Transformer 对计算和存储的高要求阻碍了其在 GPU 上的大规模部署。在本文中,来自快手异构计算团队的研究者分享了如何在 GPU 上实现基于 Transformer 架构的 AI 模型的极限加速,介绍了算子融合重构、混合精度量化、先进内存管理、Input Padding 移除以及 GEMM 配置等优化方法。
从 Google 在 2017 年发表著名的「Attention is all you need」文章开始,Transformer 架构就开始攻占 AI 的多个领域:不仅成为自然语言处理(NLP)和语音等很多 AI 应用的默认核心架构,同时也成功跨界到计算机视觉方向,在超分辨率、图像识别和物体检测中取得 state-of-the-art 的性能。然而,Transformer 架构对计算和存储有着较高要求,使得很多 AI 模型在 GPU 上的大规模部署受到限制。如何针对 Transformer 模型结构特点,结合 GPU 硬件特性充分释放 GPU 并行计算的能力,对于实现 Transformer 的极致加速至关重要。自注意力机制 Attention 提出后,引入 Attention 机制的 AI 模型在 NLP、语音识别等 Seq2Seq 序列任务上都有很明显的提升[1]。先前的 Seq2Seq 模型主要将 Attention 机制与循环神经网络 RNN 结合起来。之后 Google 在「Attention is all you need」这篇文章中提出 Transformer 模型,用全 Attention 的结构代替 LSTM,在翻译、问答和情感分析等 NLP 任务上达到更好的性能[2]。相比 LSTM,Transformer 对 Long Context 的建模能力更强。作为 AI 模型研究的一个关键进展,Transformer 架构自被提出后迅速走红,已经成为众多 Seq2Seq 应用的不二之选,其主战场毫无疑问是 NLP 领域。从图 1 可以看出最近几年主流 NLP 模型的发展时间轴。从 ELMo 后,几乎所有的 NLP 模型都以 Transformer 为核心,比如 Google 的 BERT [3]、OpenAI 的 GPT-2 [4]和 Microsoft 的 Turing NLG [5]。
图 1:基于 Transformer 架构的 NLP 模型规模随着时间的推移,NLP 模型规模越来越大[4-6]。Turing NLG 模型拥有惊人的 170 亿个参数,单个 Nvidia 最新的内存高配版 GPU A100 仅能勉强装下。更让人惊叹的是,Open AI 最新提出的预训练模型 GPT-3 的参数更是达到了 1750 亿 [7],需要使用大规模 GPU 超算服务器进行训练及推理。更庞大的模型意味着更强大的模型容量和能力,GPT-3 仅需少量参数无须微调即可在系列基准测试和特定领域的 NLP 任务(从语言翻译到生成新闻)中达到最新的 SOTA 结果。因其性能太强大,OpenAI 担心模型被恶意使用,对社会带来危害,故而选择不开源模型参数。除了 NLP 之外,Transformer 也逐渐成为很多基于序列的语音应用的主流 AI 模型,在很多场景中已取代 RNN/LSTM,比如自动语音识别、语音合成等等,如图 2 所示。
