
个推异常值检测和实战应用

日前,由又拍云举办的大数据与 AI 技术实践|Open Talk 杭州站沙龙在杭州西溪科创园顺利举办。本次活动邀请了有赞、个推、方得智能、又拍云等公司核心技术开发者,现场分享各自领域的大数据技术经验和心得。以下内容整理自个推资深算法工程师令狐冲现场分享:
令狐冲(花名),个推资深算法工程师,目前负责个推深度学习相关研发工作,对 AI 算法有深入的了解及丰富的实践经验,擅长将大数据分析与深度学习神经网络相结合,为业务落地输出算法产品化能力。
大家好,我是来自个推的令狐冲,今天主要分享大数据中的异常值检测和实战应用,围绕研究背景、异常值检测方法、异常检测实战应用等话题,结合相关实战数据介绍异常值检测算法的最新进展情况。
研究背景
异常值检测是大数据分析中一个重要的研究方向,实时异常值自动检测有助于运营人员快速发现系统异常问题。我们常说的异常值通常是相对于正常值来表述的,要结合实际业务来讲一个值是否正常,也就说这是一个业务描述。如果我们要解决一个业务问题,首先要做的就是将这个问题数学化,将业务描述转化为数学描述,这样你才可以使用适合的算法或使用其他分析方法来解决。
对于异常值而言,从数学上看可以看做一个离群点。当然在实际业务中,考虑到业务的结合情况不同,有些异常值看似是离群点,但是从全局业务上看也可能是一个正常值。具体情况需要结合结果来分析,不过我们大致可以使用离群点来代表异常值。
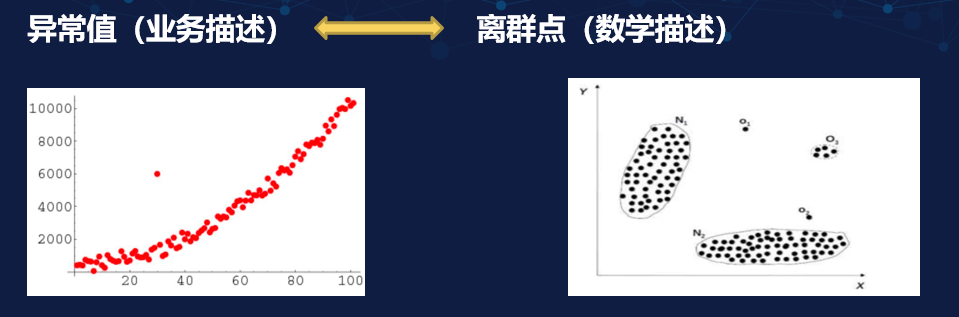
上图为异常值描述图,从图中我们可以看到在回归时有一些值不在回归线上,这些就是离群点。当我们在做聚类或分类的时候,这些孤立的值可能就是我们的异常值。
异常值检测相比其他人热门项目而言是一个比较小众的方向,但是它在流量监控、金融欺诈、系统故障检测等场景下也是有较多应用的:
流量监控:运维同学平常都比较关心流量检测,比如当服务访问出现异常的时候,需要第一时间找出问题
金融场景:金融场景涉及到的东西很多,因此异常检测我们以其中的金融欺诈举例:正常情况下的金融转账或消费是一个低频事件,但是当一个账号在短时间内多次转账或消费时就可能存在金融诈骗的风险
系统故障检测:这个在工业界用的较多,因为一个工业系统内会安装各种各样的传感器,这些传感器会实时传送系统内部件状态的数据,当这些系统内部件发生故障时往往会产生异常信号,如果能及时检测出异常信号找出异常原因就可以挽回大量的损失
异常值检测方法
接下来和大家谈一下异常值检测的方法。业内对于异常值检测方法都有不同的观点,总结下来就会有很多的分类,因此今天我们只谈我的观点。在我看来异常值检测方法可以分为两种,一种是“基于统计的方法”,稍微了解一点统计的话应该知道,统计是有分布的,比如典型的 3σ 原则和箱体图;另一种则是“基于模型的方法”,也就是通过构建模型来区分正常值和异常值。
基于统计的异常值检测

如上图所示,左图是我们经常听到的 3σ 法则,3σ 法则比较简单但很实用,它是一个经验法则,具体是什么意思呢?其实 σ 是标准差,当我们检测数据服从正常的统计分布时,我们可以将超过 3σ 的数据认为是异常数据。它的标准均值为 0,从标准分布图来看,大约有 0.3% 的数据为异常值。当然如果你的均值是非 0 分布,你可以把均值加上去。不过由于 3σ 法则是一个经验法则,还是比较粗糙的,因此在实际工作中,建议大家只在某些特定的场景下使用它。
右图是箱体图,在数据的统计分析中特别常用,比如我们用 pandas 做处理时就经常使用这个方式处理异常值。如图所示构成箱体的一般是分界位的四分之一到四分之三,而分界则是左边箱体的边界减去箱体长度的某一倍数,通常我们这个倍数为 1.5 倍,异常值则是超过最左边和最右边边界的值。

