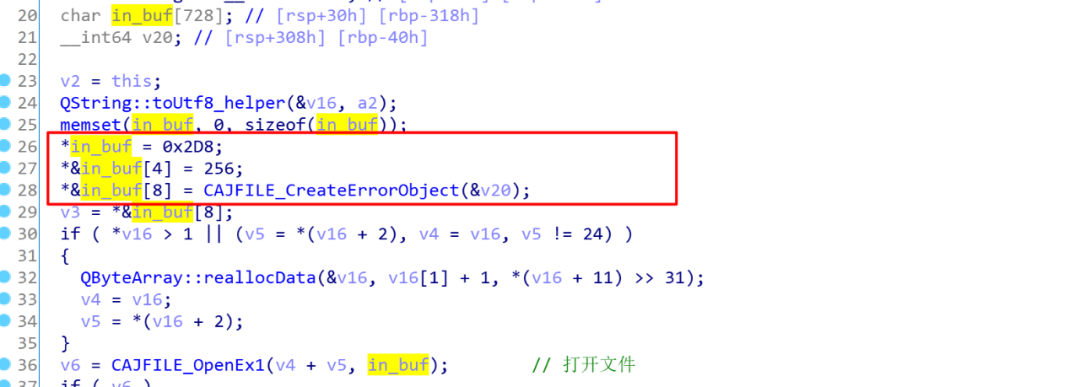
可以看到in_buf的结构如下
+0:?4个字节?in_buf的长度
+4:?4个字节?一个整形值
+8:?一个指针,?存放构造好的?ErrorObject
使用调试器在这个函数下个断点,然后打开一个文件就可以看到入参如下
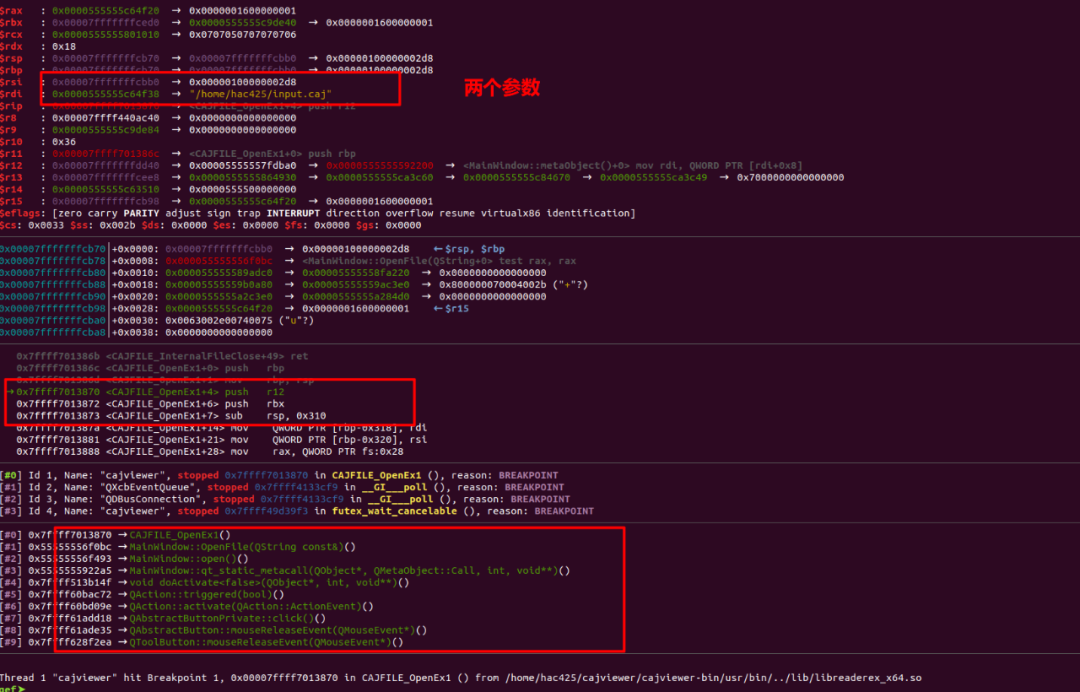
之后有简单的翻了一些该函数的实现,以及使用该函数的位置可以大概确定CAJFILE_OpenEx1用于打开一个文件,并会对文件的内容进行解析,因此下面打算使用AFL Qemu模式Fuzz一下这个函数。
Fuzz之前需要写一点代码把so加载到内存,然后构造参数对目标函数进行测试。
首先需要把SO加载到内存中并获取目标函数的地址
void?my_init(void)?__attribute__((constructor));?//告诉gcc把这个函数扔到init?section
void?my_init(void)
{
????void?*handle;
????handle?=?dlopen("/home/hac425/cajviewer/cajviewer-bin/usr/lib/libreaderex_x64.so",?RTLD_LAZY);
????struct?link_map?*lm?=?(struct?link_map?*)handle;
????printf("%lx\n",?lm->l_addr);
????p_CAJFILE_OpenEx1?=?dlsym(handle,?"CAJFILE_OpenEx1");
????p_CAJFILE_CreateErrorObject?=?dlsym(handle,?"CAJFILE_CreateErrorObject");
}
my_init会在main函数之前执行,代码流程如下
首先
dlopen把so加载到内存,并把so在内存中的基地址打印到屏幕,便于后续测试。然后使用
dlsym获取CAJFILE_OpenEx1和CAJFILE_CreateErrorObject函数的地址。
然后在main函数中就会构造参数调用目标函数