同时,最近两年,Transformer 开始跨界到计算机视觉(CV)领域,帮助解决物体检测、图像识别和增强等问题。基于深度学习的计算机视觉应用通常以卷积神经网络(CNN)为主要核心模块。卷积算子能有效地对像素的 Local Context 进行捕捉,如果需要扩大感受野,通常需要多级 Pooling、更大的 kernel 或特殊算子,比如 Dilated Convolution 等等。将 Transformer 引入或与 CNN 结合起来能增强神经网络 Context Modeling 的能力。和大多数 Seq2Seq 模型一样,Transformer 的结构也是由 Encoder 和 Decoder 组成,Ecoder 负责提取 Contextlized 特征,Decoder 负责解码,如图 3 所示。其主要核心模块包含 Self Multi-head Attention、Encoder-Decoder Cross-attention 和 Feedforward,具体模型工作原理可参见[2]。?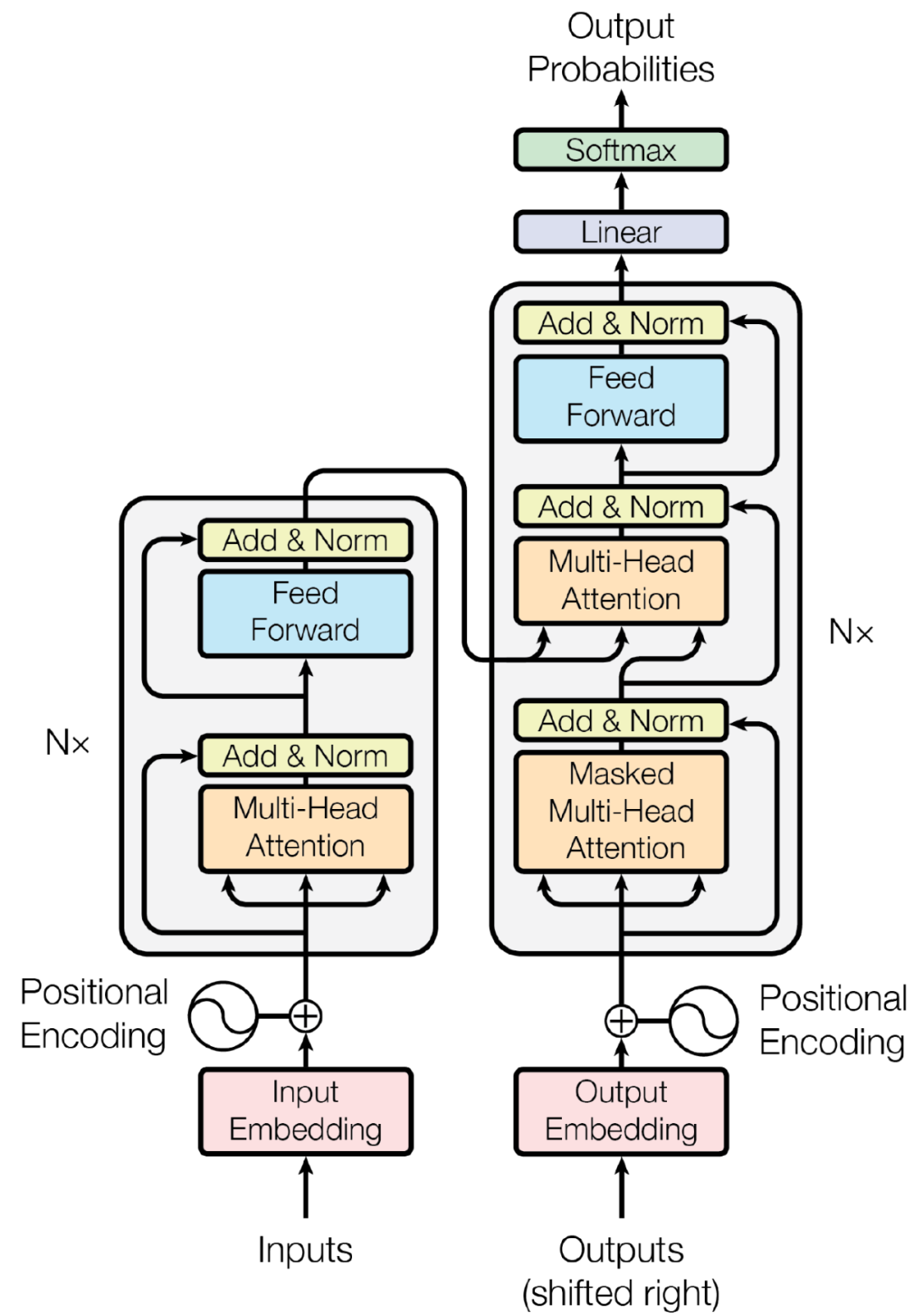
Attention 机制有很多不同的实现方法,Transformer 采用的是 Scaled dot-product attention,由矩阵相乘、Scale、Softmax 和 Concatenation 等算子组成。Encoder 一次计算能处理完整个 Batch 数据输入,而 Decoder 在很多 Seq2Seq 的应用中会对序列 Token 进行逐个处理直至序列结束。在这种情况下,Decoder 通常会成为整个运算的瓶颈。需要指出的是,很多基于 Transformer 的模型(如 GPT-2 等),其结构更偏向于仅含 Encoder 或 Decoder。而对于很多其他的应用——比如语音识别 Speech Transformer 和 Conformer 模型[12, 13],可能会在 Encoder 和 Decoder 整体结构基础之上还包含 Beam Search 或 Beam Sampling 等等。Encoder 对整个 Batch 数据的处理方式能充分利用 GPU 强大的并行计算能力,而 Decoder 的逐个 Token 处理的特性(尤其是结合 Beam Search 等模块)使得其 GPU 优化需要额外注意,尤其是需要避免重复计算和存储。图 4 以语音识别 Speech Transformer 模型整个 Decoding 部分为例详细说明。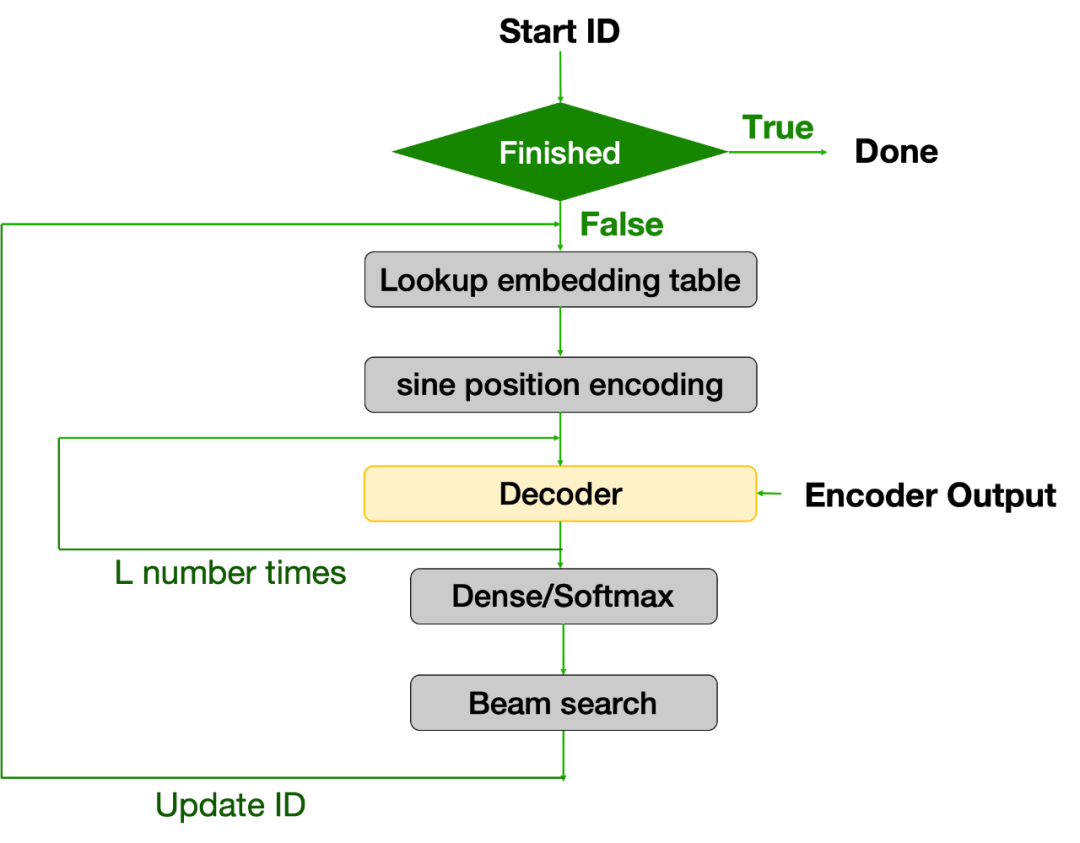
图 4:Beam Search Decoding (Decoder + Beam Search) 流程图输入的 Batch 语音特征进入 Encoder,Encoder 逐层计算完后送到 Decoder。前面已经提到,Decoder 是按照文符 Token 逐步进行处理,除了需要 Encoder 输出,还需在前一步解码所输出的 Token,本质是一个自回归的过程。在这一阶段,首先需要判断这个 Token 是不是代表句子结束的特殊字符:如果是,解码结束输出解码文字;若不是,则送至 Decoder。