上图是两种统计方式的对应关系。假设数据分布是一个纯粹的正态分布,我们可以看到箱体图对应的 σ 值只有 2.7σ 左右,不到 3σ 。当然很多时候我们并不知道它的具体分布是什么,需要根据样本的方差、标准差来求 σ,如果你实在不知道是什么分布,可以将它假设为是一个正态分布。因为正态分布是自然界一个比较“和谐“的分布,一般场景中就算有偏差也不会过于离谱。
基于统计的异常值检测有两个明显的优点:一个是是简单方便,因为我们既不需要考虑它的鲜艳,也不需要考虑它的特殊分布;第二个则是因为这是基于统计学来的,有较好的数学基础。当然它的缺点也很明显:首先是需要较多的样本数据,其次是高维数据比较难处理。上图展示的是一维分布,处理起来还比较简单,高维数据中联合分布会涉及到一些相关性,处理起来就会比较困难。
基于模型的异常值检测
接下来我们来谈一谈基于模型的异常值检测。在我们谈具体模型之前,我们需要先知道如果从分类的角度来看正常值和异常值,那它就是一个二分类问题,尽管它因为正常值多而异常值少的原因比常规的二分类问题特殊一些。因此我们可以把它看做一个样本不均衡、分类不均匀的数学分类问题。
有监督模型
确认了问题类型后,我先具体介绍一下有监督模型,通过这个常见的分类算法,比如 k- 最近邻,可以知道到底是正常还是异常的标签。除此外还有典型的二分类模型支持向量机 SVM。同时因为样本不均衡的原因,也衍生出了 oneclassSVM。

那分类模型具体是如何进行异常值检测的呢?简单举个例子,大家可以看一下上图。我们常规的 SVM 是使用一个超平面将正负样本分开。但是如果只有一个类,或者说负样本极少的时候要怎么办呢?我可以使用超球面将正样本包含,然后将超球面以外的当做异常样本,通过这种方式去进行异常值检测。

接着说一下现在比较多的神经网络深度学习的方法是如何用在异常值检测上的。一般来说神经网络方法比较多的用在分类问题上,如果你需要将它使用在异常值检测上,你可以输入一个样本值,令其经过一个隐藏层,经过 decoder 层进行编码得到输出向量。如果是正常的样本我们就让 input 和 output 尽可能的接近,将它压缩到隐藏层也就是压缩到一个 code 内,然后用它来进行表征。后续需要通过各种方式,比如均方误差损失等,训练网络减少输入和输出的误差,当这个网络能够达到正常值输入计算结果落实较小、异常值输入计算结果落实较大时,就可以用来进行异常值检测了。
上图我们可以看到右边对左边的模型进行了改进,不止是一层编码层,而是构造了中间的 code 分布,通过这个分布右边的稳定性会比左边好。
无监督模型
刚刚介绍的是有监督模型,但是实际上我们做异常值检测时更多的还是使用无监督模型。因为异常值是很少的,而且还会出现没有遇到的情况,这就导致你标注的异常点会非常的少。所以我们更多的是通过无监督的学习方法,让异常值能够比较完整的表征出来。