int?main(int?argc,?char?**argv)
{
????char?buf[0x2D8];
????printf("main:%p\n",?main);
????memset(buf,?0,?0x2D8);
????*(unsigned?int?*)buf?=?0x2D8;
????//?*(unsigned?int?*)(buf?+?4)?=?256;
????//?*(char*?*)(buf?+?8)?=?p_CAJFILE_CreateErrorObject();
????char?*ret?=?p_CAJFILE_OpenEx1(argv[1],?buf);
????return?0;
}
代码逻辑很简单,首先构造CAJFILE_OpenEx1函数的第二个参数,然后把argv[1]作为文件路径传入函数。
然后编译一下
gcc?CAJFILE_OpenEx1.c?-o?test_CAJFILE_OpenEx1_dbg?-ldl?-lheapasan?-L?libheapasan/??-g
编译后执行一下,可以看到正常执行完了,并打印出so的基地址和main函数的地址。
harness$?./test_CAJFILE_OpenEx1_dbg?~/input.caj
string?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstringto?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?int
image?base:0x7f6d87bff000
p_CAJFILE_OpenEx1:0x7f6d881e486c
main:0x555ed124cb71
接下来再使用afl-qemu-trace执行一下,获取一些地址用于Fuzz,使用afl-qemu-trace执行一个可执行程序时,其进程的so的地址都是固定的。
harness$?~/AFLplusplus-2.66c/afl-qemu-trace?./test_CAJFILE_OpenEx1_dbg?~/input.caj
