
是结束也是开始 | TiDB 2020 Hackathon 不负责任点评
作者介绍
唐刘,PingCAP 首席架构师。
性能优化
去年 Hackathon 的第一名 - Unified Thread Pool,就是一个性能提升项目,而且我也非常开心的看到这个项目已经在 TiDB 落地,我们也取了一个特别程序员的名字 - YATP(Yet Another Thread Pool)。
首先就是决赛第一组答辩的?GPU 加速项目,我向来认为第一组答辩的同学都是极度需要勇气的,不过得益于馒头同学的东北相声,演示取得了非常不错的效果,最后也拿了两个奖项,还是非常不错的成绩。
这个项目直接在 GPU 这个硬件领域,给 TiDB 带来了新的扩展性,其实原理还是很简单的,就是将之前很多算子计算从 CPU 放到了 GPU。实际展示的时候,为了保证没有 IO 的干扰,馒头他们这次将聚合数据先放到了 Coprocessor cache 层,然后在这个 cache 层上面对上层算子进行了 GPU 加速,类似下图展示:
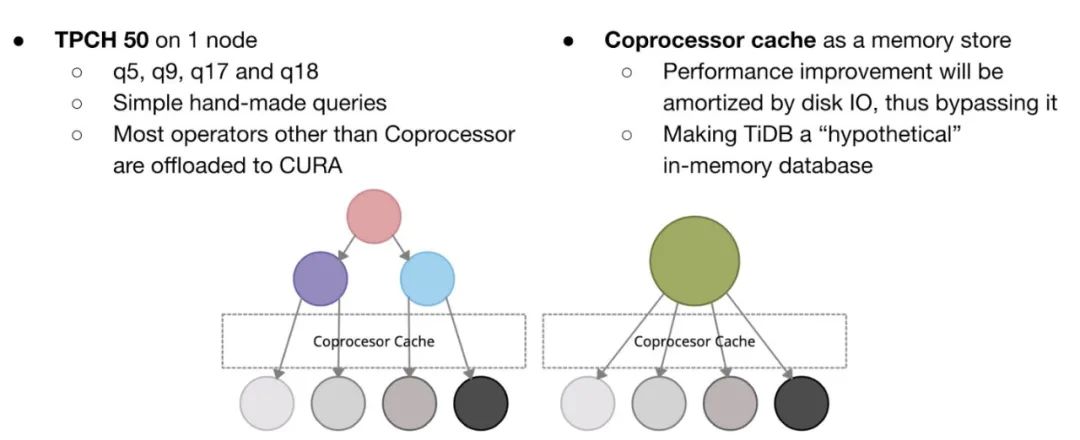
当然实际效果还是很好的,这里就不贴数据展示了。后面我还是非常期待能实际落地的,但要做的工作其实还不少,包括在 TiKV 和 TiFlash 也实现 GPU 加速,以及尽量减少 IO 的影响等问题。在云上面我就更期待这个功能了,AWS 直接有提供能 GPU 加速的 EC2 实例,另外,如果以后我们大量的数据存放到 S3,那么就可以做到一边高吞吐的读取数据,一边快速的用 GPU 进行计算。
相比于 GPU 加速, 羊刀项目团队则采用了另一条路径,使用 SPDK 对 IO 进行加速。随着 NVMe 硬件的普及,传统的 Linux 文件系统其实并没有把 NVMe 的性能压榨到极致,所以羊刀借鉴了 Intel 的 BlobFS ,使用 SPDK,改动了 RocksDB Environment 来让 TiDB 能跑在一个用户态的文件系统上面,实际展示的效果也是很不错的。不过我个人认为离真正能上生产还有不小的距离,但做好了,对一些不差钱用的 PoC 还是很有好处的。
不光是硬件,在软件架构层面,我们也是有可以提升的地方的。Hackthon Fix Type 团队做的减少回表的尝试就是这样的一种优化。在 TiDB 现在的架构设计中,如果我们要通过索引查询一条数据,那么会有两个步骤:
1. 通过 Index 找到对应数据的 Primary Key
2. 通过 Primary Key 得到实际的 data
我们通常把上面的流程叫做回表,这个其实也是传统数据的做法,譬如 MySQL。对于 TiDB 来说,如果 Index 和 Data 在不同的 TiKV 上面,我们就多了一次额外的网络开销,这下子延迟就上去了。所以 Hackthon Fix Type 团队在一些场景下面(譬如小表),将 Index 和 Data 的数据调度到同一个 TiKV 上面,然后在查询的时候,直接在 TiKV 本地进行回表操作,实际的效果还是很不错的。这个功能是我非常期待的功能,之前一些分库分表的场景,大家担心迁移到 TiDB 会有回表性能问题,自然也就解决了,因为我们能将分区调度到一台 TiKV 上面。
现在大家的 IDC 网络环境是越来越好,这两天还有一个朋友说他们正在搭建 100G 的网络,但在跨地域的网络上面,其实我们还会面临各种带宽不足,不稳定的问题。而平头哥团队的跨 AZ 流量优化,则是这块一个很好的尝试。平头哥团队主要做了如下几件事情:
1. 智能化的对跨 AZ 的查询请求通过 follower read 特性走本地 AZ 读取。虽然之前我们也有 follower read 功能,但用户需要手动的控制,而且使用起来不方便,但平头哥这边通过查询统计信息,热点判断等多种方式,能做到智能化的调度控制。
2. 引入 Delta 方案对日志消息进行重新编码,减少消息的大小,在测试的时候最多能减少了 15% 的复制流量,对于成本有显著的降低。