然后,模型通过 Masked Self-attention、Encoder- Decoder Cross Attention、Feedforward 模块以及 Softmax,输出所有可能字符的概率。Beam Search 会依据此概率用 Top-K 算法保留前 K 个最高概率的 Token,然后根据其目前保留的最优路径来更新 Token ID,再送到 Decoder 进行计算。整个 Decoding (即 Decoder 和 Beam Search) 的过程会输出对应于输入 Batch 序列的最大似然的句子,Beam Search 本质上是一个贪婪算法。毫无疑问,上述 Decoding 过程会对更新的 Token ID 进行很多重复计算。如何对此过程进行优化是问题的关键所在。在对 Transformer 模型结构深入理解的基础上,研究者结合 GPU 硬件架构特性,从计算和内存两个方面入手,对 Tranformer 各个关键模块开展了深入优化。此优化方案和技术也可以扩展至众多不同的基于 Transformer 架构的模型,快手希望借助这些 Transformer 家族模型的优化有效推进相关应用的大规模高效部署。根据具体模型架构和应用的不同,研究者将 Transformer 家族的模型分为四大类(如图 5):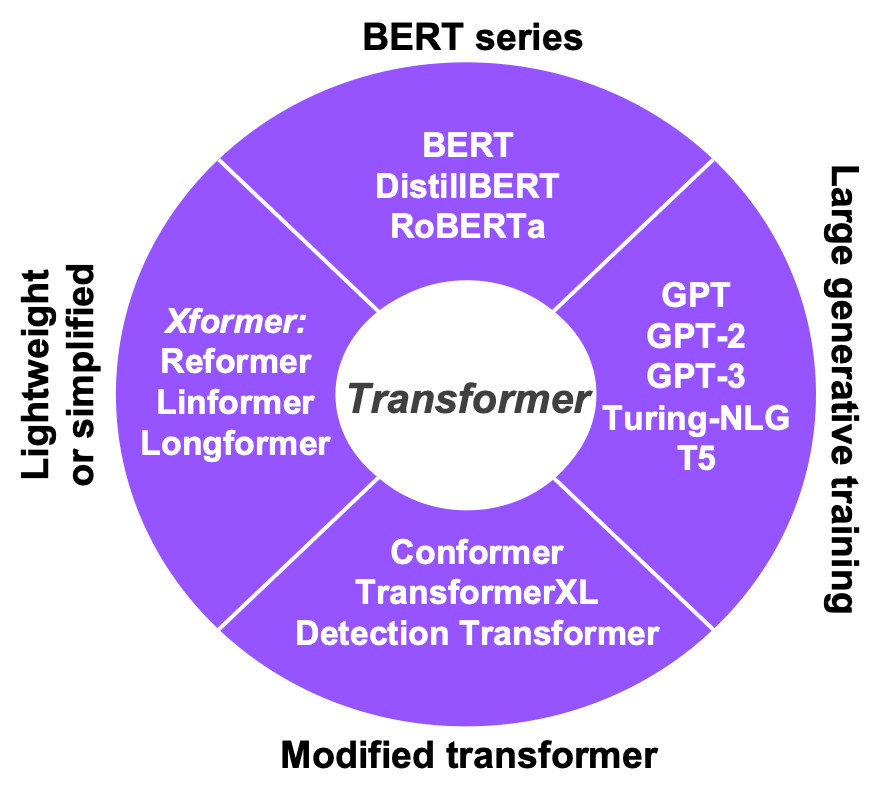
图 5:经典的基于 Transformer 结构的 AI 模型(1) BERT 系列包含 RoBERTa、DistillBERT 等。毋庸置疑,基于双向 Transformer 的 BERT 模型在 NLP 领域有巨大的影响力,同时在实际服务部署中也大显身手,其加速有很大的实际意义。不同的应用(如问答、情感分类等)会在 Transformer 核心模块上额外加入不同的神经网络层,整体 BERT 的 GPU 加速核心仍然是 Transformer 的优化。(2) 预训练生成模型,包含 Turing NLG 和 GPT 系列等。此类模型有能力在不依赖领域数据且不经过精调的情况下解决文本生成、对话及分析等很多问题,尤其是 BERT 所不擅长的文本生成。很多预训练模型(如 GPT 等)的架构类似于 Transformer Decoder 或 Encoder,因此在 Transformer 优化工作的基础之上扩展相对容易。(3) Tansformer 扩展模型,包含 Conformer、TransformerXL 等。这些模型在 Transformer 基础架构上进行局部修改或延伸,使其能处理更长的输入序列(如 TransformerXL)、对更长的 Context 进行建模(如 Conformer)或跨界至其他非 Seq2Seq 领域(如 Detection Transformer 等)。Conformer 模型即是将 Self Attention 和 CNN 相结合,增强对局部和全部 Context 的处理能力,在语音识别任务中得到了更好的性能。(4) 轻量化的 Transformer 改进模型(Xformer),包含 Reformer、Longformer 或 Performer 等。