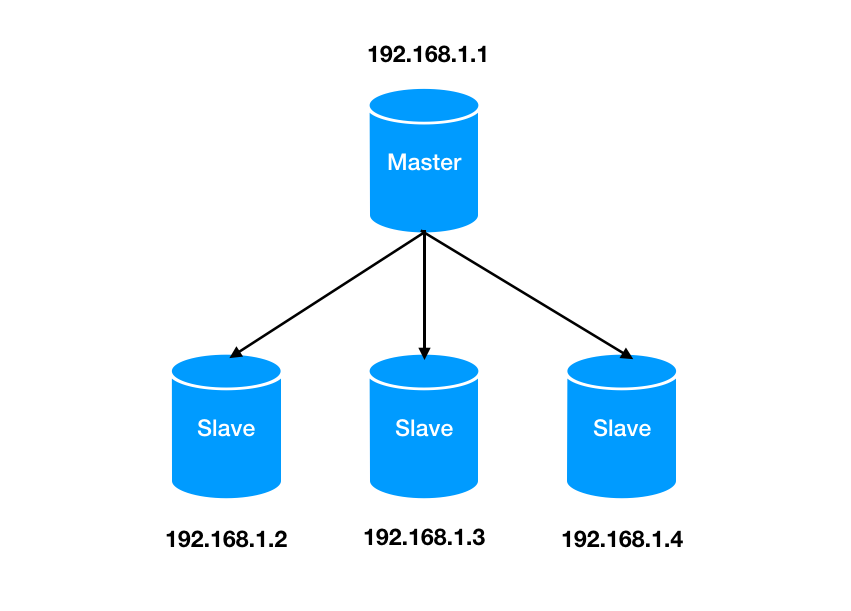
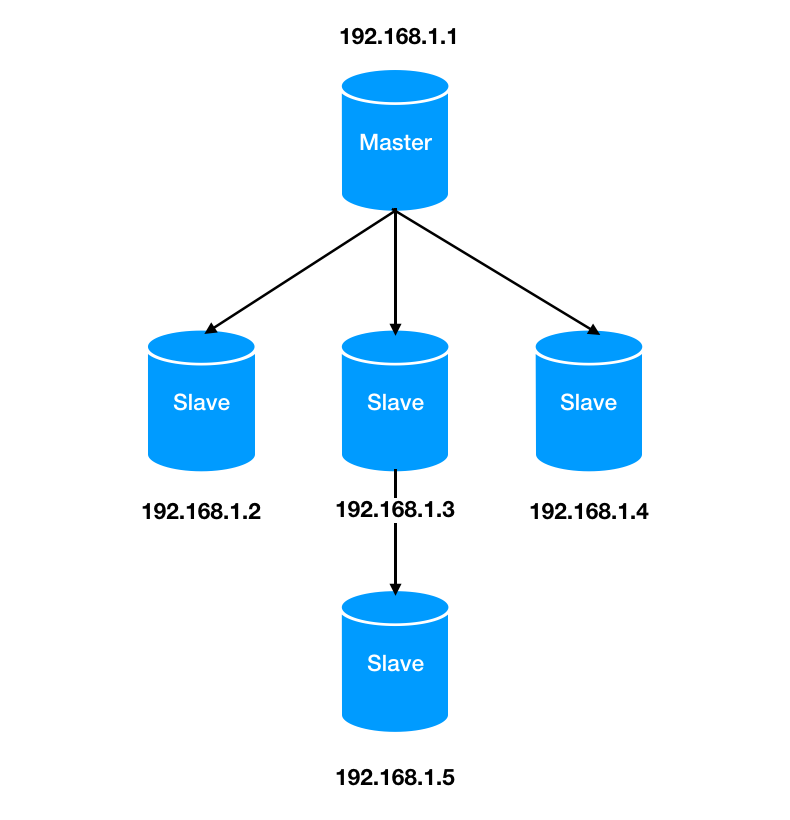
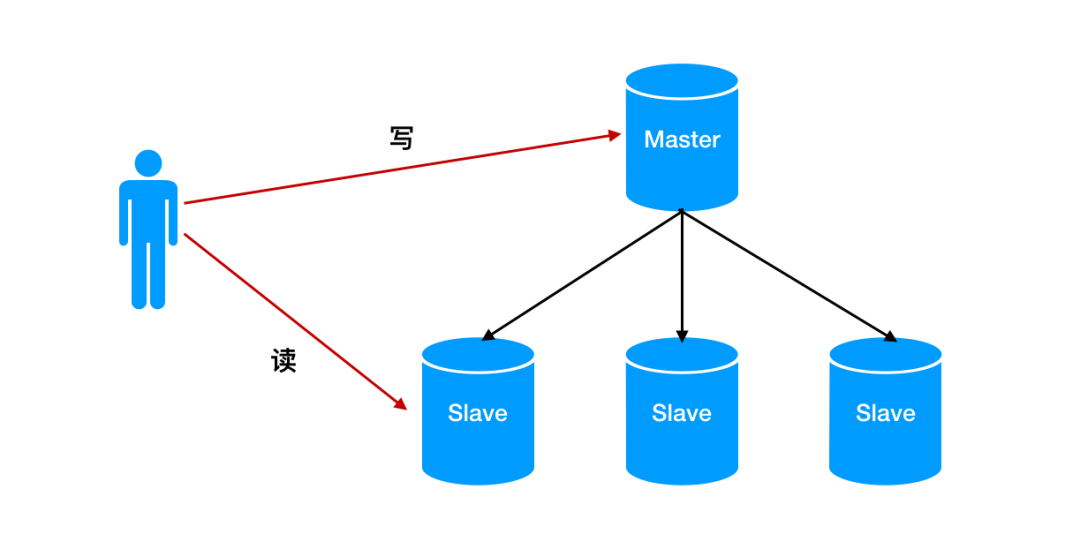
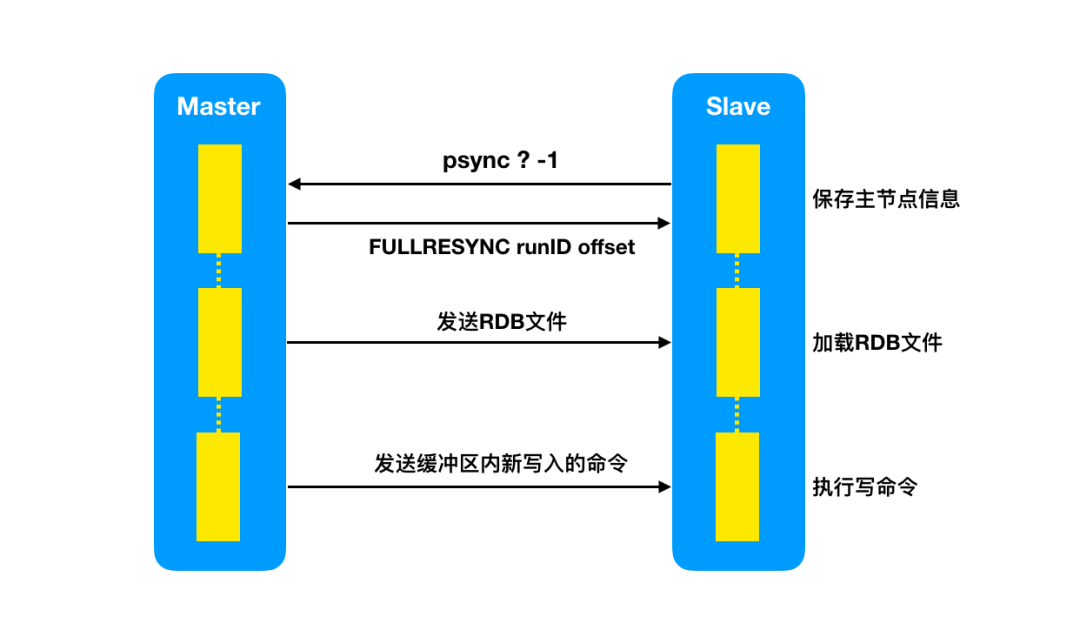
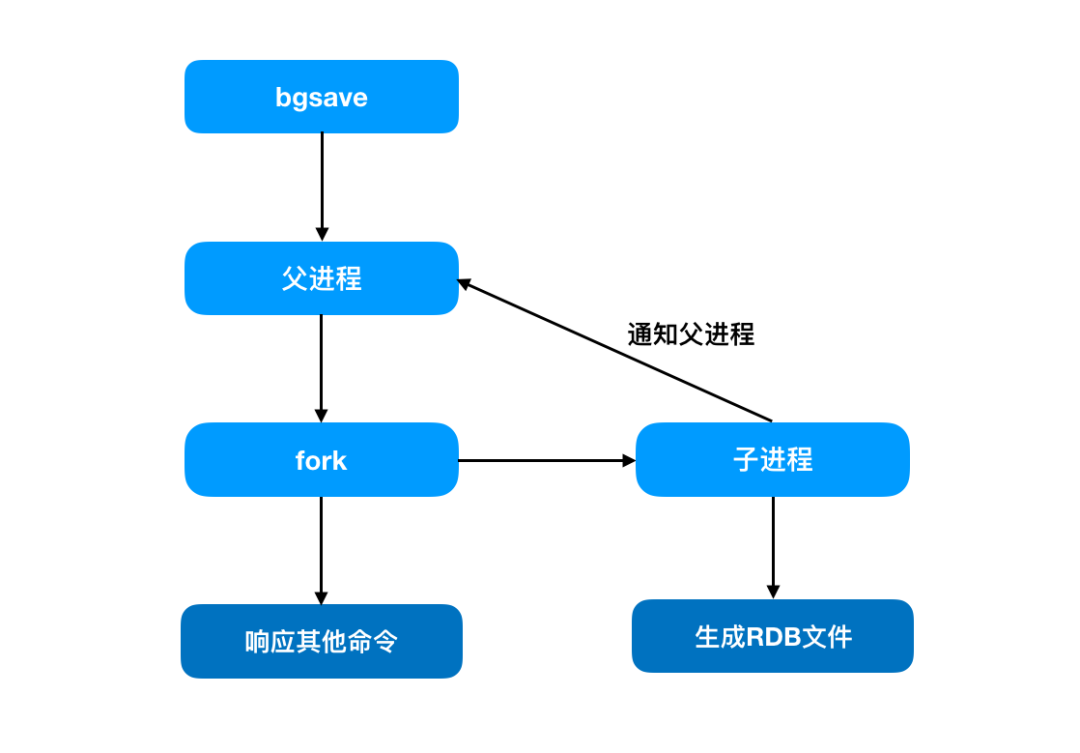
来源|?IT界农民工(id:kejishuqian)上周因为实在太忙就认认真真写了一篇水文,吹了一下自己过去的经历,反响竟然超出了我的预期,并且后台还有读者留言表示想看续集的。哈哈,果然大家还是对水文更有热情。这期我们继续回到之前的 Redis 话题。今天主要讲的是主从复制数据一致性相关以及面对网络中断如何进行数据同步的问题。 对于 Redis 主从大家可能并不陌生,但是配置的话日常工作中并不会经常操作。在这里简单介绍下主从的相关配置。对于主-从-从的模式来说,配置也与上边的操作类似,在这里就不多赘述了。在主从中,通常的操作是主库用来写入数据,从库用来读取数据。这样的好处是避免了所有的请求压力都打在了主库上,同时系统的伸缩性也得到了很大的提升。但是问题就来了,读从库时的数据要与主库保持一致,那就需要主库的数据在写入后同步到从库中。如何保持主库与从库的数据一致性,当有多个从库时,又如何做到呢?