这个章节最后一个介绍,我留给了 Uchiha clan 小组,要说今年的 Hackathon 跟之前有啥不一样,我认为真国际化算是一个很突出的点,因为这个小组是来自印度的同学。他们支持了 Flexible Raft,当然这个技术还是比较硬核的。对于 Raft 来说,我们都要有多数派保证,譬如 5 个节点,那么至少需要 3 个节点参与选举或者日志复制,因为只有这样,在发生网络分区等故障的时候,我们才能保证新选出来的 leader 有最新的数据,这也是 Raft 一致性保证的基础。不过,这个保证可以稍微有点变化,我们只需要参与投票的节点和参与复制的节点有交集,就能保证选出的 leader 有最新的数据。具体到上面 5 节点的例子,我们可以让 4 个节点参与选举,2 个节点参与复制,这个也就是 flexible Raft。为啥要做这个事情了,主要还是为了日志复制的性能,2 个节点参与复制会比 3 个更快。但是这个优化对于 TiDB 现阶段来说没啥太大的作用,因为我们默认是 3 个副本,只有在 5 个副本及以上,flexible Raft 才能很好的工作。
功能增强
上面说到了性能相关的优化,这次 Hackathon 也有很多组在功能上面给 TiDB 进行了增强。
去年的 Hackathon,我们通过 WSAM 将 TiDB 跑在了浏览器里面,这个项目获得了第二名的好成绩,而今年, ‘or 0=0 or’ 团队则通过 WSAM,在 TiDB 里面支持了 UDF,一举夺得了冠军。
TiDB 现在还没支持 UDF,一方面我们并没有想好如何解决 UDF 的安全问题,另外,UDF 如何能在 TiDB,TiKV,TiFlash 多个组件,以及 x86,ARM 多个平台高性能的运行也是让我们头疼的点。而这些都可以通过 WASM 很好的来解决。使用起来也非常的容易,大家只需要编译好 WASM 的字节码,而后通过 create funcation 语句来创建 WASM 的 UDF,则可以轻松的使用。更令我吃惊的是,这个组还支持了 UDF 的下推。这个项目是真的能上生产的,当然也还需要做一些工作的,譬如我们要在 TiDB binary 里面集成 LLVM 相关 library。
除了 UDF,这次比赛,Mouse Tail Juice 团队也将 MySQL 的 create event 也引入到了 TiDB。现在我们可以在 TiDB 创建 event,譬如定期的 DDL、Backup ,让 TiDB 也真正具备了事件调度功能,能方便大家运维。
T4 团队给 TiDB 增加了 TTL 功能也是非常让我喜欢的,他们支持了 Row 和 Partition 的 TTL。这个功能其实原理很简单,对于 Row,现在在 GC 阶段进行处理,而 Parition 则是在 DDL owner 定期 check,但这个功能的应用场景非常的广泛,譬如在维度报表,events 存储等都有成功的落地案例。
在稳定性上面,森海飞霞也给我带来了很大的惊艳,因为他们做了之前我们一直想做但没有做的事情。假设用户同时换掉三快盘,而 TiDB 的三个副本全在这三块盘上面的概率,虽然比较小,但只要撞上了,对我们就是灾难。随着用户集群规模逐渐的增大,上述风险概率会增大。幸运的是,我们不是一个人在战斗,其他厂商也面临同样的问题,而业界对这块也一直有研究,一个比较成熟的做法就是引入 copysets。这个算法这里就不详细说明了,简单来说就是使用了一种分组规则,能降低上述风险发生的概率。但 copysets 只能解决静态的副本分布问题,所以在这个基础上面,森海飞霞还探讨了 dynamic copysets 的实现,以及跟 PD 调度器的协作,我还是非常期待后面这个快速落地到 TiDB 中,对于提升整个产品在灾难发生时候的可用性还是有非常大的帮助。
在这个章节,我最后要介绍的是 hundundm 团队的 TiDB 视界功能,他们借鉴了 BI 的思路,将 TiDB 集群的很多信息,在 dashboard 里面可视化的展现了出来,譬如下图的表 SST 数据分布:

使用图表能极大的提升 TiDB 诊断问题的效率,非常的直观。这个团队在去年的 Hackathon 做了 Key Visualizer,能在 dashboard 很好的展现负载的热点情况,我也非常期待今年他们的成果能快速的在 dashboard 里面落地。