这类模型的研究着眼于降低复杂度,提升前向推理效能,是最近两年的一个热点。很多 Xformer 模型通过各种不同的方法(比如 Factorization、Low Rank、特殊 Pattern 或复用参数等)将时间复杂度由 O(n2) 降为 O(nlogn) 或 O(n) 。Transformer 的 GPU 底层优化核心技术根据 Transformer 的架构特点,快手的研究者在 Nvidia Faster Transformer 开源库 [14] 基础上针对具体的模型应用从算子、内存、精度等不同维度开展了大量研究和开发工作,同时也充分使用 GPU 多线程编程语言 CUDA 的很多加速技巧,主要核心优化技术如下:将多个神经网络层融合成一个 CUDA kernel 能很大程度减小计算量和内存 IO。通常,研究者会将尽可能多的层融合到一起,同时会对直接 CUDA 实现相对低效的算子进行无精度损失的重构,使其能高效利用 GPU 的计算单元或减小内存 IO 读写等。这些在计算图上所做的优化作用十分明显,对整体加速贡献很大。图 6 给出了 Self-attention 和 Feedforward 两个核心模块在计算图优化后的 CUDA kernel 实现方案。他们将 QKV 三个 Tensor 的矩阵相乘重构后仅采用一个 Cublas Batch GEMM 实现,同时将前一层的 Bias 项或者 Transpose、Residual Add 和下一层的 Kernel 融合一起。举例而言,针对 Multi-head Attention 这个关键模块,他们分解成 5 个 sub-kernel,最后使用一个 CUDA 函数封装实现。
图 6:Transformer 架构中 Self-attention 和 Feedforward 模块的 CUDA kernel 融合和重构,参见[14]低精度量化是神经网络加速的另一常见技术。使用更低的量化精度有利于充分挖掘 GPU 硬件(如 Tensor Core)的计算能力,同时能降低内存的 Footprint。通常情况下,GPU 在 FP16 精度下的 TOPS (Tera Operation per Second)是 FP32 的 2 倍,而在 INT8 精度下是 FP32 的 4 倍。FP16 和 INT8 精度下所需参数存储和传输带宽分别为 FP32 的 2 倍和 4 倍。另外,他们在 CUDA kernel 中使用了 FP16 Half2 数据类型。Half2 实际上是个类似于 SIMD 的操作:一次 Instruction 处理两个 Half 的数据,在内存 IO 成为瓶颈时效果不错。图 7 给出了几个关键算子所使用的精度类型。GEMM 使用的是 FP16/INT8,其他则使用 FP16 Half2 类型。Beam Search 中的 Top-K 采用的是 FP32。因该 Kernel 精度对最后输出结果相对敏感,所以使用 FP32 确保精度无损。
图 7:Transformer FP16 版本的几个关键 CUDA kernel 采用的量化精度研究者在内存管理上进行了大量优化工作。图 8 是 Transformer Encoder、Decoder 及 Beam Search 的内存管理示意图。
