现在都 2021 年了,机器学习好填的坑都已经填了,大家都在想怎么将模型用到各种实际任务上。我们再去讨论深度学习框架,吐槽它们的体验,会不会有点过时?并不会,新模型与新算法,总是框架的第一生产力。
从 Theano 一代元老,到 TensorFlow 与 PyTorch 的两元世界,到现在各个国产框架与工具组件的兴起。深度学习框架,总是跟随前沿 DL 技术的进步而改变。不过今天并不是讨论深度学习框架的演变,而只是单纯分享一下在算法工程中,使用 TensorFlow 遇到的各种问题与感想。TensorFlow 2.X 已经正式发布 1 年多了,一周多前?TF 2.4 刚刚发布,看 Release Notes 最新版仍然关注多机并行训练、Keras 性能等新模块,甚至发布了「TensorFlow 版」的 NumPy 工具。然而,除去这些新特性,TF 2.X 很多不和谐的问题仍然存在。以至于,一直维护 TF 1.15 的算法工程师,似乎 TensorFlow 的更新,对自己没有任何影响。TF 1.X,仍然活跃在众多的 GPU 上。如果我们开始一项新任务,最先要做的就是查找已有的研究,以及已有的开源代码。这样的开源代码,即使到现在,很多最新的前沿模型,尤其是谷歌大脑的各项研究,仍然采用的 1.X 的写法与 API。比如说,预训练语言模型 T5、Albert、Electra 或者图像处理模型 EfficientNet 等等。他们实际上还是用 1.X 那一套方法写的,只不过能兼容 TensorFlow 2.X。你会惊奇地发现,它们的 TensorFlow 导入都是这种风格:import?tensorflow.compat.v1?as?tf
import?tensorflow.compat.v2?as?tf
其中,「compat」是 TF2.X 专门为兼容 TF 1.X 配置的模块。目前,还是有很多前沿研究,放不下 TF 1.X。那就更不用说之前的经典模型,绝大多都是 TF 1.X 写的。不过如果只是导入「compat」模块,那么使用 TensorFlow 2.0 是为了什么?难道只是馋它的版本号么。假设我们要使用这些 TF 模型,从开源代码开始进行修改或重写。那么就遇到了第一个问题,我到底是维护一个 TF 1.X 的代码库呢,还是忍痛更新的 2.X?假定我们决定维护 1.X 的静态计算图,那么你会发现,我们写代码只是在写计算图,中间变量打印不出信息,循环语句或条件语句,基本都要改成矩阵运算形式。TF 1.X 还是挺费劲的,就说打印变量,只调用 tf.print() 还不行,你还有将这条语句绑定到主要计算流程上,控制 Dependency。这样,才能打印出真实的矩阵信息。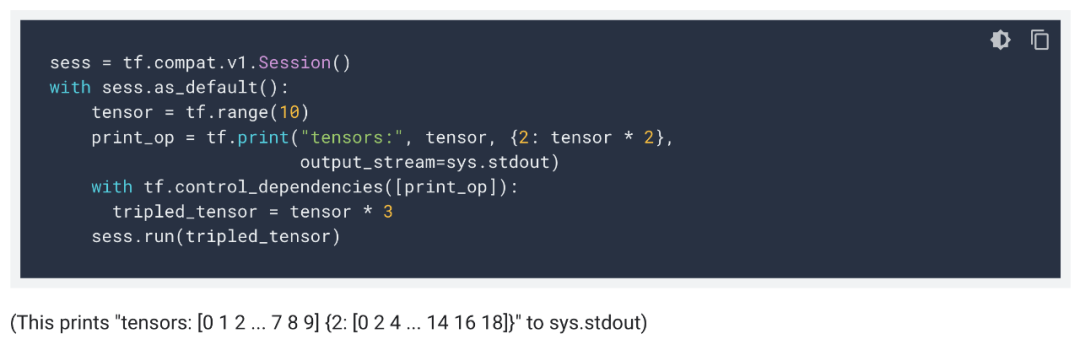
