
Flink 在又拍云日志批处理中的实践

日前,由又拍云举办的大数据与 AI 技术实践|Open Talk 杭州站沙龙在杭州西溪科创园顺利举办。本次活动邀请了有赞、个推、方得智能、又拍云等公司核心技术开发者,现场分享各自领域的大数据技术经验和心得。以下内容整理自又拍云资深开发工程师张召现场分享:
张召,资深开发工程师,目前负责又拍云 CDN 的刷新预热、日志处理和运维平台开发。熟悉 OpenResty,在 Web 开发领域经验颇丰,目前热衷研究大数据处理相关技术。
大家好,我是来自又拍云的张召,今天主要分享又拍云多数据源日志处理选型 Flink 的考量,以及 Flink 落地过程中遇到的问题和解决方案。
为什么用 Flink 做批处理
在选用 Flink 前,我们对日志批处理的整个业务需求分为三步:数据源采集、日志处理、结果的保存。我们的日志量在 100G/h,单机服务处理速度慢、扩容不方便,一些相似的需求都是以编码形式完成的。另外,数据处理流程复杂,需要在多个服务间流转,迫切需要一个方案来解决问题。
前期我们调研了数据库,发现数据库里没有多维度的反复总结和挖掘的功能,所以我们放弃了选用数据库的方案,选用 MapReduce 里的 hadoop 这条组件。实际生产中发现它经常在写入的时候出现一些错误,导致无法做一些聚合的操作。接着我们选择了 Spark,新的问题又出现了:提交任务时,Restful API 接口的支持不全面;web 控制台中虚拟 IP 无法访问内部。
基于以上原因,我们需要一个更好的解决方案。通过比较之后,我们发现了 Flink。Flink 规避了前面所有的问题,后面还提供一套完整的 Restful API。不仅能够渲染出这个页面,还可以通过 Submit NewJob 直接提交任务。同时,我们对老服务升级的过程中,逐渐明白了我们日志数据的特点,以及当前我们需要挖掘日志数据的哪些方面。在盘点了手头上可调用的资源后,我们希望部署的服务整个系统是可观测、可维护的,所以基于以上各种原因,最终我们放弃 Spark 方案,选择了 Flink 。
Flink 基础知识
Flink 组件栈
如下图所示,这是一个分布式系统,整体也比较简单。最左边的 Flink Client 支持客户端现在的提交方式,后面会谈到它支持提交 Restful API 接口以及通过命令行等 5 种手段向这个 Job Manager 提交任务。
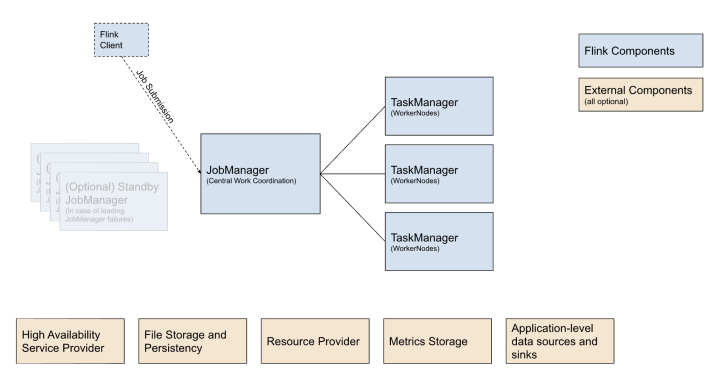
Job Manager 是分布式系统里的 master 节点,master 节点拿到数据之后会对架包进行分析,而后把相关其他信息给传送到对应的 TaskManager 节点。TaskManager 节点拿到信息后才真正执行Job,Job Manager 最主要的作用就是解析这个图以及维持整个集群,比如心跳、资源调度、HA 高可用、文件存储等,这是 Flink 提交任务 runtime 的过程。
接着看 Flink 静态的整体设计,底层是部署部分,稍后展开讲。中间的核心部分是 Runtime,分别封装了两个不同的 API:DataStream 是流处理,是现在 Flink 用的最多的场景;DataSet 是我们用到的批处理方式。虽然现在 Flink 号称支持流批一体处理,但是它目前版本两个接口是分开的,今年 12 月发的 1.12 版本已经不鼓励用 DataSet 相关的 API,这部分功能合到了 DataStream 里。但由于我们部署的版本还在 1.1,没有升级,所以我们还没有把这些 Job 迁到 DataStream 上去。
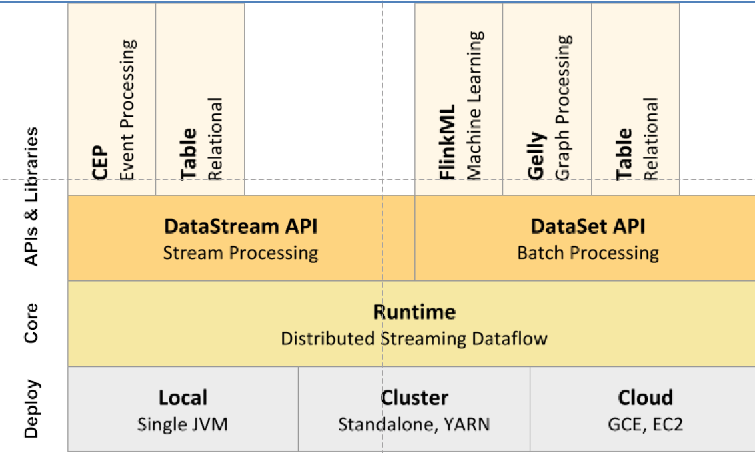
接下来我们探索最上层的 tabl circle,但使用的最终效果并不好,因为无论是文档里,还是代码里写的支持限度是比较有限的。比如去执行 circle,但 circle 想把最终结果输出到 PG 里面的时候,它就出现了一个 bug,它 PG 的数据库最终拼出来的地址是错的,它的 host 和 pot 少了一个反斜线。这个 bug 非常简单,但是现在都没有修复。所以我认为最上层这部分可能测试的还不完善,也不是很稳定。所以我们最终代码的实现和业务集中编写也是放在调用的 DataSet API 这部分来做的。
另外我们还做了些小的工作,我们基于又拍云存储系统,扩展了它的相关功能,能够支持 Flink 的处理结果直接输出到云存储上,对整体代码起到简化作用。
JobManager 和TaskManager
JobManager 的作用主要体现在里面的组件。比如 DataflowGraph 可以把 Flink 客户端提交的架包分析成一个可以执行的 graph,分发到下面的 TaskManager 节点里面去。另外一个我们比较关注的组件是 Actor System,它是由 ScadAKKA 异步网络组件实现的。我们后期部署时发现有很多 AKKA time out 这类问题,这意味着 JobManager 组件和 TaskManager 组件进行通信的时候出现了问题。