string?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstringto?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?intstring?to?int
image?base:0x400133e000
p_CAJFILE_OpenEx1:0x400192386c
main:0x4000000b71
可以看到libreaderex_x64.so的基地址为0x400133e000,?test_CAJFILE_OpenEx1_dbg?的main函数的地址为0x4000000b71。
然后去IDA中查看libreaderex_x64.so中代码段的范围
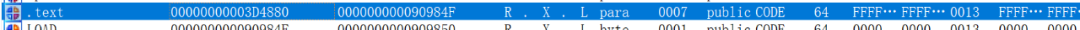
所以可以得到afl-qemu-trace执行时libreaderex_x64.so中代码段的范围为
开始地址:?0x400133e000+0x3D4880?=?0x4001712880
结束地址:?0x400133e000+0x90984F =?0x4001c4784f
然后可以使用AFL进行测试了
export?AFL_CODE_START=0x4001712880
export?AFL_CODE_END=0x4001c4784f
export?AFL_ENTRYPOINT=0x4000000b71
/home/hac425/AFLplusplus-2.66c/afl-fuzz?-m?none?-Q?-t?20000?-i?in?-o?out?--?./test_CAJFILE_OpenEx1_dbg?@@
其中设置的环境变量的作用如下
AFL_CODE_START?和?AFL_CODE_END?表示需要统计覆盖率的范围
AFL_ENTRYPOINT?表示开启forkserver的位置
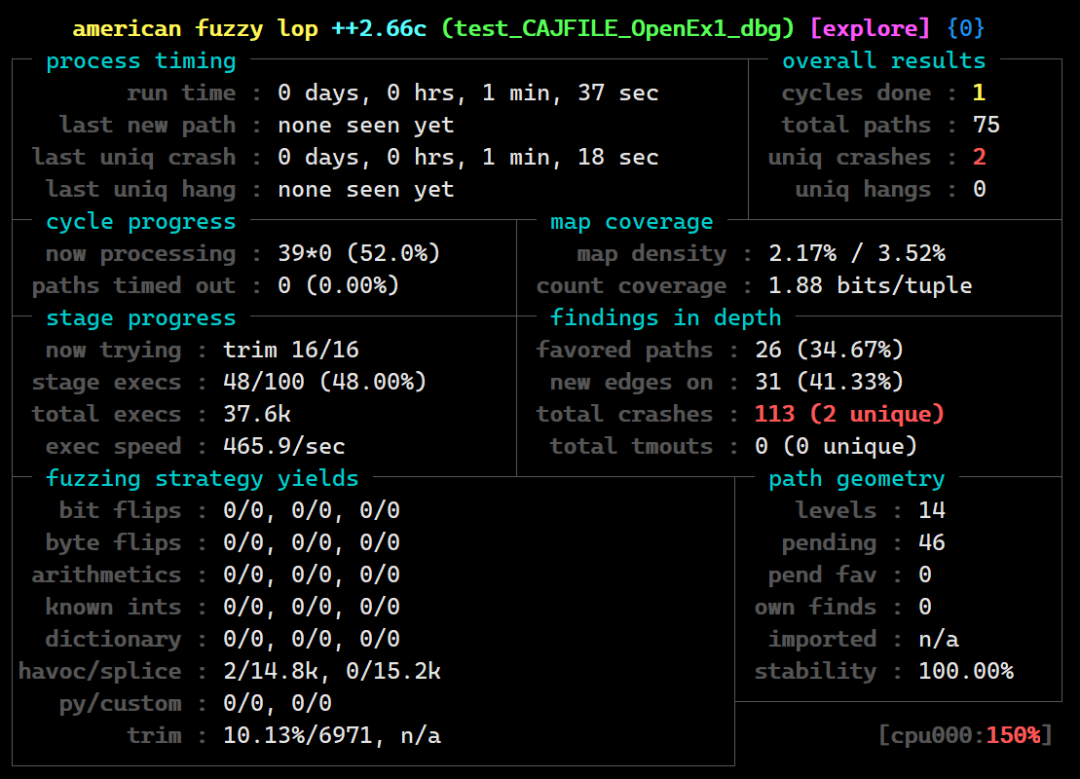
Fuzz UnCompressImage函数
在测试CAJFILE_OpenEx1时,去翻了一下libreaderex_x64.so里面的其他函数,在查看字符串时发现了一些源码路径。
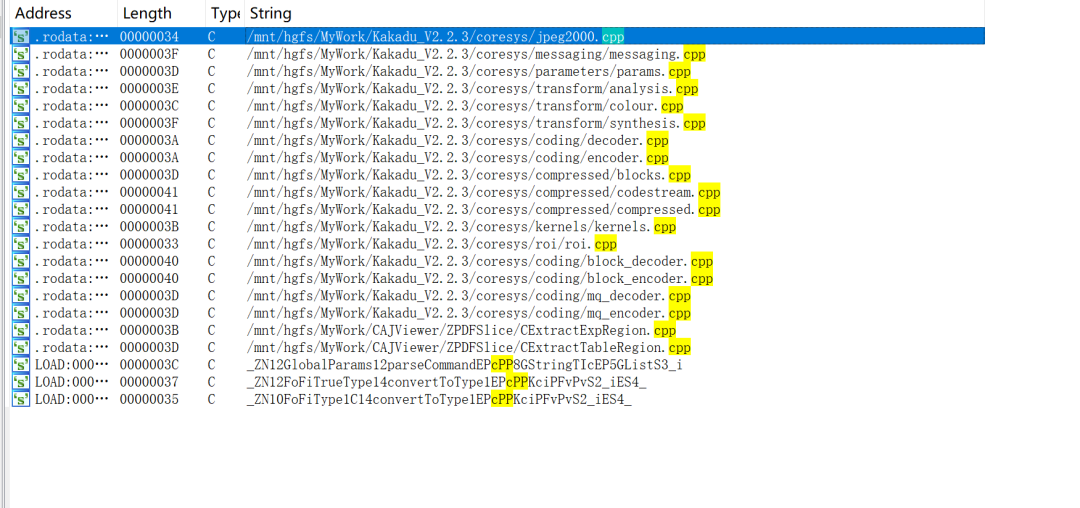