图 8:Transformer CUDA 实现的内存管理他们对这三个模块分别预先分配单独的 GPU 内存。主要使用的内存优化方法包含:1) 内存 Sharing: 针对 Encoder 批处理输入数据而无须缓存中间数据这一特点,研究者提出了 Ping-pong Buffer 的策略,将 Encoder 的内存分为两大块——Buffer A 和 Buffer B。第 I 层从 Buffer A 读取数据写入 Buffer B,第 I+1 层会从 Buffer B 读取第 I 层的输出,同时将输出写入 Buffer A。这样可避免每层单独开辟内存空间,能将 Encoder 占用的内存减小为原来的 1/N(N 是 Encoder 的层数)。此方法可极大地节省 Encoder 在运行过程中所占用的内存,使得支持更大的 Batch Size 的输入数据成为可能。2) 内存 Caching: 在前文 Decoding 的工作机制描述中,研究者详细分析了 Transformer 所存在的重复计算问题。为了避免 Decoder 和 Beam Search 的重复计算开销,他们将 Decoder 的部分中间层输出在 GPU 内存上 Caching 起来,保留已经计算过的 Beam Search 路径。当需要更新路径的时候,不需要重复计算已经计算过的路径。3) 内存 Pre-alloation: 很多基于 Transformer 的应用需要支持动态的 Batch Size 和序列长度,为了避免重复申请删除 GPU 内存所带来的巨大开销,可根据服务所可能出现的最大 Batch Size 和序列长度对每个模块的内存进行预先分配。输入 Padding 是很多 NLP 和语音应用中的常见预处理步骤。在同一个 Batch 的数据内,不同序列长度可能会不一样,因为 Transformer 通常只能接收等长的序列数据,实际都会将短序列通过加空帧进行补齐。这些空帧虽参与 CUDA Kernel 运算,但很多时候对最终计算结果并没有影响,反而给 GPU 造成了额外的运算负担。因此,可以去掉这些空帧,并将其相对位置记录并保存至 Offset Mask。通过 Offset Mask 可以实现去空帧序列和原始序列的互相转换。相比之下,去空帧后的数据序列会缩短很多,所需计算量可大幅缩减,见图 9。
图 9:输入 Padding 移除的方案 - 通过引入 Offset Mask,移除 Padding 的 Sequence 和原始的 Sequence 可以互相转换重建需要注意的是,去掉空帧并不是对所有 CUDA Kernel 的运算都没有影响。也就是说,这种方法并不是通用的,其有效性取决于 Kernel 运算是否涉及相邻帧的数据。如果当前 Kernel 的计算只使用到帧内部数据,不涉及到相邻帧的数据,那么去除 Padding 对结果没有影响。针对具体的模型,可以将模型的计算 Kernel 分为两类:(i) Kernel 运算完全基于帧内数据,去掉空帧对此 Kernel 的运算结果无影响;(ii) Kernel 运算涉及相邻帧数据,去掉空帧对此 Kernel 的运算结果有影响。可以在前一类 Kernel 前将 Padding 去掉,在后一类 Kernel 前可额外插入「Rebuild Padding」Kernel 重建原始序列,如图 10 所示。