这是第一次同步时所发生的传递关系。看名字就知道,主库第一次就毫无保留的把所有数据都传递给了从库。我们先来看下它们是如何发生第一次关系的(就知道你会想歪)。当从节点与主节点第一次建立联系时,从节点会向主节点发送 psync 命令,表示要进行数据同步。正如你看到的 psync 命令后会带有两个参数:一个是 runID,一个是偏移量 offset。在图中第一次复制时因为不知道主库ID和偏移量,因此用“?”和“-1”分别来表示runID 和 offset。当主节点接收到 psync 命令后,会使用 FULLSYNC命令向从节点发送 runID 及offset 两个参数。从节点将其信息保存下来。RDB文件,这是一个老面孔了,持久化时会用到的二进制文件。在这里起着主从数据同步的作用,也就是说主从同步是依赖 RDB 文件来实现的。从节点接收到 RDB 文件后,在本地完成数据加载,算是完成了主从同步。我们回想下 RDB 文件是如何生成的。在持久化那篇文章里,我们介绍过,父进程 fork 了一个子进程来进行生成 RDB 文件。父进程并不阻塞接收处理客户端的命令。那么问题就产生了,当主节点把 RDB 文件发送给从节点时,主节点同时接收的命令又该如何来处理?这一步就是来解决 RDB 文件生成后,父进程又接收到写命令同步的问题的。