再看 TaskManager 主要关注的概念,当 TaskManager 和外界系统发生交互时,它用的不是 actor 模型,actor 模型主要是异步通信,强调的是快。它和外部通信时,TaskManager 用的是 Netty,输入数据更加的稳定。
这里要着重关注一下 Task Slot 概念,一些分享的最佳实践案例提到 TaskManager 里的 slot 最好和当前机器 CPU 核数保持 1:1 的设置。我们最初按照1:1 设计跑一些小的 job 的时候很好,但数据量上升时经常会出现一些 time out 的问题。原因在于 Kubernetes 提供的 CPU 只是一个 CPU 的实践片,不能等同物理机上的 CPU,当在 TaskManager 下部署多个的时候,虽然它们的内存会被分摊掉,但 CPU 却是共享的。在这种状况下,整个 TaskManager 就不是特别稳定。所以我们最终设置大概在 1:4 或 1:8。具体数据应该是从当前环境内的网络状况和经验值来确定的。
Flink 部署
刚开始部署 Flink 时,我们是比较懵的,因为 Flink 部署文档里介绍了很多模式,比如部署在 standalone,Kubernetes、YARN 或者是 Mesos,还有一些应用实践都比较少的模式。虽然我们在云平台上搞一个 Kubernetes 的操作,但我们做不到直接使用 Kubernetes托管式的服务,所以最终采用的是 Standalone on Docker 模式,如下图所示:
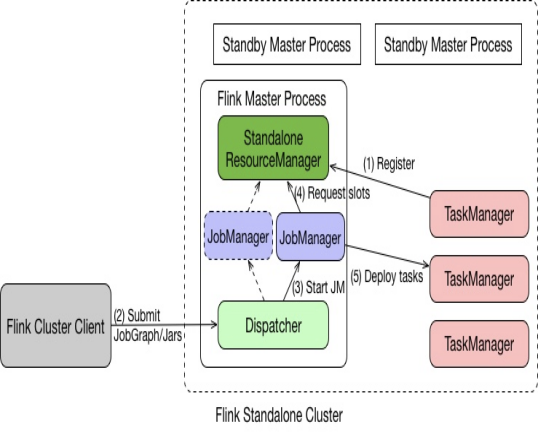
△ Standalone on Docker 模式
Standalone 模式下,Master 和 TaskManager 可以运行在同一台机器或者不同的机器上;
Master 进程中,Standalone ResourceManager 的作用是对资源进行管理。当用户通过 Flink Cluster Client 将 JobGraph 提交给 Master 时,JobGraph 先经过 Dispatcher;
当 Dispatcher 收到请求,生成 JobManager。接着 JobManager 进程向 Standalone ResourceManager 申请资源,最终再启动 TaskManager;
TaskManager 启动后,经历注册后 JobManager 将具体的 Task 任务分发给 TaskManager 去执行。
Flink 提交任务
Flink 提供丰富的客户端操作提交任务和与任务进行交互,包括 Flink 命令行、Scala Shell、SQL Client、Restful API 和 Web。
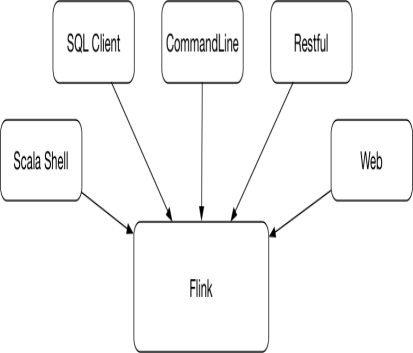
最重要的是命令行,其次是 SQL Client 用于提交 SQL 任务的运行,以及 Scala Shell 提交 Table API 的任务,还提供可以通过 http 方式进行调用的 Restful 服务,此外还有 Web 的方式可以提交任务。对我们非常实用的是 Restful API 功能。目前的服务里,除了拉取原始日志这块代码没有动,其他一些 go 自研组件的统计、排序等后续的操作现在统统不用了,直接调用 Flink 相关的接口。
Flink 是一个异步执行的过程。调用接口传递任务后,紧接着会把 taster 的ID 返还给你,后续的操作里面可以通过这个接口不断去轮循,发现当前任务的执行情况再进行下一步决策。综合来看,Flink 的 Restful API 接口,对于我们这种异构的、非 JAVA 系的团队来说还是非常方便的。
使用批处理时遇到的问题
网络问题