拿路径去网上搜了一下,发现是用到了Kakadu_V2.2.3这个开源库,这个库很古老了(2008年的),用于解析jpeg2000格式,版本老往往表示存在漏洞几率较大,而且jpeg2000格式很复杂,在其他软件中也发现了很多漏洞,于是下面仔细的看了下。
下载到这个库的代码,然后一路回溯发现libreaderex_x64.so应该是在?jpeg2000.cpp里面实现了部分代码,最后一路跟到了DecodeJpeg2000函数,并基于开源代码把DecodeJpeg2000的参数基本弄清楚了。
继续往上跟DecodeJpeg2000,找到了UnCompressImage函数,这个函数应该是解析图片数据的统一接口了。
CAJViewer在解析CAJ等文件时,如果文件中嵌入了图片数据时,就会会使用libreaderex_x64.so中的UnCompressImage函数来对图片数据进行解析。
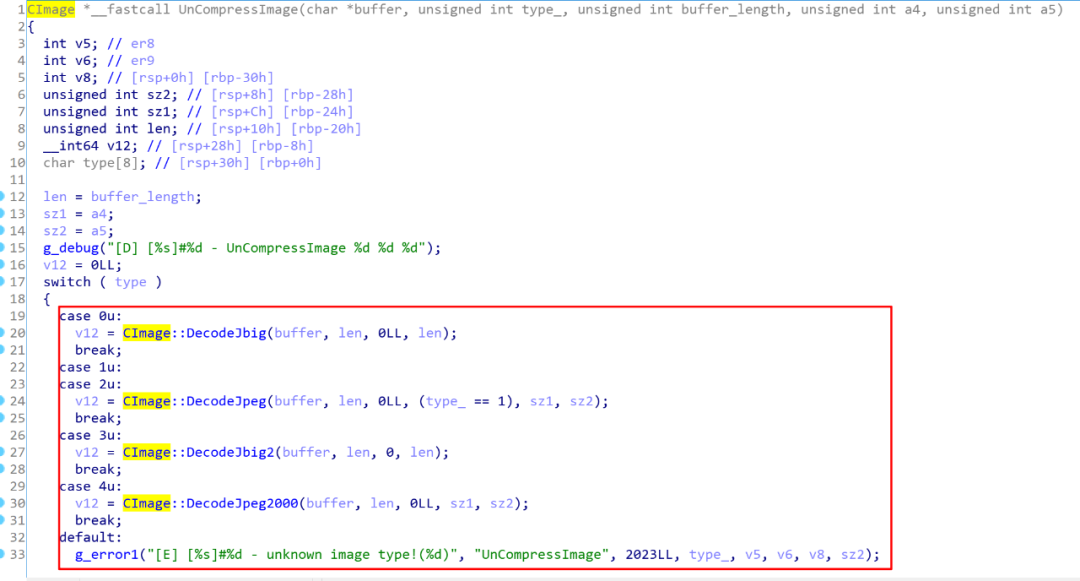
函数的参数信息如下:
buffer:?保存从文件中提取出的图片数据
type:?图片的类型
buffer_length:?图片数据的长度
剩下两个参数a4,a5:?个人猜测可能是需要将图片缩放的大小
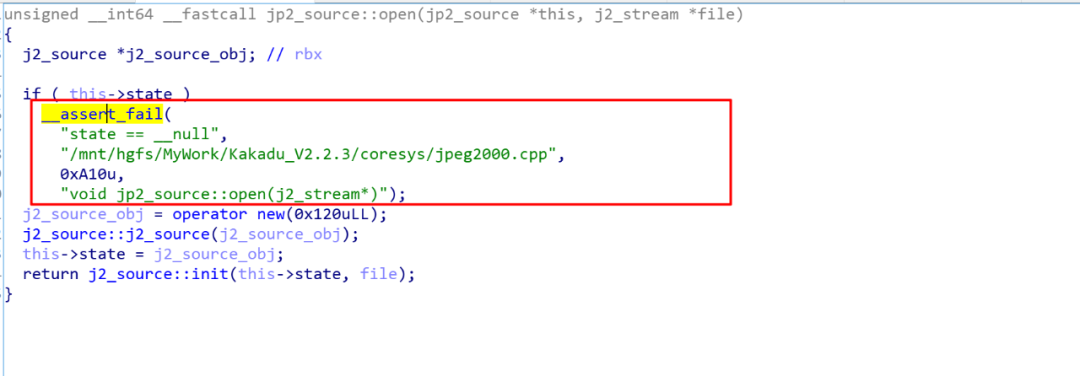
然后编写代码,my_init的主要逻辑和?CAJFILE_OpenEx1函数的一致,只是需要hook一些函数,避免比Fuzz识别为crash,比如在代码里面有很多assert,如果直接执行到这个函数的话,会被afl识别为crash.
int?my_assert_fail()
{
????printf("my_assert_fail\n");
????exit(1);
????return?0;
}
int?my_cxa_throw()
{
????printf("my_cxa_throw\n");
????exit(1);
????return?0;
}
void?my_init(void)
{
?........................................
?........................................