为了保证主从节点数据的一致性,主节点中会使用缓冲区来记录 RDB 文件生成后接收到的写操作命令。在 RDB 文件发送完成后会把缓冲区的命令发送给从节点来执行。我们再来回顾下整个同步流程,从建立关系,生成 RDB 文件,传输给从节点到最后缓冲区命令发送给从节点。这是一个从节点与主节点同步的完整流程。那么我们再来思考:当有多个从节点,也就是一主多从时,第一次连接时都要进行全量复制。但是在生成 RDB 文件时,父进程 fork 子进程时可能会出现阻塞,同时在传输 RDB 文件时也会占用带宽,浪费资源。不知道你对文章开头的 主-从-从模式是否还有印象。通过对从节点再建立从节点。同步数据时从级联的从节点上进行同步,从而就减轻了主节点的压力。上面的流程我们已经知道了正常情况下主从节点的复制过程了,但是当网络中断导致主从连接失败等异常情况下,主从同步又是如何来进行的?在这里要提到一个增量复制的名词,与全量复制不同的是,它是根据主从节点的偏移量来进行数据同步的。还记得在全量复制里我们所提到过的缓冲区吗?就是用来存储生成 RDB 文件后的写命令的,这里我们称为缓冲区A。主从节点断开连接后,除了会将后续接收到的写命令写入缓冲区A的同时,还会写入到另一个缓冲区B里。在缓冲区B里,主从节点分别会维护一个偏移量 offset。刚开始时,主节点的写位置与从节点的读位置在同一起点,随着主节点的不断写入,偏移量也会逐渐增大。同样地,从节点复制完后偏移量也在不断增加。