
来源 |?微软研究院AI头条(ID:MSRAsia)
编者按:2020年9月,微软亚洲研究院发布了多智能体资源优化平台“群策 MARO”,并在 Github 上开源。近日,MARO 更新了0.2版本,新版本进一步完善了多项功能,提升了使用体验。作为一个面向多行业横截面上的全链条资源优化 AI 解决方案,MARO 平台可支持多种预设定的资源优化任务,例如航运网络中的空集装箱调度问题、共享单车服务中的单车调度问题、云平台上的虚拟机分配问题等,同时也支持用户利用核心组件,快速地定义高效的场景。不仅如此,MARO 还提供了全栈的强化学习支持,包含常用算法以及相关的分布式训练。本文将通过构造一个简单的共享单车场景,来帮助大家理解 MARO 的核心功能和逻辑,以及其与环境交互所实现的优化策略。*本文仅介绍场景设计逻辑和与环境进行交互的关键代码,完整的 Notebook 代码可以参考 Notebook (https://github.com/microsoft/maro/blob/master/notebooks/articles/simple_bike_repositioning.ipynb)。共享单车是大家非常熟悉的出行方式,既健康又低碳环保,但是经常使用共享单车的小伙伴们肯定遇到过这样的苦恼:早上稍微晚些出门,小区门口就空空荡荡,没有一辆可用的单车,而在地铁站入口则会发现大量的单车几乎把道路堵得水泄不通;等下班从公司去地铁站的时候,同样的状况再次上演。这种单车分布的不均衡事实上是由出行需求的不均衡所导致的。如果任由其发展会显著影响单车的使用效率以及用户体验。想要打破这种不平衡,必须通过主动调度单车资源的方式来解决,即在合适的时间把单车从需求小的地方调度到需求大的地方。那么,如何设计有效的单车平衡调度策略来解决单车需求的不平衡呢?接下来让我们将从一个简易的问题出发,看看如何使用“群策 MARO”来构造模拟场景,并基于简单规则进行调度尝试。为了简化问题,可以考虑只有四个单车停放站点的情况,这里用 {s_i∣i=0,1,2,3} 来表示单车站点。如图1左侧所示,s_i 和 s_j 之间的有向边代表会有从 s_i 到 s_j 的单车需求,其具体的需求量是由一个时间 t 上的函数 F_ij (t) 决定的。不同站点之间的需求明显是不一样的,若模拟这一点则要求设计多种需求函数,图1右侧即为这些需求函数的曲线示例。可以发现,对于 s_0 和 s_2,F_02 (t) 和 F_20 (t) 呈现对称的周期性转换,而其他站点对之间的需求函数相对稳定。具体而言,对于任意一个时间点,F_02 (t) 和 F_20 (t) 中仅有一个值可以大于0,即 s_0 和 s_2 之间仅有一个方向的单车需求数量大于0,在需求函数周期的前半段,F_02 (t) 会从0逐渐增长到峰值再降回0,而在需求函数周期的后半段,则换做 F_20 (t) 从0逐渐增长到峰值再降回0。对于 s_1 和 s_3 来说,F_13 (t) 和 F_13 (t) 基本相当,仅在极少数时刻会存在小的数值差异。而 F_01 (t) 和 F_32 (t) 则表现为一个常数函数,取值固定且相等。在这样的单车需求设定下,想要最大化这个单车世界内的单车需求满足率,s_0 和 s_2 需要依据给定时间段内其供需角色的不同,将富余的单车从没有单车需求的站点调度到单车需求多的站点(如:t=15时,将单车从 s_2 调度到 s_0,而 t=50 时,将单车从 s_0 调度到 s_2)。同时,由于 s_1 和 s_3 之间的供需基本守恒,在无法准确预见未来单车需求量的情况下,无需额外的单车调度。对于 F_01 (t) 和 F_32 (t) 这两个需求函数所带来的单车稳定地被从行程起始站点运往目的站点的现象,可以规律地将单车从行程目的站点运往起始站点。