假设我们选择更新到 TF 2.0,基本上就相当于重写模型了。官方确实有一个升级脚本: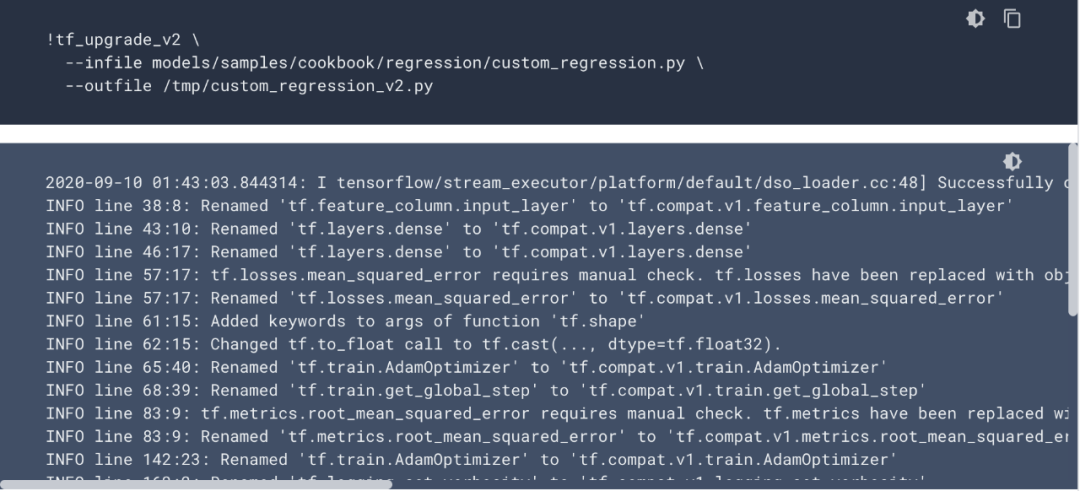
但是看上面日志也就知道,它差不多等同于「import tensorflow.compat.v1 as tf」。真正要利用上 TF 2.0 的 Eager Exexution,还是得手动重写。Tensorflow 1.X 时代,静态图虽说上手稍微难了那么一丢丢,但是这并不是什么问题。既然入了机器学习的坑,这当然是能掌握的。TensorFlow 1.X 不好用的主要原因,还在于 API 接口比较 混乱。说到底,它们都是基本的神经网络层级,很多时候都是有重叠的。这种 API 上的冗余,极大地降低了 TF 的生态质量。尤其是,很多官方教程,很多谷歌开源的模型代码,都用的是 tf.contrib.slim 来写模型。比如说 MobileNet 之类的经典模型,官方实现就是用 TF 第三方库「contrib」中的一个模块「slim」来写的。
然后到了 TensorFlow 2.X,整个「contrib」库都被放弃了。在 1.X 后期,各个教程使用的接口都不相同,我们又分不清楚哪个接口到底好,哪个到底差。由此引出来的,就不仅是很差的用户体验,同时还有性能上的差异。如果我们用 1.X 中的 tf.nn.rnn_cell 来做 LSTM,这也是没问题的,只不过会特别慢。如果我们将运算子换成 LSTM,那么无疑速度会提升很多。整个 TF 1.X,在 API 接口上,总是存在大量的坑,需要算法工程师特别注意。虽然说 TF 2.X 方向很明确,默认采用动态计算图,大力推进 tf.keras 这样的高级 API。这些都非常好,甚至用 Keras 写模型比 PyTorch 还要精简一些。但是别忘了 TF 传统艺能是静态计算图,它天生就比 tf.keras 拥有更多的底层配置。这就会导致两种割裂的代码风格,一种是非常底层,使用 tf.function 等更一般的 API 构建模型,能进行各方面的定制化。另一种则非常抽象,使用 tf.keras 像搭积木一样搭建模型,我们不用了解底层的架构如何搭建,只需要关注整体的设计流程即可。如果教程与 API 对两种模式都分的清清楚楚还好,但问题在于,引入 Keras 却让 API 又变得更加混乱了。
TF 2.X 官方教程目前以 Keras API 为主。