当我们逐步迁移日志服务时,开始日志量比较小,Flink运行的非常好;当发现它负载不了,出现 GVM 堆错误之类的问题时也只需要把相关参数调大就可以了,毕竟云平台上资源还是比较富裕的,操作也很方便。
但当我们越来越信任它,一个 job 上百 G 流量时,整个 tap 图就变成一条线,网络问题就出现了。此前有心跳超时或者任务重试之类的问题,我们并不是特别在意,因为失败后Flink 支持重试,我们通过 restful 接口也能够感知到,所以失败就再试一次。但是随着后面的任务量加大,每运行一次代价就越来越大了,导致提交的越多当前整个集群就会越来越恶化。
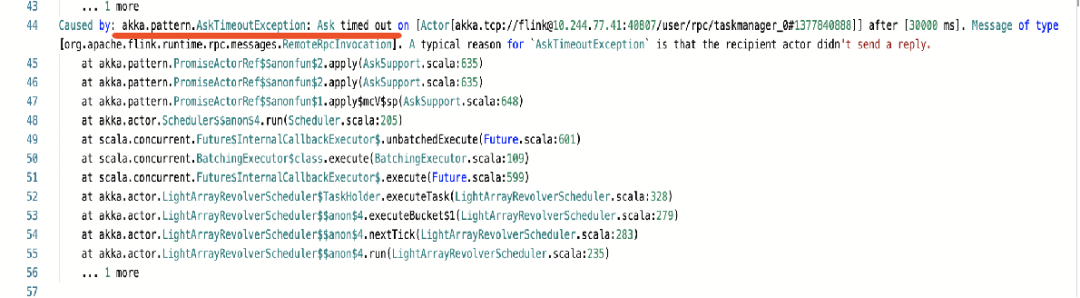
当这种上百 G 的日志批处理任务放进去后经常会出现三类错误:最上面红线画出的akkaTimeout 问题是前面讲的 JobManager 和 TaskManager 相互通信出现的问题;像心跳超时或链接被重置的问题也非常多。
为什么我们没有完全把这个问题处理掉呢?是因为我们看了一些阿里的 Flink on K8S 的经验总结。大家有兴趣也可以看一下。

