
无性能损失,不用更改代码,Lightning 1.1版本发布,切分训练新功能节省50%以上内存
机器之心报道
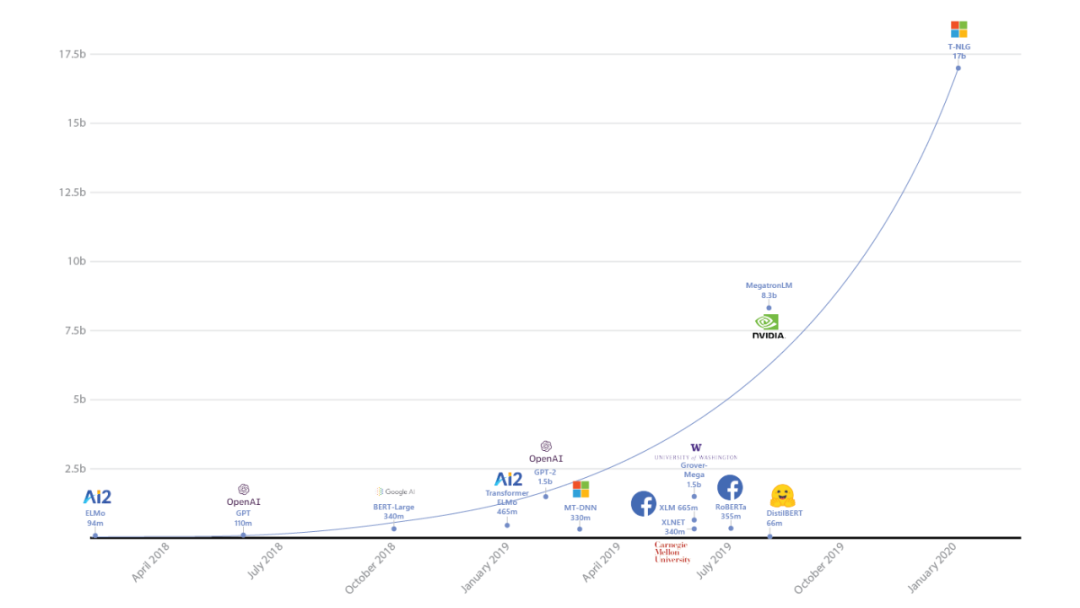
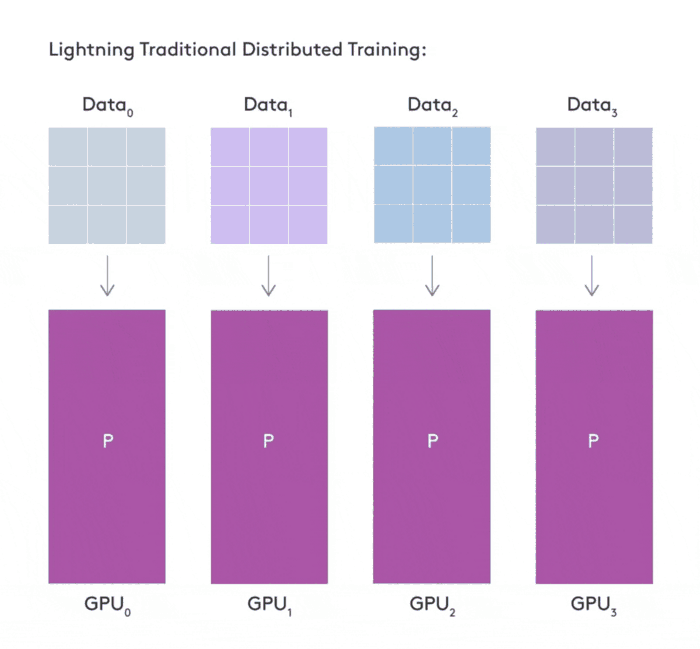
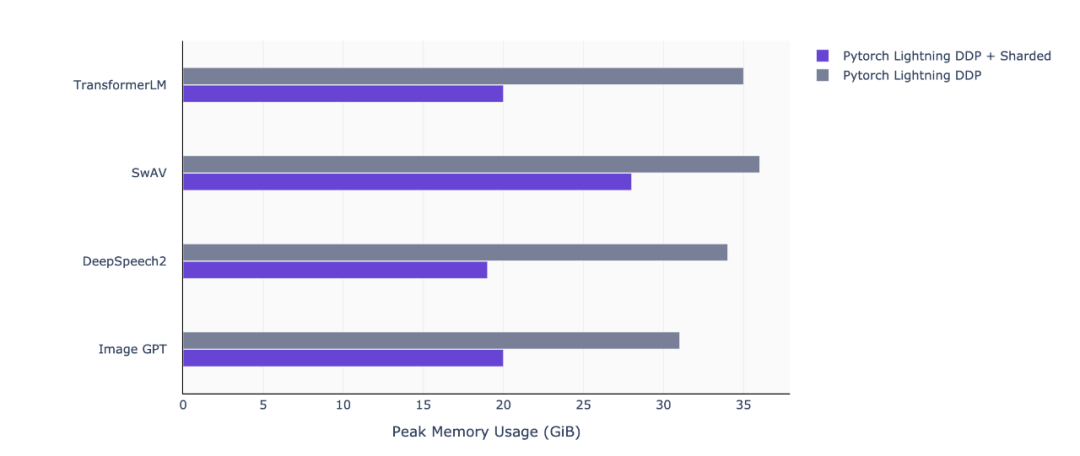
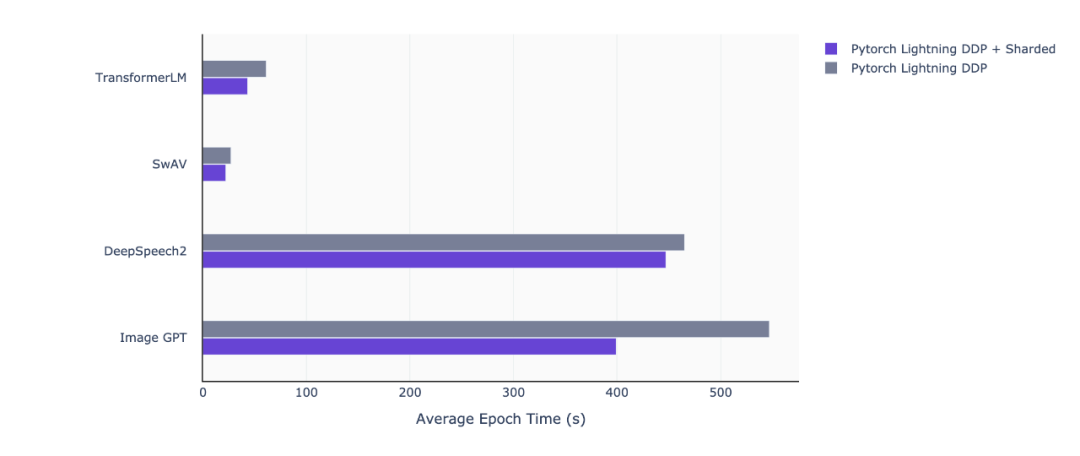
继 1.0.0 版本推出不到两个月的时间,grid.ai CEO、纽约大学博士 William Falcon 创建的 PyTorch Lightning 于近日宣布推出 1.1 版本。新版本新增了 sharded training 功能,在多 GPU 上训练深度学习(DL)模型时可以节省 50% 以上的内存,并且没有性能损失,也不需要更改代码。

import osfrom omegaconf import OmegaConf# Build a simple word based vocabulary for benchmarking purposeswith open('wikitext-2/train.txt') as f:vocab = set(f.read().split())with open('vocab.txt', 'w') as f:f.write('\n'.join(vocab))# Define the model configuration using the preset configuration file found within NeMoconfig_path = "./examples/nlp/language_modeling/conf/transformer_lm_config.yaml"config = OmegaConf.load(config_path)config.model.language_model.vocab_file = 'vocab.txt'config.model.train_ds.file_name = os.path.join('wikitext-2/train.txt')config.model.validation_ds.file_name = os.path.join('wikitext-2/valid.txt')
import pytorch_lightning as plfrom nemo.collections import nlp as nemo_nlp# Set model parameters (roughly 1.2 billion parameters)config.model.train_ds.batch_size = 8 # Reduce batch size for training large modelconfig.model.language_model.hidden_size = 3072config.model.language_model.inner_size = 3072config.model.language_model.num_layers = 22# Use 8 GPUs, and enable Mixed Precision + Sharded Trainingtrainer = pl.Trainer(gpus=8,precision=16,max_epochs=50,accelerator='ddp',plugins='ddp_sharded')model = nemo_nlp.models.TransformerLMModel(cfg=config.model, trainer=trainer)
本周日,在北京有一场属于开发者的冬日狂欢。
王海峰、朱军、李宏毅等AI大咖畅聊产业、人才与开源。
30场技术公开课干货满满。 伴手礼人手一份,互动展区还有众多礼品等你来拿。 DJ、乐队、街舞、脱口秀同台 AI 狂欢夜。

??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675