这其实和 1.X 的情况还是挺像的,同一个功能能由不同的 API 实现,但是不同 API 进行组合的时候,就会出问题。也就是说,如果我们混淆了 tf.keras 和底层 API,那么这又是一个大坑。比如说使用 tf.keras,以 model = tf.keras.Sequential 的方式构建了模型。那么训练流程又该是什么样的?是直接用 model.fit() ,还是说用 with tf.GradientTape() as Tape 做更具体的定制?如果我们先自定义损失函数,那这样用高级 API 定义的模型,又该怎么修改?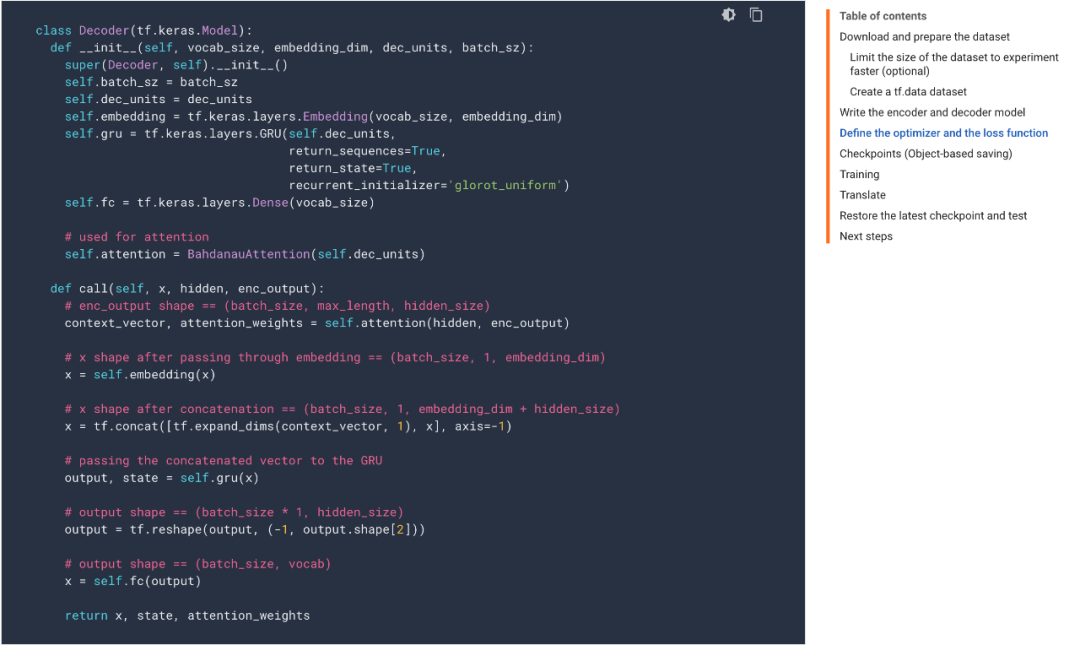
TF 2.X 官方教程,有的以类继承的新方式,以及更底层的 API 构建模型。本来还没进入 TF 2.X 时代时,keras 与 tf 两部分 API 互不影响,该用哪个就用哪个。但是现在,tf.keras 中的高级 API,与 tf 中的底层 API 经常需要混用,这样的整合会让开发者不知所措。与此同时,API 的割裂,也加大了开发者寻找教程的难度。因为除了「TF2.0」 这个关键字,同时还要弄清楚:这个文档是关于 TF2.0 本身的,还是关于 tf.keras 的。不管怎么说,TensorFlow 都是第一大深度学习框架,GitHub 上高达 15.2 万的 Star 量远超其它框架。其实在 TF 早期使用静态计算图的时期,整体教程还是比较连贯的,静态计算图有一条完整的路线。而且我们还有 tensor2tensor 这样的代码库,里面的代码质量还是非常不错的。后来随着深度学习成为主流,也就有了各种非官方教程,tf.contrib 模块里面的代码也就越来越多。?到了 TF 2.X,tf.keras 整合进去之后,相关的文档还是比较少的,以至于整个指引文档成了 Keras 和经典 TF 的混合。还是拿之前的例子来说,在官方文档上,如果要做图像识别,教程会告诉你用 tf.keras.Sequential() 组合不同的神经网络层级,然后依次定义 model.compile() 与 model.fit(),然后深度学习模型就能训练起来了。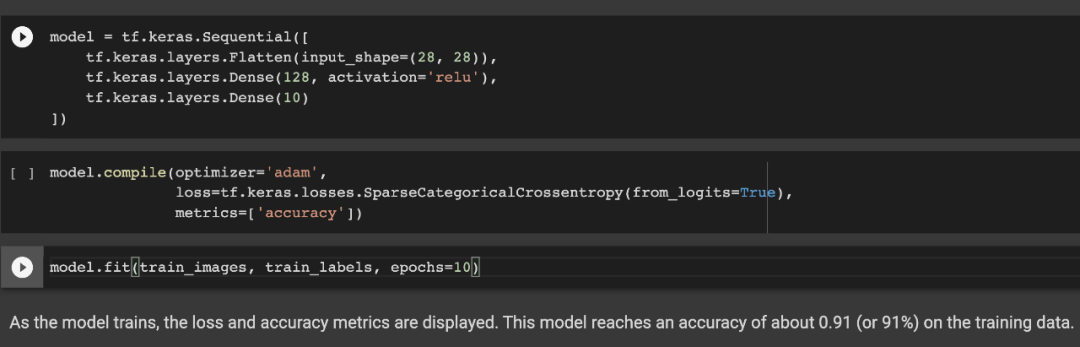
同样,如果要做图像生成模型,那么教程还是告诉你用? tf.keras.Sequential() 组合神经网络层级,但接下来却需要自己定义损失函数、最优化器、控制迭代梯度等等。@tf.function、tf.GradientTape() 等等新模块,都会用上。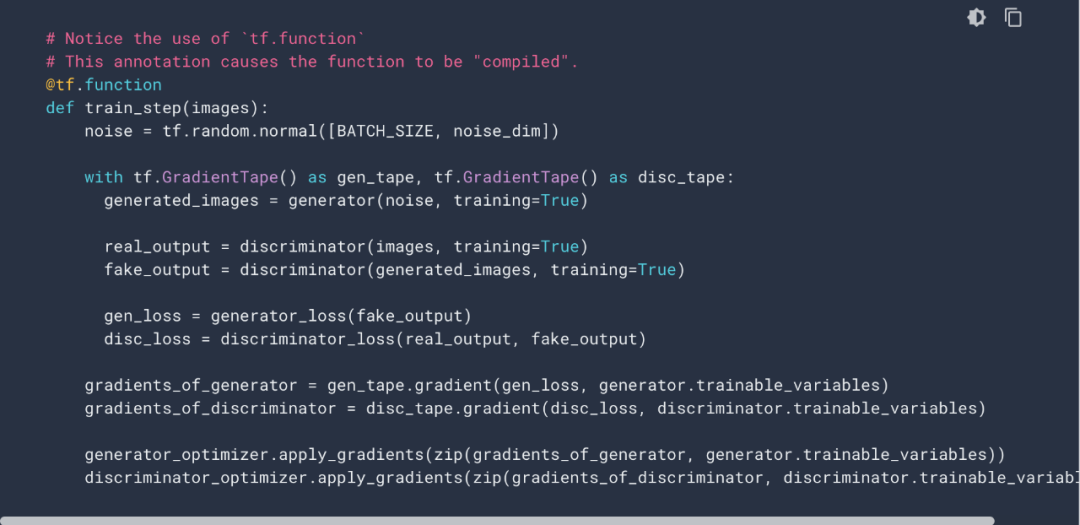
采用 @tf.function、tf.GradientTape()? 等 TF 2.X 新特性的一个示例。