图 10:通过对 CUDA Kernel 的分类判断是否可以移除 Padding需要注意的是,「Remove Padding」和「Rebuild Padding」的 Kernel 会带来额外开销,整体设计需要考虑开销和收益的平衡。一般而言,输入 Batch 数据各序列的长度差距越大,去掉 Padding 带来的收益越高。在 Transformer 架构中,因为所有 Attention 模块都会涉及相邻数据帧的计算,所以需要在 Attention 模块之前进行重建。而对于 Decoding,因为大部分 Kernel 都涉及到相邻帧计算,去掉 Padding 带来的收益不明显,因此此方法主要在 Encoding 端使用。Transformer 架构中有很多线性层采用 Cublas GEMM 实现。Cublas GEMM 有很多不同的实现方案,在矩阵相乘速度和误差上各不相同,因此需要根据不同的矩阵相乘维度定位出最后的 GEMM 的配置参数,在误差可控的情况下获得最快运算速度。图 11 列出了 Encoder 和 Decoder 所包含的矩阵相乘 GEMM 的信息。由于 GEMM 维度取决于输入数据的 Batch Size 和序列长度,实际应用中可以扫描出可能出现的不同 Batch Size 和序列长度所对应的所有 GEMM 矩阵相乘的配置参数,存入 Look-up Table,在实际 Serving 的时候依据输入数据的 Batch Size 和序列长度加载最优的配置参数。
图 11:Transformer GEMM 配置的优化快手的研究者从底层优化出发,在充分分析 Transformer 的网络结构,算子特性以及 GPU 硬件特性的基础上,通过软硬件联合设计的思想对 Transformer 模型进行了深度优化,充分释放 GPU 本身强大的并行计算能力。他们高效地实现了多种优化技术,包含算子融合重构、混合精度量化、先进内存管理、独特的 Input Padding 移除方法以及 GEMM 配置。该 Transformer 优化方案已经成功推广至快手其他 Transformer 家族模型的语音或 NLP 相关 AI 应用,包含 Conformer、GPT-2、BERT 等等,极大地提高这些应用的 GPU 推理速度。[1] M. Luong et al, Effective Approaches to Attention-based Neural Machine Translation, arXiv:1508.04025v5 (2015).[2] A. Vaswani et al. Attention is all you need, Advances in neural information processing systems (2017).[3] J. Devlin et al. Bert: Pre-training of deep bidirectional transformers for language understanding, arXiv:1810.04805 (2018).