生态扩展
生态这块今年是我觉得今年最让我振奋的一块,而且我发现,通过将几个项目整合到一块,就完全能扩展 TiDB 的产品形态了。
首先就是 Flink 相关的项目了,2020 年 TiDB 跟 Flink 正式开始了合作,然后在 Hackathon 上面,我就非常开心的看到了基于 Flink 的项目了,而其中 TiFlink 项目还得到了最佳人气奖。TiFlink 团队给 TiKV 写了一个 DynamicTableSource,让 Flink 直接读取 TiKV snapshot 数据以及 CDC 流式变更数据,同时支持了DynamicTableSink,能让 Flink 通过 TiKV 事务的方式将数据重新写回到 TiKV 里面。通过这种方式,让大数据处理在 TiDB 以及 Flink 之间高效的流转。同时,TiFlink 也构建了一个 global snapshot coordinator,可以让分布式执行的 Flink 任务在以 snapshot isolation 的强一致方式来维护物化视图,这也是非常不错的一个创新点。
除了 TiFlink,评委说的都对这个团队不光让 TiDB 也支持了物化视图,也通过 Flink 让 TiDB 具备了联邦查询的能力,让 TiDB 成为了一个通用的计算引擎。他们在创建表的时候提供了 WITH 定制的语法,让 TiDB 知道表是外部系统的数据,然后对这个表有数据请求的时候,TiDB 会通过一个 Proxy 将请求转发到 Flink,然后由 Flink 负责去不同的系统获取处理数据。
评委说的都对团队在展示的时候,提了一句理念『会 TiDB == 会大数据』,这句话我还是非常喜欢的,我相信,随着 TiDB 跟 Flink 等更多系统的完美整合,我们在数据处理上面会做的更加出色。
前面两个 Flink 项目都提到了物化视图,在这方面,dddd.indeed 团队也做了尝试。最开始的时候,当我听说 dddd.indeed 这个团队要基于 Raft log 做物化视图的时候,我是非常的期待的,因为这是一个非常硬核的挑战,最大的难点在于我们有不同的 Raft log 链路,同时因为 TiDB 数据分片的分裂和合并,一些 Raft log 链路还互相有关系,所以光是处理这些逻辑都异常的复杂。最后当然很可惜,dddd.indeed 团队基于 Raft log 的方式挑战失败,但他们马上基于 CDC 的方式实现了物化视图,直接在 TiDB 上面实现,这样就能让 TiDB 不依赖 Flink 提供物化视图的能力。
除开 Flink,搜索的对接也一直是每年 Hackathon 大家愿意尝试的方向。去年有一个 TiSearch 项目在这块有了不错的今年,今年 TIS 在 TiSearch 的基础上真的提供了一个很不错的解决方案。TIS 使用 Flink 将 TiDB 增量更新数据实时的处理后写入到搜索引擎中,然后直接使用 TiSearch 团队之前的方式来让 TiDB 跟搜索引擎进行查询交互,这样就能提供一个 near realtime 的 search 功能了,虽然做不到完全的 realtime,但对于搜索来说,绝大部分场景已经完全够用了。
Redis 的协议对接也是每年大家尝试的点,今年我非常开心的看到转转队的 WalleKV 在这块提供了生产级别的解决方案。WalleKV 在 TiKV 上面实现了 Redis 基本的数据结构,当然能让外面通过 Redis 协议来使用。但他们更进一步,通过 codis 来将 TiKV,Redis 结合起来,提供了一整套数据存储方案。大家只需要通过 Web 配置好规则,WalleKV 就能自动的将请求路由到对应的 Redis 或者 TiKV 集群。
这章节最后,在介绍下鸽了爽团队的 FDW,这也是我给分最高的一个项目之一,因为我太喜欢这个项目了。有了 FDW,我们就能快速跟不同的生态进行整合。鸽了爽团队在演示的时候展示了如何查询 Prometheus 和 Elasticsearch,但我们能做到更多。譬如对于前面的几个 Flink 项目,我们完全可以通过 FDW 将 Flink 和 TIS 隐藏到后面,让 TiDB 作为统一的数据出入口。我们也可以提供一个 S3 select FDW 的支持,直接让 TiDB 在 S3 上面进行数据查询。