无监督模型比较典型的是下列三类:
密度聚类:DBSCAN
孤立森林:IsolationForest(IF)
随机剪切森林:RadomCutForest(RCF)
密度聚类这里就不用细讲了,参考上图左侧,大家可以看一下。
孤立森林最早是由周志华教授团队提出的,听名字大家可能觉得和随机森林或者 adboosting 这些方法相似,其实不止名字相似本质上也和这些方法相似。孤立森林是通过将一些样本或者一些点构造为多棵树,让这些值快速的到达叶子节点,之后根据每个点对应的树的深度来计算该点的平均深度。由于异常值和其他值不一样,会出现一些异常的现象,我们就可以通过设置阈值来快速的检测异常值。
随机剪切森林是由英文 RadomCutForest 直译过来的,简写为 RCF。它其实和孤立森林的整体思路是相同的,都是经过构造树来处理。但是因为我们构造树的时候需要选取样本,而随机剪切森林在采样方法上更好一些,能够更有效的处理多维度的相关性。同时因为随机剪切森林有更好的集成模块,所以在实战程度上比较推荐使用这个方法。
刚才也讲过随机剪切森林和孤立森林的整体思路是相同的,那它们之间有什么区别?大家可以参考下图了解一下。左边的公式是一些数学映射,里面 c(n) 代表样本的平均深度。右图中的红线代表 s,也就是最后的异常值得分。蓝色曲线是构造的预设正弦曲线,异常值则是在某一时段让曲线的一段成为直线的部分。
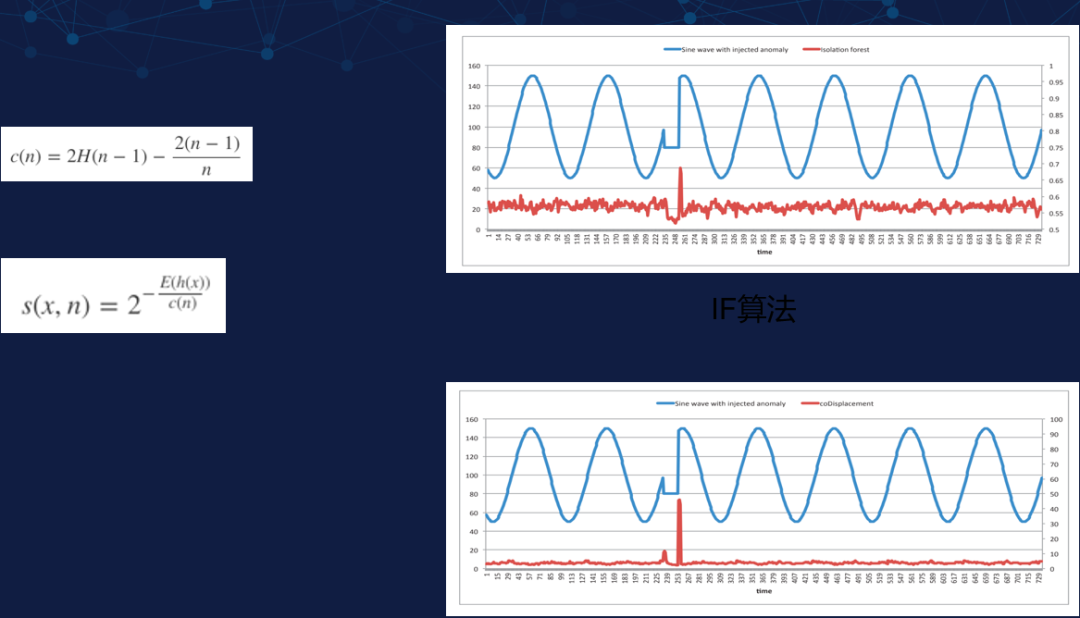
△ 孤立森林和随机剪切森林的区别
上图右侧上方的图表展示的是孤立森林算法的结果图。我们可以看到图中有两个异常值,孤立森林算法在计算异常值得分 s 时,对于后面的突变点会有突然增高,这里我们可以设置一个合适的阈值来找出对应的点。
上图右侧下方的图表展示的是随机剪切森林算法的结果图。我们可以明显看到虽然在整体上比较相似,但是该算法即便是前面较小的跳变点也可以精准找出,这就是随机剪切森林比孤立森林算法有优势的地方。
异常值检测实战应用
说完了检测方法,我们接下来看一下异常值检测在实战中的应用。下面是某应用(app)的日活进行监测, 其日活并不是稳定不变的,比如促销活动时日活会变高,但当日活突然变低时则需要我们去排查是否统计日志或数据流本身出了问题。