[4] A. Radford et al. Language Models are Unsupervised Multitask Learners, 2019.[5] https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/[6] C. Raffe et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, arXiv:1910.10683v3 (2019).[7] T. Brown et al, Language Models are Few-Shot Learners, arXiv: 2005.14165v4 (2020).[8] N. Carion et al, End-to-End Object Detection with Transformers, arXiv: 2005.12872 (2020).[9] M. Chen et al, Generative Pretraining from Pixels, ICML (2020).[10] F. Yang et al, Learning Texture Transformer Network for Image Super-Resolution, CVPR (2020).[11] D. Zhang et al, Feature Pyramid Transformer, ECCV (2020).[12] Y. Zhao et al, The SpeechTransformer for Large-scale Mandarin Chinese Speech Recognition. ICASSP 2019.[13] A. Gulati et al, Conformer: Convolution-augmented Transformer for Speech Recognition, arXiv:2005.08100v1 (2020).[14] https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer快手异构计算团队立足于服务公司的核心业务,主要包括 AI/ML、音视频技术,大数据分析,网络和安全,以及其他高性能计算相关等,致力于打造公司技术护城河,引导互联网硬件行业发展。根据不同异构器件的特点,研发包括 FPGA、ASIC、CPU、GPU 等的混合计算平台和解决方案,为快手各业务部门提供强大、高效的计算系统。让每一种不同类型的计算单元都可以执行自己最擅长的任务,从而达到卸载业务运算瓶颈,提高性能、节省成本、节约能耗的目的。报告内容涵盖人工智能顶会趋势分析、整体技术趋势发展结论、六大细分领域(自然语言处理、计算机视觉、机器人与自动化技术、机器学习、智能基础设施、数据智能技术、前沿智能技术)技术发展趋势数据与问卷结论详解,最后附有六大技术领域5年突破事件、Synced Indicator 完整数据。
识别下方二维码,立即购买报告。
??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