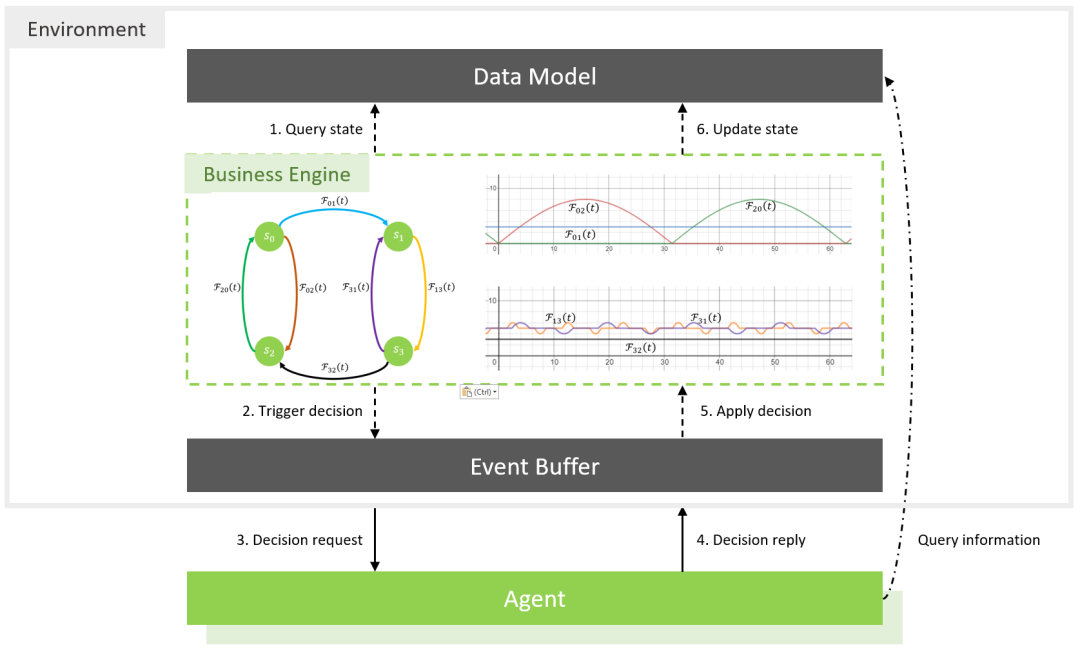
为了方便用户自己定义场景,微软亚洲研究院的研究员们在 MARO 中采取了模拟器(Simulator)、业务引擎(Business Engine)和智能体(Agents)分离的设计。- 模拟器是用来承载整个场景的运行容器,它衔接着业务引擎和智能体。其中有两个关键模块:数据模型(Data Model)和事件缓存(Event Buffer),前者用于高效地存储整个环境的结构化数据,后者主要用来处理场景的业务事件以及智能体的决策事件,进而推动环境运行;
- 业务引擎维护的是整个场景的业务逻辑,包括修改环境数据、触发事件、执行智能体的动作等等,每个场景需要有自己的业务引擎,它也是自定义场景中主要需要实现的模块;
- 智能体则主要负责对动作事件响应,并返回合适的动作。
在这个简易的单车调度场景中,可以把主要业务逻辑归为两类:由单车需求触发的单车消耗与回收,以及由此带来的单车移动;为了优化单车使用率,提升单车需求满足度而主动驱动的单车调度。其中,单车需求的处理逻辑如图2所示:在每个时间点上,业务引擎会按照预先设定的单车需求曲线生成特定的单车使用请求,当站点存在空闲单车能满足该请求时,单车将被消耗(模拟器将记录由此引发的状态变化)并记录为一次订单满足(fulfillment)。在特定时间之后该单车会到达请求的目的地站点,成为目的地站点的可用单车(模拟器将再次对各站点状态进行更新);若请求产生时站点空闲单车不足,对应的单车请求将得不到满足,会被记录为一次请求未满足(shortage)。图3则展示了单车调度逻辑:在每个时间点上,业务引擎会检查各个站点的剩余单车数量,当余车不足时,业务引擎会生成并抛出一个单车调度请求事件。模拟器接收到这一请求事件后会将此事件转发给决策方,即智能体(Agent)。智能体会依据当前系统的状态,按照自己的策略给出执行决策——(a,b,n) 从 s_a 调度 n 辆单车运往 s_b。被调度的单车会在特定时间后到达目的地站点,成为目的地站点的可用单车,在这一过程中模拟器负责对相关站点的状态进行更新。上述是整个场景的运行逻辑,也就是业务引擎需要实现的内容,具体代码可参考 Notebook(https://github.com/microsoft/maro/blob/master/notebooks/articles/simple_bike_repositioning.ipynb)中 SimpleCitibikeBusinessEngine 类。在完成业务引擎的实现之后,下面就可以利用 MARO 提供的接口,实例化一个环境示例,并与之交互。具体过程如下图代码所示:首先是创建环境,参数分别为环境执行总时间和业务逻辑引擎。环境在执行过程中的所有状态信息都存储在 snapshot_list 中。其次是创建策略对象,策略对象可以是任意类的实例,只需在环境需要执行动作时提供决策即可。接下来是与环境的交互,这里用一个 while 循环实现,即执行环境的 step 操作直至环境结束。当调用 step 函数时,环境会持续推进业务逻辑,直到需要执行动作。此时,需要调用策略对象获得动作。该动作是一个三元组,包括调度源站点 A、调度目的地站点 B 和调度数量 x,描述了从站点 A 到站点 B 运送 x 辆车的调度操作。