上图是某应用 2016 年 8 月到 2019 年 9 月的日活统计。这么直接一看就可以看到它有很多的突变点,这些点可能就是它的异常行为。而异常值检测要做的就是使用统计或者机器学习的方法将这些异常点找出来。
当成静止数据时的异常值检测
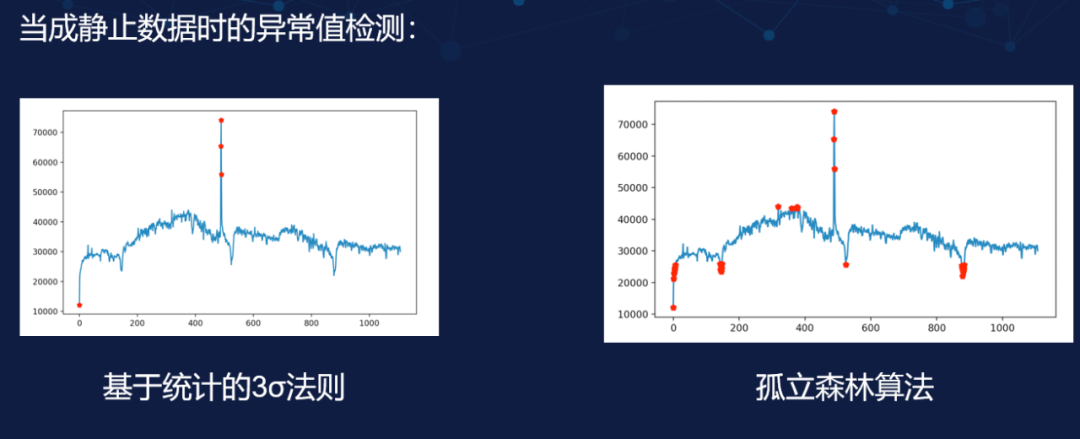
上图是将之前的日活统计当成整体数据后检测的结果,这是一个静止的数据。我们可以看到左图 ?3σ 法则的检测效果并不好,只检测出了少数的几个点;而右图使用孤立森林算法则的优势则可以很明显的看到,它基本能够将人眼看到的异常全部检测出来,而且还有一些人眼没看到需要局部放大才能发现的数据,它也能够检测出来。
当成流式数据时的异常值检测
在实际操作中我们会遇到很多流失数据的情况,不能够单纯的将数据当做静止的均值数据看,所以我们现在来看一下流式数据的异常值检测。
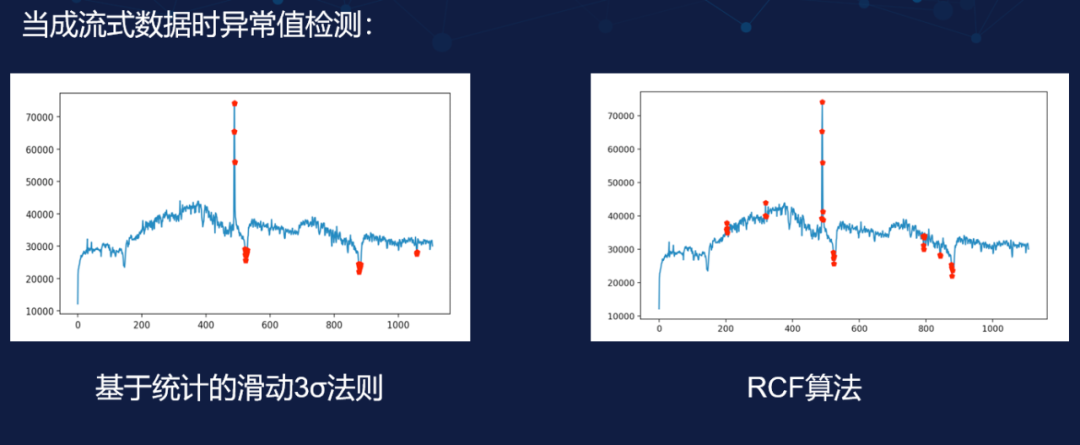
在检测实时数据时,基于统计的方法可以使用滑动窗方式来检测,让窗去滑动更新,而我们只需要统计窗的情况就好。使用这种方式后 3σ 法则就可以将绝大部分的突变点都检测出来了,当然很明显的可以看到右图中使用 RCF(随机剪切森林算法能够检测到的突变点更多,不过现在这张图我没有放大,但是 RCF 其实将局部的小异常也检测出来了。
无论是静止数据还是流式数据,我们都可以明显看到基于 RCF 的方法检测的更准确一些,但是这并不代表我们可以完全放弃基于统计的方法。当我们在检测那些数据量很大而且异常点的损失较少的数据时,我们仍然可以使用基于统计的方法。虽然它的精准度不如 RCF,但是它操作简单。目前大多数没有接触异常值检测的公司使用的都是基于统计的方法,通过设置一个 3σ 阈值或使用箱体图来进行异常值判断。而在对异常值检测有较深接触后,RCF 就成为了异常检测的主流。
下图是基于不同异变点所作的算法总结:

时序变点异常:对于这种时间点的突变,使用统计算法就可以比较好的检测出来;
时序折点异常:对于这种不是一个点的跳动而是台阶式跳动的异常,可以使用 RCF(随机剪切森林) 算法来检测;
时序周期异常:对于这种周期异常的检测,推荐的检测方法是流式图算法。这里说的图算法其实是指图神经网络。这点我之前并没有提到,是因为目前图算法还处于一个初步阶段,它的研究并不成熟,把图神经网络和异常值检测结合起来的运用还特别的少。但是因为图神经网络现在的发展很快,所以在未来它一定会在异常值检测方面有很好的效果。
讲到现在其实我们已经看了很多具体的算法例子,但是如果一定要说哪种算法最好,没有办法给出一个唯一答案,毕竟具体的选择需要和你的实际业务结合起来,合适才是最好的。
以上是令狐冲的全部分享内容,回看视频请点击↓↓阅读原文↓↓
快 来 找 又 小 拍

推?荐 阅 读 


设为星标

更新不错过
设为星标
更新不错过
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 又拍云
又拍云
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675