这篇文章中面对同样的问题,阿里团队提出将网络放到 K8S 网络虚拟化会实现一定的性能,我们参考了这种解决方案。具体来说,需要对 Flink 配置进行一些调整,另外有一些涉及 connection reset by peer 的操作:
调整 Flink 配置参数
调大网络容错性, 也就是配置参数中 timeout 相关的部分。比如心跳 5 秒一次超时了就调成 20 秒或者 30 秒,注意不可以完全禁掉或者调到很大;
开启压缩。如果是以纯文本的形式或者不是压缩包的形式上传,Flink ? ? 会并行读取文件加快处理速度,所以前期倾向上传解压后的文本;当网络开销变大后,我们就选择开启文件压缩,希望通过 CPU 的压力大一点,尽量减少网络开销。此外,TaskManager 或者是 JobManager 和 TaskManager 之间进行通信也可以开启压缩;
利用缓存, 如`taskmanager.memory.network.fraction` 等,参数配置比较灵活;
减少单个 task manager 下 task slots 的数量。
Connection reset by peer
不要有异构网络环境(尽量不要跨机房访问)
云服务商的机器配置网卡多队列 (将实例中的网络中断分散给不同的CPU处理,从而提升性能)
选取云服务商提供的高性能网络插件:例如阿里云的 Terway
Host network,绕开 K8s 的虚拟化网络(需要一定的开发量)
由于 Connection reset bypeer 的方案涉及到跨部门协调,实施起来比较麻烦,所以我们目前能够缓解网络问题的方案是对 Flink 配置进行一些调整,通过这种手段,当前集群的网络问题有了很大程度的缓解。
资源浪费
standlone 模式下,整个集群配置资源的总额取决于当前所有 job 里最大的 job 需要的容量。如下图所示,最下面不同任务步骤之间拷贝的数据已经达到了 150G+,能够缓解这种问题的办法是不断配置更大的参数。