此外,动作为 None 代表不做任何调度。接下来将实现三种调度策略,分别是不做任何调度(no action)、基于规则的调度(rule based)和基于统计数据的调度(statistics based)。图4展示了单车总需求和这三种策略下的各个时刻单车缺口数量曲线。图4:各时刻单车总需求和三种策略下单车缺口数量曲线在策略的具体实现上,用户可以定义一个类,并重载__call__(event) 函数,在该函数中根据环境的信息处理当前事件。首先可以看一下如果不做调度会产生多少缺箱。这个策略非常简单,只需要对任何的事件返回 None 值即可。整个环境跑下来总的单车需求为2096,单车需求缺口为945。图4展示了每个时间点的单车缺口曲线。下面再通过对环境内部的逻辑观察,给出一个合理的基线。为了叙述方便,定义第 i 个站点为 s_i。通过观察可以发现,如果把系统分为左右两个子集,即 {s_0,s_2 } 和 {s_1,s_3 },从左子集指向右子集的需求(由函数 F_01 定义)和从右子集指向左子集的需求(由函数 F_32 定义)刚好抵消。这意味着,如果两个子集各自能够提供足够多的单车满足其内部需求,那么只需要分别在两个子集内部调度即可。首先考虑右子集 {s_1,s_3 }。由于外界的单车总是从 s_1 流入,并从 s_3 流出,因此只需要将所有从 s_1 流入的单车都发往 s_3 即可。为了简单起见,在每次调度时保留固定数量的单车而将剩下所有单车发给 s_3。设保留数量为常数 R_13。对于左子集 {s_0,s_2 } 而言,情况要稍微复杂一些。由于左子集内部的需求函数 F_02 和 F_20 是以 20π 为周期的函数,因此可以以周期为单位进行分析。在前半周期,左子集内部只有从 s_0 指向 s_2 的需求,且外界的单车总是从 s_2 流入,并从 s_0 流出。s_0 只出不进,而 s_2 只进不出。因此在这个期间,将所有 s_2 的单车都运往 s_0 即可。在后半周期,左子集内部只有从 s_2 指向 s_0 的需求。由于 s_0 还需要满足 F_01 的需求,所以 s_0 需要保留一部分单车,并将剩余的全部运给 s_2。同样,设此保留数量为 R_02。当该算法在系统中存在单车数量为0的站点时触发。算法需要从环境中获取当前每个站点的单车数量,再通过上述规则返回调度结果。调度结果以三元组 (s_i,s_j,x) 的形式给出,表示从站点 s_i 运输 x 个单车到站点 s_j。在代码中设置:R_13=5,R_02=5。用户可以通过 event 的 station_index 成员变量获取当前需要单车的站点,还可以通过环境的 tick 变量获得当前时刻,通过 snapshot_list 获得各个站点的状态。这里简单介绍一下 snapshot_list 的接口:通过键值 “station” 可以获得每个站点在历史上每个 tick 的属性值,属性值由三个部分索引组成,按顺序分别为时间 tick、站点下标 index 和属性名,若其中任一索引省略,那么接口将返回该索引的所有值。例如,上述程序中 [self.env.tick::”bikes”] 代表获得在环境当前 tick 所有站点的单车数量。执行该策略最后总的单车短缺数量为107,各时刻的缺口数量可以参见图4。在实际场景中我们并不能实时了解真实的用车需求,用车需求时时刻刻都在发生变化,无法通过固定的策略获得很好的调度效果。因此可以采用一种自适应的方法,该方法的思想也很简单:如果人在不清楚用车需求的情况下做决策,最直接的办法就是,先让系统运行一段时间,观察哪个站点缺车就往哪个站点运输。