云上工程
有状态的服务跟 K8s 的整合一直是业界一个比较困难的挑战,TiDB 自然也不例外,为此,我们开发了 TiDB operator,但是 operator 在实际运行的时候也暴露出一些问题,所以今年我非常开心看到有两组同学在这块进行了大胆的尝试。
首先就是 2021 团队的 TiDB operator 原地升级项目,这个直接解决了我们 TiDB 在云上服务 - DBaaS 的一个升级难题。在 DBaaS 里面,我们使用 K8s 来部署运维 TiDB,但是,如果我们只想更新 TiDB,之前我们不得不去干掉 TiDB 的 Pod,这个对用户业务可能会有影响,因为干掉 Pod 意味着要停掉 Pod 里面的所有服务,重启的 Pod 又可能因为资源问题调度不回原来的节点。2021 团队通过定制了一个新的 statefulset 资源,很好的解决了升级 TiDB 的问题。
在云上面,因为我们能使用 EBS 等云盘,所以能做到存储空间的垂直扩容,但是在私有环境下面,因为多数时候 TiDB operator 还是使用的本地磁盘,所以就面临着本地存储的扩容管理问题。而 young队 则在本地盘管理上面,通过 LVM 等技术,支持动态 PV 分配,在线扩容,更厉害的是,他们还支持了超分,真的让 TiDB 像跑在云盘上那样了。
这章节最后再说说 Ti-Improve 项目,这也是我非常喜欢的项目,而且这个在我们这边的落地难度几乎为 0,但给我们带来的价值确实无可限量的。这个项目的原理非常的简单,就是尽量利用云上面的服务,来提升我们整个工程效率。在这次的活动中,Ti-Improve 团队通过 AWS 的 CloudFormation,pipeline 等来编排集群场景,通过 lambda 来执行测试用例,通过 Cloud watch 来收集 metrics 进行观察,这一切全发生在云上面,而且比之前我们开 EC2 来搞整套,效率能提升 10 倍以上,云上成本也能降低很多。这次尝试更加加深了我对研发团队进行整个云上工程体系的拥抱的决心。
效率工具
我一直喜欢自己折腾小工具来提升自己的工作效率,所以当我看到这次活动有如此多的工具的时候,我其实惊呆的下巴都掉下来了。
首先就是团团圆圆的 XEUS TiDB,对于搞 ML 相关的同学来说,Jupyter 是一个不能在熟悉的 notebook 了,所以这次我们就看到了团团圆圆对 TiDB 在 Jupyter 里面的支持。想想后面的一个场景,作为一款 HTAP 数据库,数据分析师们在 Jupyter 上面通过 TiDB 实时的画出了学习图表,这个是多么美妙的一种体验。
对于 TiDB 来说,Issue 的管理也一直是我们很头痛的一个地方。虽然我们提供了 issue 模板,但有些同学其实会不按照模板进行填写,导致 issue 的内容格式不统一,我们其实不好在后台用 bot 来规范化处理。另外,对于报 issue 的同学,有时候会忘记填写是哪个版本出现的 bug,以及 bug 基本的复现步骤等。这些问题,zhangyushao 的 TiChi 项目,给我们提供了一个很不错的解决方案。原理其实也很简单,Github 支持通过外面的服务来创建 Issue,所以我们只要将用户引导到我们的一个标准页面去填写 issue 相关的信息,那么就能保证 issue 内容格式的统一,同时也能让大家尽量清晰的填写 bug 的影响版本,复现步骤这些。
除开 issue,文档也是我们一个老大难的问题了,PingCAP 有一个非常详细的文档规范,但我大概率猜想,很多同学在有时候会忘记这些规范。与其指望人能记住这么多的规范,还不如使用工具来解决这个问题,所以这次活动,zh.md 项目横空出世,不光帮 TiDB 找到了多个格式问题,也顺带爆出了 Flink 文档的几个问题。我非常相信,这个项目,能在中国的技术文档社区,刮起一轮最炫格式风。
这个章节最后,来聊聊 B.A.D 的 TiCode 项目,看到这个项目,我不禁对我发出了几个灵魂拷问:
1. vscode 还能干什么事情?