????plt_hook_function("libreaderex_x64.so",?"__assert_fail",?my_assert_fail);
????plt_hook_function("libreaderex_x64.so",?"__cxa_throw",?my_cxa_throw);
}
然后再main函数中调用目标函数
int?main(int?argc,?char?**argv)
{
????printf("main:%p\n",?main);
????int?f_sz?=?0;
????char*?buffer?=?read_to_buf(argv[1],?&f_sz);
????char?*ret?=?p_UnCompressImage(buffer,?4,?f_sz,?100,?100);
????return?0;
}
然后其他的操作和Fuzz?CAJFILE_OpenEx1函数时一致,只是环境变量需要重新设置
/home/hac425/AFLplusplus-2.66c/afl-fuzz?-m?none?-Q?-t?20000?-i?image_fuzz/?-o?UnCompressImageOutput?--?./test_UnCompressImage?@@
部分漏洞分析
CImage::LoadBMP 内存为初始化漏洞
Cajviewer For Linux 在解析BMP图片时会进入 CImage::LoadBMP 函数,该函数中存在内存未初始化漏洞。
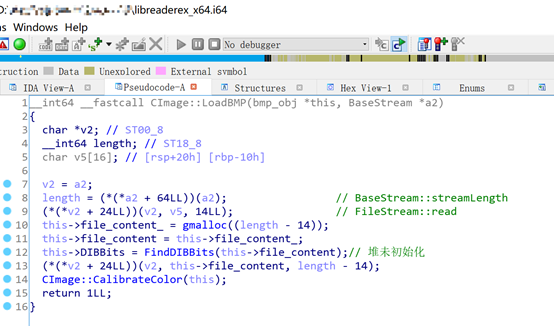
函数的流程如下
第8行,调用BaseStream::streamLength获取文件的大小。
第9行,调用FileStream::read从文件中读出14字节的文件头。
第10行,调用gmalloc分配内存用于存放文件的其他数据,这里实际上是直接调用malloc分配内存。
第12行,这里将分配的内存没有初始化直接传入FindDIBBits,该函数计算一个地址保存到this->DIBBits域。
第14行,这里会从this->DIBBits中读取数据,导致crash。
下面看看FindDIBBits的实现
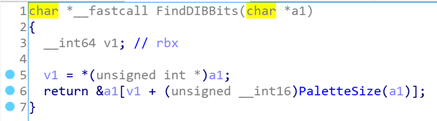
由于a1这个内存没有初始化,故v1有可能会很大,进而导致FindDIBBits会返回一个越界的地址。
然后在CImage::CalibrateColor中就会去访问这个内存。

CImage::DecodeJbig 越界读写漏洞
CajViewer在解析CAJ等文件时,如果需要解析文件中嵌入的图片数据时,会使用libreaderex_x64.so中的函数来对图片进行解析,其中如果带解析的文件类型为Jbig文件时,会进入CImage::DecodeJbig函数进行解析:
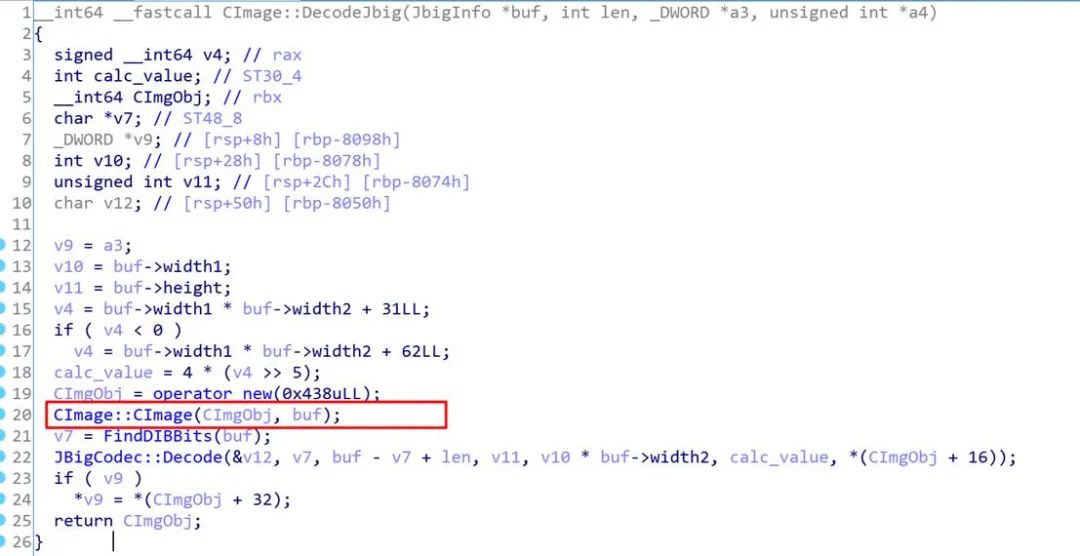
其中重要函数的参数和作用如下:
buf: 保存从文件中提取出的图片数据
len: buf的长度
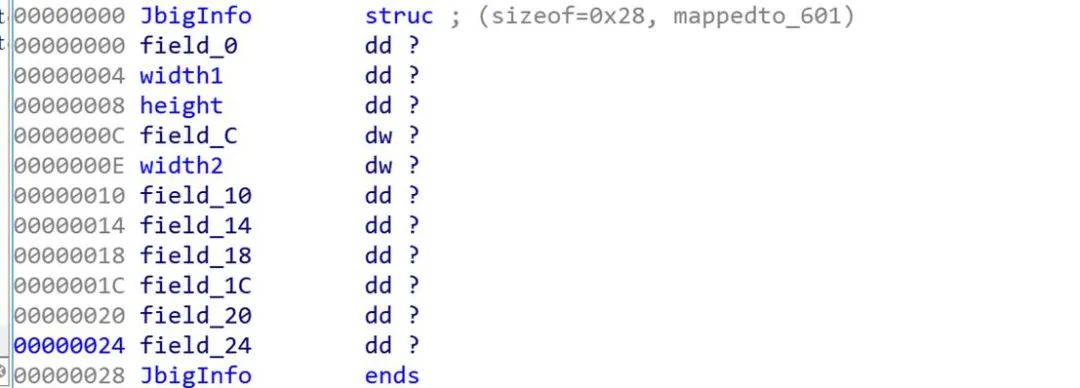
其中buf一开始是一个JbigInfo的结构,结构体的定义如下:
然后然后会进入CImage::CImage进行简单的文件解析。

首先使用JbigInfo中的字段计算一个sz, 然后使用 gmalloc分配内存,之后会使用memcpy 拷贝数据。
漏洞位于在计算sz时会导致整数溢出,进而导致会分配一个小于4LL * (1 << jbig_info->width2)的内存,然后在下面memcpy时会导致越界写。
此外整个过程没有校验jbig_info的长度,所以会导致越界读。
HN文件格式逆向
本节介绍对cajviewer中对HN文件格式的逆向分析并介绍如何编写相应的010editor模板,最后介绍通过分析如何构造POC,触发cajviewer在解析HN文件中的图片时存在的漏洞。HN文件是cajviewer支持的其中一种文件格式,这个文件类似于PDF,可以包含文字、图片等,下图是一个HN文件应用模板后的截图,具体的分析过程请看正文部分。
样例文件和010模板
https://github.com/hac425xxx/cajviewer-fuzz-data
https://github.com/hac425xxx/cajviewer-fuzz-data/releases/download/2020-8-2/sample.7z
解析文件头
基于上文的分析,我们知道cajviewer使用CAJFILE_OpenEx1函数来打开和解析一个文件,因此这个函数就是我们的分析入口.