除了这两种,对于更复杂的模型,TF2.0 还有一套解决方案,即从 tf.keras.Model 继承模型,重新实现 call 方法。总之官方文档有多种解决方案,能处理相同的问题。这种高级 API 与底层 API 混合在一起的做法特别常见,因此很多时候会感觉 TF 2.X 的技术路线不是非常明确。此外,tf.keras 是个「大杂烩」,神经网络层级、最优化器、损失函数、数据预处理 API 等等都包含在内。它要与 tf.nn、tf.train、tf.data 之类的 API 在相同层级,总感觉有点怪怪的。看上去底层 API 与高级 API 两大类文档,应该是平级的,这样找起来比较好理解。
按理来说,TensorFlow 的速度优化的应该还是可以的。而且本来各框架的速度差别就不是很明显,所以速度上应该没什么问题。但是在做算法工程的时候,总会听到周围的朋友抱怨 TensorFlow 的速度还不如 PyTorch,抱怨 TF 2.0 尽管用上了动态计算图,但速度还不如没升级之前的 TF 1.X 代码。这样抱怨最大的可能性是,在做算法时选择的 Kernel 不太对,或者计算流、数据流在某些地方存在瓶颈,甚至是某些训练配置就根本错了。所以说,速度方面,很可能是我们自己优化没做到位。但是 TF 1.X 升级到 2.X 之后,速度真的会有差别吗?笔者还真的做过非标准测试,如果使用升级脚本完成升级,同样的代码,两者底层的计算子还真不一样。速度上甚至 TF 1.X 略有优势。在最初的 TF 1.X 代码中,很多矩阵运算用的都是 tf.einsum(),静态计算图应该把它都转化为了 MatMul 等计算子,整体推断速度平均是 16ms。
而如果根据 tf.compat.v1 升级代码,相同的模型确实底层计算子都不太一样。但没想到的是,TF 2.X 采用了新的 Einsum 运算,速度好像并不占优?
最后,我们想说的是,作为AI工程师,选择适合自己的深度学习框架需要认真考虑。虽说大家很多都用 TensorFlow,但维护起来真的有挺多坑要踩。而且一升级TF 2.X,就相当于换了个框架,十分麻烦,甚至不如根据业务情况重新考虑其他框架。
放眼望去,国产的几种框架也许会是不错的选择。它们至少都能经受得起业务的考验,且与框架维护者交流起来也会比较方便。此外,一些国产新兴框架,没有历史包袱,技术路线比较统一与确定。一般而言,只要训练效率高、部署方便高效、代码比较好维护,且能满足业务所在领域的需求,那么这就是个好框架。
总而言之,适合自己的才是最好的。
??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




