
张冬梅:“数据淘金”之道

编者按:近日,在微软亚洲研究院第三届创新论坛上,各成员企业与微软亚洲研究院的计算机科学家们共同就 AI+ 行业的落地开展了一场跨越空间的思想碰撞。在论坛上,微软亚洲研究院副院长张冬梅博士做了题为《从数据处理到数据淘金》的主题演讲,分享了数据淘金的几大原则,以及她在研究过程中的感想与体会。本文是演讲的文字精简版。

▲?微软亚洲研究院副院长?张冬梅博士
今天我的演讲主题是“从数据处理到数据淘金”,这其中的重点是数据淘金,也就是从数据中发现价值,而且要在实际业务中体现价值,这样才是真正淘到了“金子”。其实,“淘金”的另外一种说法就是在实践当中,我们怎么去践行数据驱动的理念。今天我将跟大家主要分享三个原则,这不仅是我们多年研究和实践的体会,也是学界业界同行交流中的共同感受。
重要性原则
都知道数据很重要,但重视程度仍有不同
所谓重要性原则,是指数据以及从数据中获取价值的能力是非常重要的战略资产。该原则看似显而易见,但深刻理解却并非易事。
我们先来看一个信用卡行业的例子。在上世纪八十年代以前,判断消费者是否会违约都是通过手工评估完成的。在八十年代以后,专业人员使用数据建立了关于违约的概率模型,这样一方面提高了评估的准确性,另一方面扩大了评估的规模。这两个变化给消费者信用行业带来了根本性的转变。可是在转变之后,那个年代的信用卡基本上是统一定价的。其中的原因之一是信用卡公司还没有足够强大的信息系统来支持大规模的价格定制化服务。