CCAJReaderStruct?*__fastcall?CAJFILE_OpenEx1(char?*fpath,?char?*a2)
{
??file_type?=?CAJFILE_GetDocTypeEx1(fpath,?a2,?0LL);//?获取文档类型
??switch?(?file_type?)
??{
????case?1u:
????case?2u:
????case?8u:
????case?0xAu:
????case?0x1Bu:
??????ccaj_reader?=?operator?new(0x210uLL);
??????a2?=?v12;
??????CCAJReader::CCAJReader(ccaj_reader,?v12);?//?根据文件类型,构造Reader对象
函数首先调用CAJFILE_GetDocTypeEx1根据文件头和文件名返回一个表示文档类型的int值,对于样本文件来说会进入CCAJReader::CCAJReader?构造文档对象用于后续的解析。
通过分析类的构造函数可以大概了解对象的内存布局,比如通过new函数的参数可以知道?CCAJReader::CCAJReader?对象的大小为?0x210字节,下面看看类的构造函数

首先赋值虚表为?vtable for CCAJReader + 2,其实就是0xB19B0。

我们可以把这个抠出来,作为一个结构体以便后续分析
struct?CCAJReaderVtableStruct
{
??void?*_ZN10CCAJReaderD2Ev;
??void?*_ZN10CCAJReaderD0Ev;
??....................................
??....................................
??void?*_ZN7CReader16InternalFileOpenEPKc;
??void?*_ZN7CReader18InternalFileLengthEPv;
??void?*_ZN7CReader16InternalFileSeekEPvll;
??void?*_ZN7CReader16InternalFileReadEPvS0_l;
??void?*_ZN7CReader17InternalFileCloseEPv;
??void?*_ZN7CReader19InternalFileIsReadyEPKcijj;
};
然后设置CCAJReaderStruct的vtbl的类型为CCAJReaderVtableStruct*,这样再看虚函数调用时就可以很方便的定位到目标函数,其他用到的类也用这种方式逆向即可,继续往下看

CCAJReader::Open对文件进行初步解析,该函数实际会进入CAJDoc::Open读取文件内容并解析
首先这里调用BaseStream::getStream来创建一个stream对象,在cajviewer里面通过stream对象来从各种来源读取数据,比如网络、文件、内存等。

FileStream,创建完后就会调用FileStream::open和FileStream::seek打开文件并把文件指针重定向到文件开头。
CAJDoc::OpenNHCAJFile?进行具体的解析,第二个参数为0,在该函数里面首先会调用FileStream::read读取文件开头的0x88字节,并进行简单的判断
校验了前0x88字节的部分数据后,会再次读取 0x50字节的数据(0x10+0x40)

其中buffer_0x10.page_count表示文件中包含的页面数,这个通过观察下面的引用来推测,继续往下

这里首先校验buffer_0x10.field_0是否大于?0x18f?,如果大于0x18f就会再次读取一些内容作为元数据,然后会根据这个值设置item_size。

首先cajdoc->current_offset在前面读取内容时会进行调整,从cajdoc->current_offset开始就是表示CAJPage的信息数组,数组中每一项的大小为?cajdoc->item_size,类的构造函数的最重要的参数是第三个参数,表示该CAJPage在文件中的偏移,后面解析时会用到这些。
至此我们可以得到文件开头的格式为
0x88字节的hn_header
0x10字节的buffer_0x10;
0x40字节的buffer_0x40;
如果buffer_0x10.field_0?>?0x18F,后面还会跟一个?0x84字节的buffer_0x84?和?308?*?buffer_0x84.count?字节的内存
然后是buffer_0x10.page_count个page_info结构,每个结构的大小item_size为12或者20,item_size?根据buffer_0x10.field_0来判断
此时我们可以写一个简单的010editor模板,来解析文件头的数据
typedef?struct{
????ubyte?data[0x88];
}HN_FILE_HEADER;
typedef?struct{
????uint32?field_0;
????uint32?field_4;
????uint32?page_count;
????uint32?field_0xc;
}BUFFER_0X10;
typedef?struct{
????ubyte?gap[12];
????uint16?w1;
????uint16?w2;
????uint32?unknown_dword;
????uint32?dword_20;
????ubyte?data[40];
}BUFFER_0X40;
typedef?struct{
????ubyte?data[0x80];
????uint32?count;
}BUFFER_0X84;
local?uint32?item_size?=?12;
HN_FILE_HEADER?hn_header;
BUFFER_0X10?buffer_0x10;
BUFFER_0X40?buffer_0x40;
local?uint64?page_info_offset?=?FTell();
if(buffer_0x10.field_0?>?0x18F)
{
????BUFFER_0X84?buffer_0x84;
????local?uint64?cur_pos?=?FTell();????
