
数据转换 :标准化vs 归一化(附代码&链接)
标准化和归一化的区别
何时使用标准化和归一化
如何用Python实现特征缩放
“特征缩放的目的是使得所有特征都在相似的范围内,因此建模时每个特征都会变得同等重要,并且更便于机器学习的算法进行处理。”
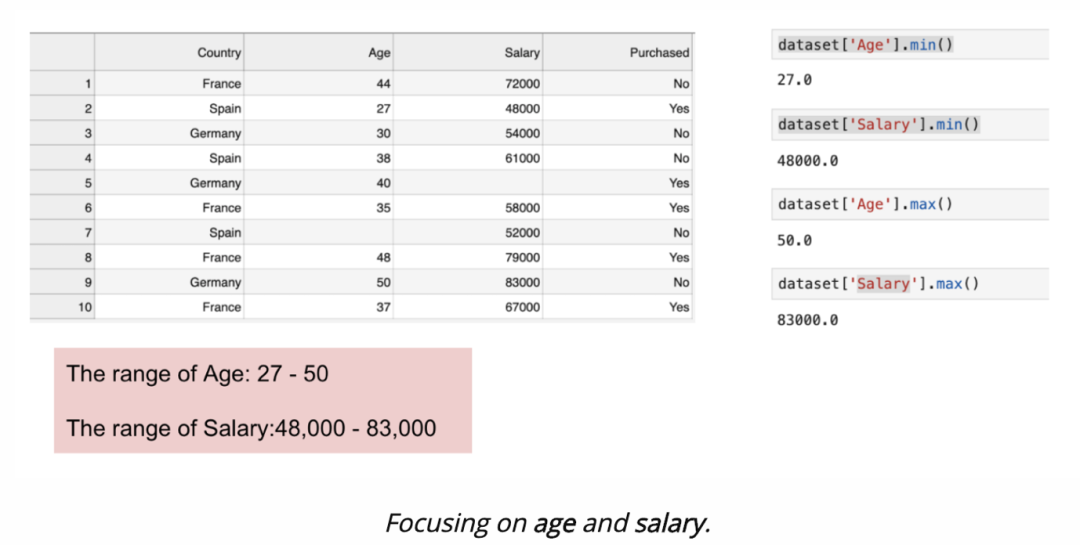