九十年代,美国十大信用卡中心之一的 Capital One 公司创始人 Richard Fairbank 和 Nigel Morris 敏锐地意识到,利用当时的信息技术已经可以处理更加复杂的预测模型,从而使银行可以向自己的客户提供信用卡方面的定制化服务,例如不同的定制价格、不同的奖励积分以及不同的信用额度等等。随后,他们与各大银行分享了这个想法,希望有机会将想法付诸实践。遗憾的是,当时没有大银行愿意尝试。最后,只有一家区域性的小银行 Signet 接受了他们的想法。
Richard Fairbank 和 Nigel Morris 还面临着一个问题:因为银行以前对于所有的顾客一直是统一定价,所以没有历史数据可以用来建立他们两人认为需要的模型。于是他们决定投资去收集这种数据。两人开始随机向客户发放信用卡,而这导致最初几年 Signet 的违约金额从2.9%上升到了6%。几年之后,柳暗花明,Fairbank 和 Morris 的努力获得了成功,并使得这个信用卡部门从 Signet 分离出来单独运行,成长为今天我们所熟知的,在全球拥有超过48000名员工,年收入280亿美金的 Capital One。
从这个例子中,我们可以看到重要性原则的两个关键点:
一是,数据。我们所需要的数据目前可能并不存在,所以我们需要投资去收集数据,这个过程可能很漫长,需要耐心,也需要投入,而且可能是很高的投入。
二是,人才。Richard Fairbank 和 Nigel Morris 就是人才。在 Capital One 的案例中,当时数据已经被用来预测消费者违约的可能性了,利用已有数据继续改进这个预测模型也是有意义的事情。可是,Fairbank 和 Morris 并没有这样做,他们对消费者信用卡行业有着深入地思考,对数据也有深刻的思考和认识,从而发现了颠覆性的创新机会。
价值性原则:必须以结果为导向
无论是数据科学项目,还是数据智能项目,所有的结果和产出都必须有价值。这些价值体现在两个方面:
1. Insightful,洞察性。结果可以是之前未知的,也可以是之前模糊地知道但没有数据支撑的,亦或是之前只有浅层次的理解,知其然不知其所以然的。
2. Actionable,可行性。结果要能够对制定出具体行动措施有帮助,能够去改变现状。否则,它的价值就会大打折扣。
系统性原则:价值挖掘,有章可循
系统性原则就是如何从数据中挖掘出价值。它是有章可循的,要遵循一个系统性的,且各阶段定义相对明确的流程。这个流程叫 CRISP Data Mining Process,是一个跨行业的数据挖掘标准。CRISP 在1999年由一个有5个公司组成的联盟提出,它不绑定于任何行业、工具以及具体应用。这个抽象的特质使得 CRISP 是迄今为止在工业界使用最广泛的实践数据驱动(data-driven)的指导原则。
流程的六个步骤分别是:
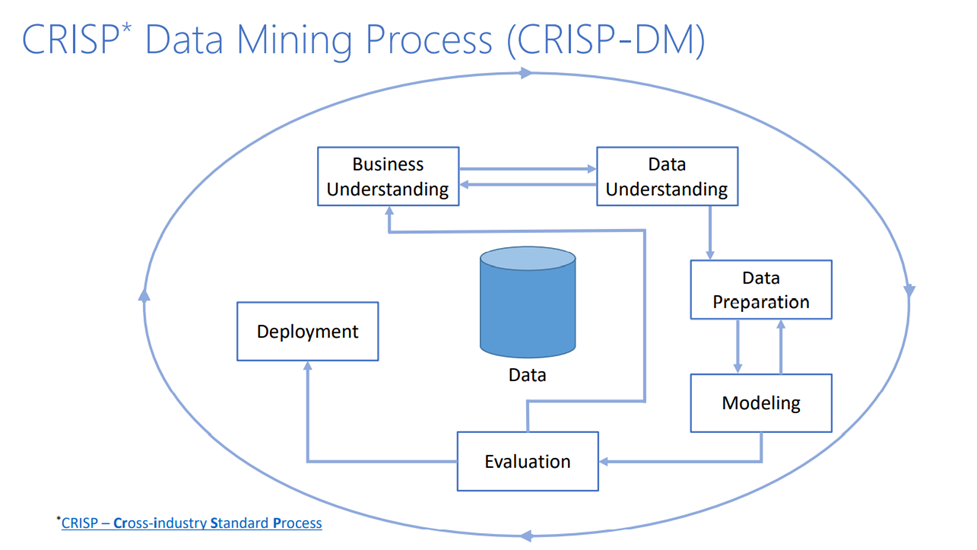

“业务理解” 就是一定要明确所要解决的问题到底是什么。这看起来似乎很显然、很简单,但在实践中开始做一个项目的时候,很少能遇到一个定义明确的机器学习问题,既没有歧义也没有差距,马上就可以开始建模。为了更好地理解业务,我们需要思考几个问题:我们究竟要实现什么目标,我们的用户场景是什么,我们具体要怎样做,有什么样的要求和限制,在整个问题中有哪些部分可以用机器学习或是数据挖掘的方法去解决?
除此之外,我们还要注意几点:一是对业务的理解往往不是一蹴而就的,它可能是个循序渐进的迭代过程,这在 CRISP 流程中也是有体现的。二是数据分析团队一定要和业务团队紧密合作,深刻理解业务目标和痛点,不要自以为是,闭门造车。
在讲数据理解之前,我要强调和数据相关的每一个步骤,包括收集、处理、使用等等,都必须合规。对数据价值的挖掘一定要建立在合规的基础上。
数据理解这一步共有六个方面:

