
性能竞赛优秀项目 | 分得干脆、合得高效,用 Shuffle 优化 TiDB 算子
作者介绍
黄建博,云计算领域技术开发工程师;金灵, Shopee 软件研发工程师。
他们的队伍 huang-b 在性能竞赛中斩获一等奖,本文将介绍 Shuffle 优化 TiDB 算子项目的设计与实践过程。
技术背景

题目链接:
1. ShuffleMergeJoin: https://github.com/pingcap/tidb/issues/14441
2. ShuffleStreamAgg: https://github.com/pingcap/tidb/issues/20651

图 1? Window 算子并行化
ShuffleMergeJoin
扩展 Shuffle 算子
对 MergeJoin 做并行优化,是不是简单套用 ShuffleWindow 的框架就可以了呢?不是的,MergeJoin 算子与上文的 Window 算子不同,MergeJoin 需要两个数据源。那现在的 Shuffle 实现能不能让每个并行算子对应两个 ShuffleWorker ,进而对应两个数据源呢?答案也是不可以,因为前文提到的 Shuffle 实现把数据分区和计算并行这两个功能过度耦合在一起了,这种过度耦合使得它无法支持两个数据源。下面我们对这个问题作具体说明。
过度耦合指的是 ShuffleWorker 充当的角色太多,它既是数据流动的一环,同时也是计算并行的基本单元,于是带来了这两个问题:
1. 因为 ShuffleWorker 时数据分区,所以并行后的每个 MergeJoin 需要两个 ShuffleWorker 来接收来自两个数据源的数据,但是 ShuffleWorker 同时又是计算并行的基本单元,于是有 n 个 MergeJoin 算子就会出现 2n 个协程,同一个 MergeJoin 算子的两个协程还会出现数据竞争。
2. 控制逻辑复杂, ShuffleWorker 作为数据的一个分区,它必须作为 Sort 算子的子节点,而它作为计算并行的基本单元,又必须在协程中调用 Window 算子的 Next 方法来完成计算,所以在原来的实现往 ShuffleWorker 里放了个指向 Window 算子的指针,这样的设计一方面存在破坏执行树有向无环特性的隐患,另一方面也降低了代码的可读性。
当然,第一个问题我们可以通过在 ShuffleWorker 中增加一个布尔变量来解决:同一个 MergeJoin 对应的两个 ShuffleWorker 一个为 true,一个为 false,只有为 true 的那个才会启动协程。可是这个方法无疑会使上面提到的复杂的逻辑更加复杂。
我们提出的解决方案是把数据分区和计算并行解耦。如图 2 所示:计算并行还是由 ShuffleWorker 负责,但是它不再是数据流动过程中的一环,它原来在数据流动过程中的位置由 ShuffleReceiver 来代替。MergeJoin 是 ShuffleWorker 的一个成员,每个 ShuffleWorker 对应一个协程,在协程中调用 MergeJoin 的 Next 方法,并将结果发送给汇总算子,这样上文中提到的两个问题都得到了解决。
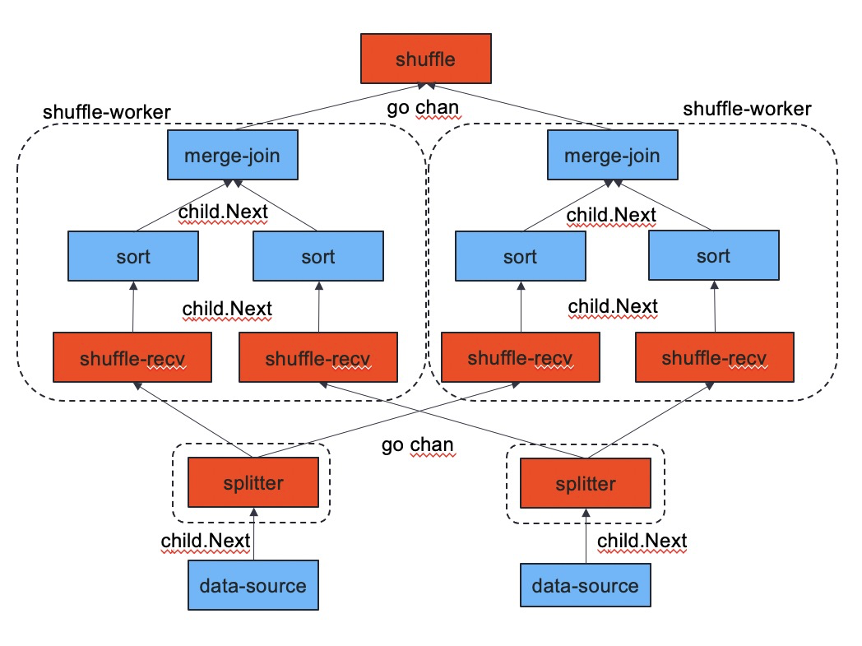
图 2 拓展后的 Shuffle 算子
实现与效果
在实现中我们考虑两个场景:其一是数据源本身无序的情况,这种情况下数据进入 MergeJoin 之前要先经过 Sort 节点;另一是数据源本身有序的情况,这种情况下数据进入 MergeJoin 之前无需排序。