????page_info_offset?=?308?*?buffer_0x84.count?+?cur_pos;
}
if(buffer_0x10.field_0?<=?0xC7)
{
????item_size?=?12;
}
else
{
????item_size?=?20;
}
FSeek(page_info_offset);
这里有几个关键的点,在010editor的模板中类型定义和local开头的局部变量不会导致文件指针的移动,当直接定义结构体变量时就会导致010editor读取文件内容并进行解析。
HN_FILE_HEADER?hn_header;
比如这个代表010editor会读取0x88字节到hn_header?并会移动文件指针,最后会使用FSeek(page_info_offset)把文件指针移动到page_info开始的位置,详细的教程和语法可以看下面的链接
https://bbs.pediy.com/thread-257797.htm
解析页面数据
解析完文件头的数据后会调用CAJPage::LoadPageInfo解析具体的页面信息
FileStream::seek到指定的文件偏移,然后读取item_size数据用于page_info,然后会把page_info的数据保存到当前page对应的结构体里面,?page_info的结构如下struct?page_info
{
??int?file_offset;??//?page数据在文件中的偏移
??int?size;?//?page数据的大小
??__int16?pic_count;??//?page中的图片个数
??__int16?field_A;
??__int64?field_C;
};
然后会跳到page_info.file_offset,读取page数据的前0x20个字节,然后从里面解析了一些数据,用途不明。
加载完page_info后会调用CAJPage::LoadPage加载页面的文本数据

这里首先跳转到page数据所在的文件偏移,然后把页面的数据读出来

这里对文件内容解析,首先从头8个字节里面解析出当前page的heigh和width,然后后面是具体的文本数据,然后判断文本数据开头是否有COMPRESSTEXT,如果是表示文本数据是压缩过的会使用UnCompress对文本数据进行解压。

解析完page的文本数据后会把page的图片数据在文件的起始偏移记录在page->pic_info_foffset里面,解析完之后会进入CAJPage::LoadPicInfo加载图片的元数据
这里会根据page->page_info.pic_count创建CAJ_FILE_PICINFO数组,数组中的每个元素为pic_info结构,结构体定义如下
struct?pic_info_struct
{
??int?type;??//?图像类型
??int?offset;?//?图像数据在文件中的偏移
??int?size;?//?图像数据的大小
};
通过这个函数每个page的图片信息会保存到page->caj_picinfo_list里面,然后会在CAJPage::LoadImage里面对页面的某个图片数据进行解析
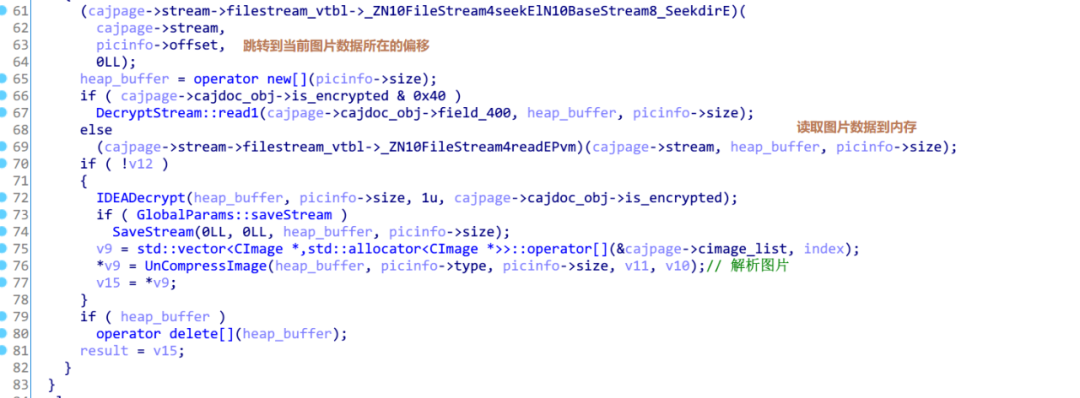
函数的流程也简单,首先根据图片的索引在cajpage->caj_picinfo_list里面找到图片的picinfo结构,然后根据该结构读取图片的数据并使用UnCompressImage对图片数据进行解析。
至此我们可以得到page数据的组织方式如下
首先在文件头后面是buffer_0x10.page_count个page_info结构,page_info结构里面记录了页面的数据所在的文件偏移、内容的大小以及页面包含图片的个数,然后根据这些信息可以得到页面的文本数据和图片数据(图片数据紧跟在文本数据的后面)。
这部分的010模板如下
typedef?struct{
????uint32?type;
????uint32?file_offset;
????uint32?size;
????local?uint64?backup_offset?=?FTell();?