这种方法虽然存在延迟响应的问题,但执行起来往往简单而有效。具体而言,研究员们统计了每个站点缺车数量的指数衰减累积量,并以此衡量站点的缺车程度。每次系统发现缺车点,并触发调度动作,就从最不缺车的站点运单车过去。此外,由于系统可能在同一个 tick 多次触发调度,为了防止一个站点多次被选择,所以每次选择都会降低该站点的优先级。具体代码可参考 Notebook 内容。其中的超参可以通过简单的网格搜索进行优化,找到最优的超参组合:{decay_factor=0.8,weight=0.8},此时单车缺口为278。各时刻的缺口数量可参见图4,详细代码请参见 Notebook。本文通过自定义一个简单的共享单车场景介绍了 MARO 的核心模块、运行逻辑以及与智能体的交互方式。除了方便使用者自定义场景之外,MARO 的另一个核心优势是拥有很多基于真实数据与业务逻辑打造的预定义场景,例如基于纽约自行车数据的 Citi Bike 场景[1]、基于真实海洋拓扑的空集装箱调度、使用真实 Azure 数据的虚拟机分配问题[2]。基于 MARO,研究员们也已经在集装箱调度问题上做了一系列的研究工作[3,4]。除了场景之外,MARO 还拥有易用的多智能体框架,高效的分布式训练算法和预定义的主流强化学习算法工具包,这些部分会在后续的文章中向大家介绍,帮助大家使用 MARO,提高开发和训练效率,助力强化学习在资源优化领域的应用。MARO 0.2 版本具体更新历史:
https://github.com/microsoft/maro/pull/239?
MARO 中预设定的资源优化任务:
https://maro.readthedocs.io/en/latest/scenarios/container_inventory_management.html
https://maro.readthedocs.io/en/latest/scenarios/citi_bike.html
https://maro.readthedocs.io/en/latest/scenarios/vm_scheduling.html
参考资料:
[1] Citi Bike 数据集:https://www.citibikenyc.com/system-data
[2] Azure数据集:https://github.com/Azure/AzurePublicDataset
[3]?Li X, Zhang J, Bian J, et al. A cooperative multi-agent reinforcement learning framework for resource balancing in complex logistics network. AAMAS, 2019.
[4]?Shi W, Wei X, Zhang J, et al. Cooperative Policy Learning with Pre-trained Heterogeneous Observation Representations. AAMAS, 2021.
?三种方法,用Python轻松提取PDF中的全部图片
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/























 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