但由于 Flink 这一套后面有一个JVM 的虚拟机,JVM 虚拟机经常申请资源后并没有及时释放掉,所以一个容器一旦跑过一个任务后,内存就会飙上去。当不断拉大配置,且配置数量还那么多的情况下,如果我们的任务只是做一个小时级的日志处理,导致真正用到的资源量很少,最终的效果也不是很好,造成资源浪费。
job 卡死
在容量比较大后,我们发现会出现 job 卡死,经常会出现量大的 job 加载进行到一半的时候就卡住了。如下图所示(浅蓝色是已经完成的,鲜绿色表示正在进行的),我们试过不干预它,那么这个任务就会三五个小时甚至是八个小时的长久运行下去,直到它因为心跳超时这类的原因整体 cross 掉。
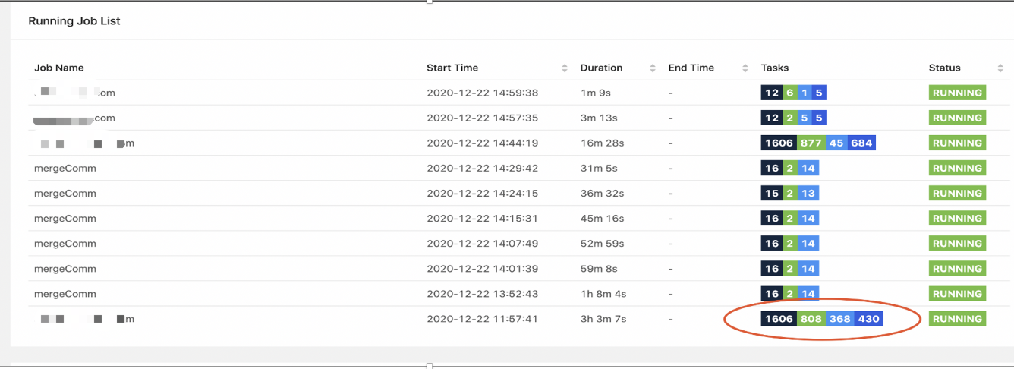
这个问题目前没有完全定位出来,所以现在能采取的措施也只是通过 restful 接口检查任务的时候,给它设置一个最大的阈值。当超过这个阈值就认为这个任务已经完全坏掉了,再通过接口把它取消掉。
Flink 带来的收益
下图所示是日志处理的某一环节,每一个小方块代表一个服务,整个服务的链路比较长。当有多个数据源加载一个数据时,它会先 transfer porter 放到又拍云的云存储里,由 log-merge 服务进行转换,再根据当前服务的具体业务需求,最终才会存到云存储或者存到 redis。

任务和任务之间的衔接是通过两种方式:一种是人为之间进行约定,比如我是你的下游组件,我们约定延迟 3 个小时,默认 3 个小时后你已经数据处理好,我就去运行一次;第二种是用 ASQ,我处理结束后推送消息,至于你消费不消费、消费是否成功,上游不需要关心。虽然原本正常的情况下服务运行也很稳定,但一旦出现问题再想定位、操纵整个系统,追捕一些日志或重跑一些数据的时候就比较痛苦。这一点在我们引入到 Flink 后,整体上有非常大的改进。
目前只有任务管理部分是复用了之前的代码,相当于采集板块。采集好数据直接向 Flink 提交当前的 job,Flink 处理好后直接存进云存储。我们的任务管理主要分两类功能,一个是采集,另一个是动态监控当前任务的进行结果。总的来看,重构后相当于形成了一个闭环,无论是 Flink 处理出现问题,亦或是存储有问题,任务管理系统都会去重跑,相当于减少一些后期的运维工作。
总结
选择 standalone 系统部署一套Flink 系统,又要它处理不是太擅长的批处理,且量还比较大,这是非常有挑战性的。充满挑战的原因在于这不是 Flink 典型的应用场景,很多配置都做不到开箱即用,虽说号称支持批处理,但相关配置默认都是关闭的。这就需要调优,不过很多文档里大多会写如果遇到某类问题就去调大某类值,至于调大多少完全靠经验。
尽管如此,但由于当前 Flink 主推的也是流批一体化开发,我们对 Flink 后续的发展还是比较有信心的。前面也讲了 Flink1.1 版本中,dateset 批处理的 API 和 stream的 API 还是分开的,而在最新版本 1.12 中已经开始融合在一起了,并且 dateset 部分已经不建议使用了。我们相信沿着这个方向发展,跟上社区的节奏,未来可期。
以上是张召的全部分享内容,回看视频请点击↓↓阅读原文↓↓
快 来 找 又 小 拍

推?荐 阅 读 


设为星标

更新不错过
设为星标
更新不错过
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
![一栗莎子 友友们新年快乐 我的假期已经结束啦[太开心]](https://imgs.knowsafe.com:8087/img/aideep/2022/2/6/42d4d5879c18143fb0bf079ad56f5779.jpg?w=250)
![曾雪瑶 20220222 今天是最有爱的一天[给你小心心] ](https://imgs.knowsafe.com:8087/img/aideep/2022/2/23/b0e4794f059fac7fe6ad77e884a092a6.jpg?w=250)




 又拍云
又拍云
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675