????FSeek(file_offset);??//?move?to?data?offset
????ubyte?pic_data[size];???//?page_data
????FSeek(backup_offset);??//?move?back
}PICINFO;
typedef?struct?(uint32?size){
????PAGE_CONENT_HEADER?page_hdr;
????local?char?tmp[12];
????ReadBytes(tmp,?FTell(),?12);
????if(Memcmp(tmp,?"COMPRESSTEXT",?12)?==?0)
????{
????????char?compress_sig[12];
????????uint32?decompressed_size;
????????char?compressed_data[size?-?12?-?4?-?sizeof(PAGE_CONENT_HEADER)];
????}
????else
????{
????????ubyte?page_text_content[size?-?sizeof(PAGE_CONENT_HEADER)];???//?page_data
????}
????
}PAGE_CONTENT;
typedef?struct?_PAGE_INFO_ITEM{
????uint32?file_offset;
????uint32?size;
????uint16?pic_count;
????uint16?field_A;
??
????if(item_size==20)
????{
????????uint64?field_C;
????}
????local?uint64?backup_offset?=?FTell();?
????
????FSeek(file_offset);??//?move?to?data?offset
????
????PAGE_CONTENT?page_content(size);
????
????local?uint32?i?=?0;
????while(i?<?pic_count)
????{
????????PICINFO?pic_info;
????????i++;
????}
????FSeek(backup_offset);??//?move?back
}PAGE_INFO_ITEM;
解析完后的效果图如下:

构造POC的技巧
UnCompress会对页面文本数据进行解压,简单的看下UnCompress的实现我们可以知道该函数调用了zlib 1.1.3版本解压文本数据,这个版本有很多漏洞,如果我们想触发UnCompress的漏洞就可以把文件中压缩文本数据替换成zlib的poc数据即可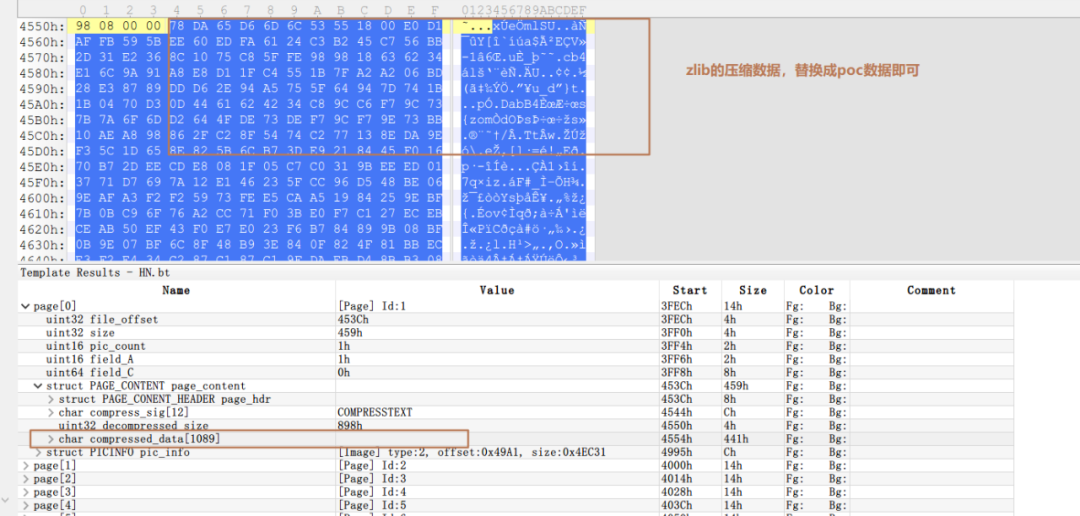

总结
本文介绍了如何分析一个软件并使用afl qemu模式来测试闭源二进制,并分析了其中的一些漏洞,最后介绍了逆向HN文件格式的过程,并介绍如何编写010editor模板来辅助poc构造。
附录
https://github.com/hac425xxx/cajviewer-fuzz-data
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 OPPO安全应急响应中心
OPPO安全应急响应中心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675