a) Relevance,相关性。即已有数据和要解决的问题到底有关系还是没关系,有多少关系,有怎样的关系。
b) Completeness,完整性。多问为什么,了解整个业务蓝图是否获取了所能拿到的所有数据?是否还有之前没有想到的数据也可以拿来使用?不要只局限于已有的数据,要从更大的范围去思考。
c) Reliability,可靠性。数据中可能存在很大的噪声,不一定全部可靠。例如,市场调研中在用户反馈时,有的用户填得很认真,有的只是随便填填,这就会造成反馈的信息当中有很多噪声,需要经过处理才能使用。
d) Collation,是把不同来源的数据整合到一起。比如企业中有客户数据、有交易数据、有市场反馈数据等等。如果把这些数据整合到一起,就可以得到深层次的用户与商品之间的关系。在这里,collation 实际上提出的就是避免数据孤岛的问题,强调了企业中的各个组织在数据方面一定要合作共享。
e) Cost,关于投入。在这个阶段,我们要评估每一个数据源的成本和它的效益,从而决定是否要继续投资,获取更多质量更高的数据。
f) Availability,即有没有可用的数据。这个问题看似简单,但实际中由于场景不同,所以“有没有数据”的答案可能截然不同。举个例子,在信用卡欺诈的检测当中,如果用户在自己的账单上看到了她没有买过的商品,她会向信用卡公司进行报告,那么相应的交易就会被标记为欺诈。也就是说信用卡公司有关信用卡欺诈的数据是被天然标注好的,而且质量很高,因为在这个场景中存在利益诉求完全相反的两个群体。我们再来思考一下医保欺诈的场景。为了防止医保欺诈,我们同样要建立预测模型,可是这个情况下我们并没有标记数据,因为我们不知道哪些是正常的花费,哪些是夸大或者虚报的费用。造成这个问题的原因是在医保过程中,不存在利益相反的群体,骗保人可能是合法医疗服务提供商的一小部分,或者可能是合法使用医保系统的一小部分患者。
这个步骤的目的是把数据进行加工处理为下一步建模做准备。常见的处理方法包括统一数据格式、处理缺失数据、给数据去噪声、转换数据格式,以及汇总、标准化等等。

评测在 CRISP 流程中至关重要。我们在做评测的时候要注意以下几个要点:
第一,评测要严格、严谨。在机器学习和数据挖掘中有很多成熟的评测方法和准则,这些可以构成我们对模型评测的基础。
第二,评测阶段提供了一个很好的机会让我们再次审视我们的解决方案,看看它到底能不能很好地解决我们所面临的业务问题。在实践中我们经常会看到,模型的线下评测结果很好,但部署后却对业务问题帮助不大。这个时候我们一方面要反思对业务问题的理解,另一方面要查看评测指标是否恰当,是否在机器学习的常用评测方法之外,还需要定义和业务问题密切相关的评测指标。
第三,我们要对解决方案部署后在生产环境中可能产生的影响有正确的预期和预案。例如,如果我们的方案失败了怎么办?会引起什么样的后果?会对业务造成什么样的影响?我们有没有预案去控制影响的范围并且尽快调整方案以便快速恢复重新运行?作为业务负责人,这些问题都是必须思考和追问的。在决定是不是部署数据驱动的解决方案时,找到这些问题的答案就是正确决策的基础。
部署的方式千差万别,有的部署方式非常简单,贴个通告就好;有的部署方式非常复杂,需要修改计划、方针、政策等。如果是后者,那就可能牵扯到成本问题,因为做这些事情的时候,只有数据分析的团队是不行的,还需要具有数据处理知识的优秀工程人员一起合作,才能把部署做好。
对于整个闭环流程下的系统性原则,我们再次强调迭代、迭代再迭代。
最后,再回到数据淘金,这四个字本身与三个原则其实可以一一对应。“数据”反映了重要性原则;“金”体现的是价值性原则,告诉我们什么是金子;“淘”则体现了系统性原则。希望这些原则可以帮助到大家,在实际的工作中从数据里淘到真金,实现价值。
*参考文献
[1] Data Science for Business, Foster Provost and Tom Fawcett, July 2013, first edition.
[2] Software Analytics in Practice, Dongmei Zhang, Shi Han, Yingnong Dang, Jian-Guang Lou, Haidong Zhang, Tao Xie, IEEE Software 30(5):30-37, September 2013.

推荐阅读
精彩活动
K8S 联合创始人 Brendan Burns 邀您参加 Azure Innovation Summit 开源主题日

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 微软科技
微软科技
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675