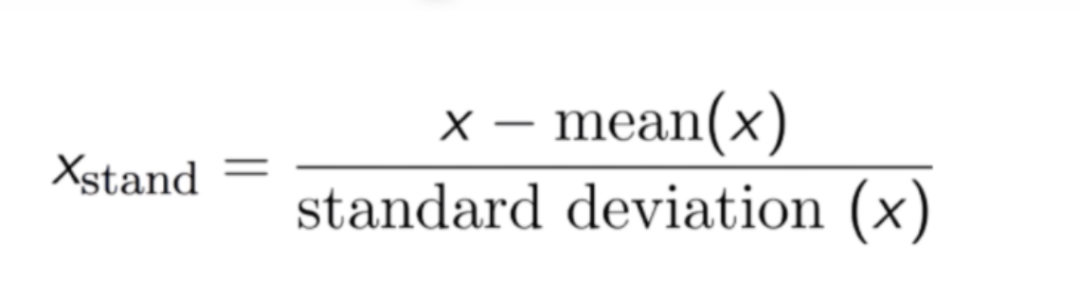


from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()scaler.fit(df)scaled_features = scaler.transform(df)#Convert to table format - MinMaxScalerdf_MinMax = pd.DataFrame(data=scaled_features, columns=["Age", "Salary","Purchased","Country_France","Country_Germany", "Country_spain"])
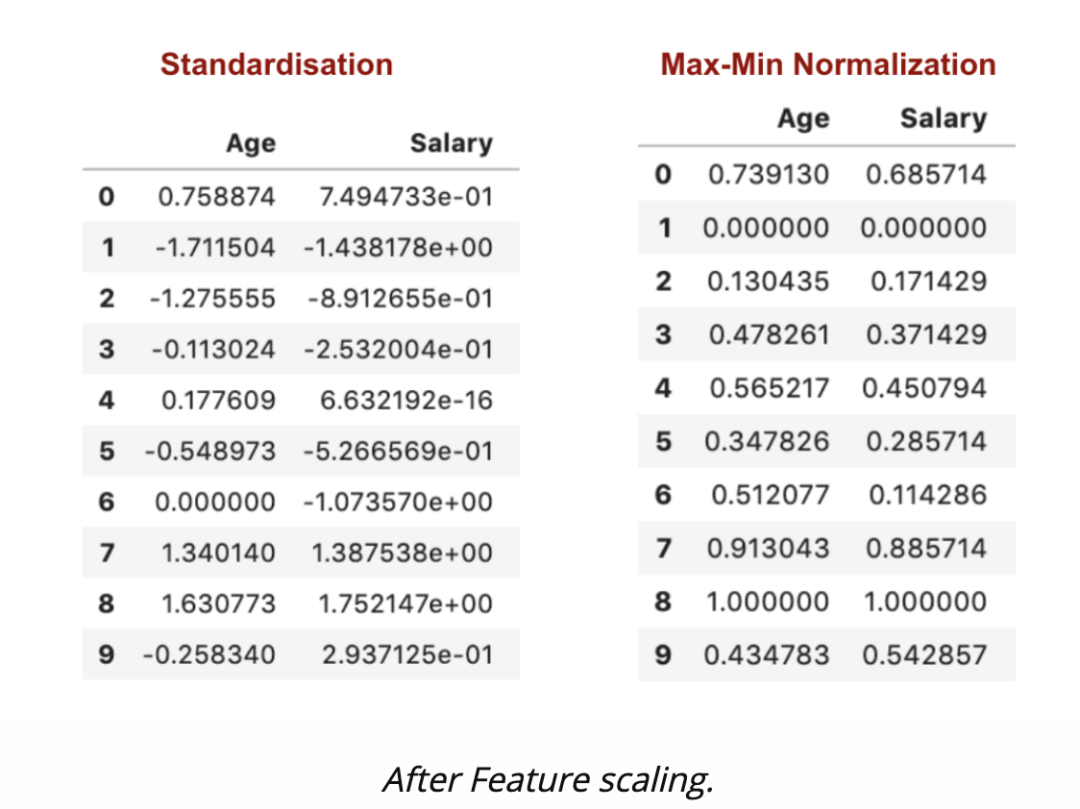
特征缩放后

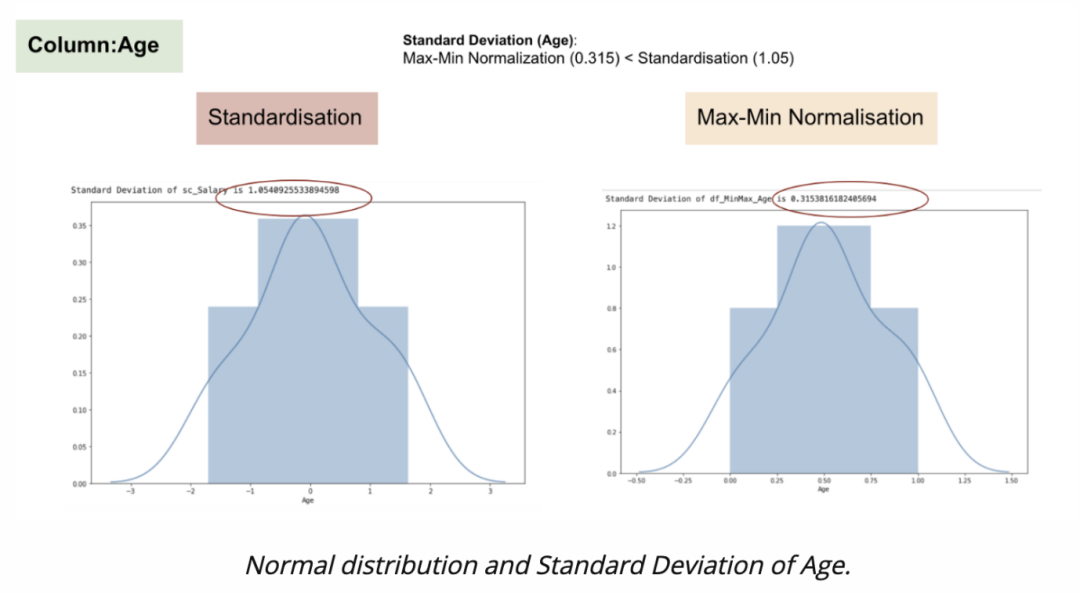
工资变量的常态分布和标准差
特征缩放的使用场景:


注:如果算法不是基于距离计算,特征缩放则不重要,比如朴素贝叶斯和线性判别分析,以及树模型(梯度提升、随机森林等)。
使用特征缩放的目的
标准化与归一化的区别
需要使用标准化或归一化的算法
在Python中实现特征缩放
获取代码和数据集合,请使用一下连接:
https://github.com/clareyan/feasturescaling
END
转自:?数据派THU 公众号;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
![象象Klaus:抽一个宝贝来我家喝酒[doge] ](https://imgs.knowsafe.com:8087/img/aideep/2021/7/31/77c36cd6f504b05f89d608451900609d.jpg?w=250)





 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675