2. 贵司的程序员还能干什么事情?
3. 贵司的 CTO 脑袋里面还能冒出来什么事情?
通过 TiCode,程序员能在 vscode 里面开发调试 TiDB,而且我们不光能本地调试,还能 remote 调试,还能通过脚手架功能定制 dashboard 界面,给 coprocessor 写下推函数,我已经不能用我的言语来形容这个项目了。
前沿试水
这次 Hackathon,很多前沿研究,让我看到了未来 TiDB 无限的可能性。
如何将 TiDB 引入机器学习,是我们一直在思考和尝试的方向。这次 Hackathon,XuanyuanDB 团队通过强化学习来做了一点点尝试,不过可惜最后没有很好的效果展示。但另一个 Bourbon 团队实现,则让我非常的期待。Bourbon 的名字其实就是用的去年 VLDB 维斯康星麦迪分校发的一篇 Paper 的项目名字,在 Bourbon 这个项目里面,他们将 learned index 应用到了 LSM tree 上面,在一些 workload 上面取得了很不错的测试效果。为什么我们特别关注 learned index 相关的领域,主要一个原因在于我们坚信,未来的数据库是一个自适应的数据库,能自动根据用户的负载去调整底层的数据结构,从而更好的服务用户,而 learned index 则是这个方面一个可行性尝试。
图数据库也是大家非常关注的一个领域,这次 TiGraph 团队的项目可以说是让 TiDB 支持 Graph 一次非常不错的尝试。他们不光提供了一套非常易用的 Graph 语法(主要是现在图数据库的语法是在是有点难用),更重要的是能提供实时强一致的图查询解决方案。当然,这个项目落地还是没有那么容易的,不过我看到了未来无限的可能性。
再来说下另外一个让我感到非常震撼的硬核项目,来自于 Phantom Ensemble 团队的 Deterministic transaction,也就是俗称的确定性事务。可能很多同学第一次了解这个名词,但我是非常的激动的,因为如果这个项目能落地,在分布式事务上面,能让 TiDB 无论是稳定性,可调试性,延迟上面,都受益颇多。不过这次比赛他们只是实现了单点定序,还没去挑战我认为更困难的分布式定序,以及在分布式定序下的性能问题,这块也是业界一直没怎么好解决的地方,希望后面我们能有突破。
最后,再来聊聊滑滑蛋团队的驾驶舱项目,这个项目从一开始大家就是非常期待的,虽然短期落地的可行性太低,毕竟公司可没钱给运维同学去买一套模拟驾驶舱。现阶段,这个项目只能展示 Grafana metrics,但如果我们真的能支持好仪表盘操作,那想象空间就无限了,譬如我们可以通过按钮来控制 TiDB 集群的启停,通过摇杆来控制 TiDB 集群运行的方向,躲避 chaos 攻击,这特么完完全全就是一个实况机战游戏了。em,上述纯属作者脑洞,如有雷同,纯属巧合。
总结
TiDB 2020 Hackathon 虽然已经结束,对于我们来说又是一个新的开始,我们需要将这次活动里面涌现出来的好点子,尽快的评估,规划到 TiDB 整个产品线里面,让 TiDB 给用户带来更大的价值。
当然,好的点子并不是只有在 Hackathon 才能产生,我相信大家平常都有非常多的点子冒出来,大家可以通过各种渠道联系到我们,告诉我们你的想法,你也可以直接参与?TiDB incubator。
当然,如果 PingCAP 这种极客文化吸引到了你,愿意来贵司工作,我们也是非常的欢迎,也欢迎给我发邮件 tl@pingcap.com。
我们即将开启 TiDB Hackathon 2020 优秀项目赛队访谈系列,将会为大家深入介绍他们的项目设计思路、实现过程以及未来工作方向,希望带给大家一些启发。敬请期待!
关注公众号:拾黑(shiheibook)了解更多 [广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 PingCAP
PingCAP
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675