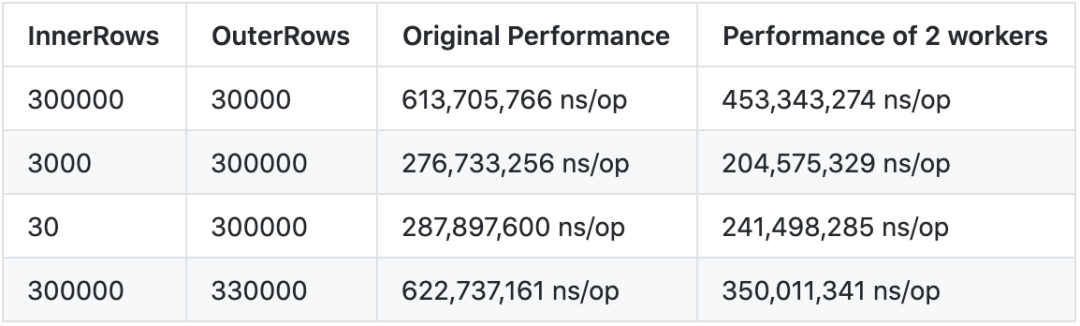

图 4 数据源有序情况下的 ShuffleMergeJoin
相关 PR:
1. ShuffleMergeJoin 实现:https://github.com/pingcap/tidb/pull/21255
2. 控制参数:https://github.com/pingcap/tidb/pull/21332
3. 单元测试与性能测试:https://github.com/pingcap/tidb/pull/21360
ShuffleStreamAggregation
实现与效果
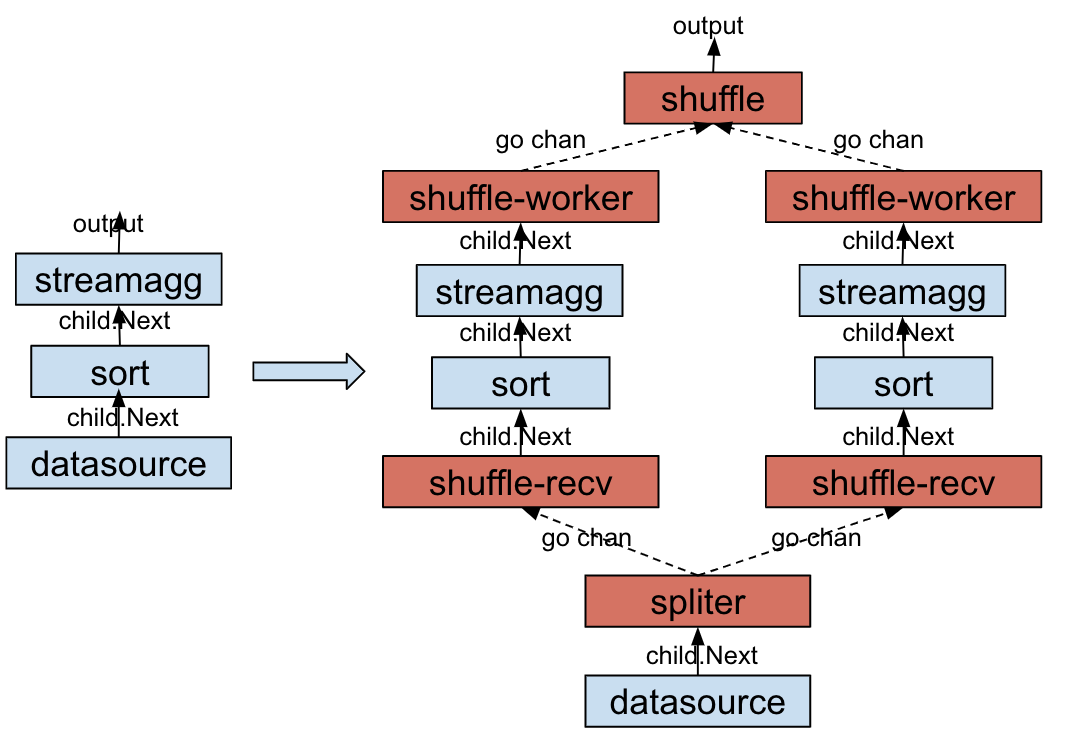
图 5 数据源无序情况下的 ShuffleStreamAggregation
针对这种场景,我们的方法最后取得了非常明显的性能提升(如表 2 所示)。分析认为,非并行的情况下,Sort 作用在整个 DataSource 之上,而并行化的版本是作用在每个不同的 Partition 之上,输入相对较小,且并行执行,因此性能提升较大。

表 2 ShuffleStreamAggregation 优化效果
另外,还需要考虑 DataSource 在被聚合 key 上是有序的情况,比如下面的 SQL 语句,被聚合 key 为 b,且输入数据源 t 上刚好有由 b 创建的索引,因此在具体的计算过程中, DataSource 是基于 b 的 PhysicalIndexTableReader ,那么我们就无序引入 Sort 算子,直接将输入分割成多个 Partition,然后经过图 6 所示的计算过程即可得到结果。
create table t(a int, b int, key b(b));select /*+ stream_agg() */ count(a) from t group by b;

https://github.com/pingcap/tidb/pull/20658 https://github.com/pingcap/tidb/pull/21095
RangeSplitter
上面说了, Shuffle 算子会把数据输入分割成多个 Partition,最开始的时候只有基于 Hash 方法的 Splitter 被实现,该实现对输入数据是否有序并不做要求。对于数据源有序的情况,尽管该方法依旧适用,但是使用基于 Range 的方法对数据源进行分割,是一个更为自然的方式,因为被聚合 key 相同的多行数据,必然是紧挨在以前的,如果可以直接找到这一块数据的起始点和结束点,整体一次性分割,则无需构建 HashTable,也不用调用开销更为明显的 HashFunction,使得Partiton 过程的开销更小。基于这一思路,我们实现了 PartitionRangeSplitter,该方法的计算原理是,将紧挨一起的相同聚合 key 的多行数据,批量地分发到一个 worker 之上。相较于基于 Hash 方法的 Partitioner 而言,基于 Range 方法的实现方式的开销更小,在同时处理有序输入数据源的情况下,使用 RangePartitioner 能比使用 HashPartitioner 快上一倍的速度(详见表 3),由此证明了该算子更加适用于数据源有序的情况。

表 3? RangeSplitter 与 HashSplitter 性能比较
还不过瘾怎么办?
一年一度的 TiDB Hackathon 已经正式启动!
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 PingCAP
PingCAP
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675