当网络断开连接时,从节点不再进行同步,此时主节点由于不断接收新的写操作的偏移量会大于从节点的偏移量。当连接恢复时,从节点向主节点发送带有偏移量的psync 命令,主节点根据偏移量来进行比较,只需将未同步写命令同步给从节点即可。从节点第一次进行连接时,主节点会生成 RDB 文件进行全量复制,同时将新写入的命令存储进缓冲区,发送给从节点,从而保证数据一致性;
对于 Redis 主从大家可能并不陌生,但是配置的话日常工作中并不会经常操作。在这里简单介绍下主从的相关配置。对于主-从-从的模式来说,配置也与上边的操作类似,在这里就不多赘述了。在主从中,通常的操作是主库用来写入数据,从库用来读取数据。这样的好处是避免了所有的请求压力都打在了主库上,同时系统的伸缩性也得到了很大的提升。但是问题就来了,读从库时的数据要与主库保持一致,那就需要主库的数据在写入后同步到从库中。如何保持主库与从库的数据一致性,当有多个从库时,又如何做到呢?这是第一次同步时所发生的传递关系。看名字就知道,主库第一次就毫无保留的把所有数据都传递给了从库。我们先来看下它们是如何发生第一次关系的(就知道你会想歪)。当从节点与主节点第一次建立联系时,从节点会向主节点发送 psync 命令,表示要进行数据同步。正如你看到的 psync 命令后会带有两个参数:一个是 runID,一个是偏移量 offset。在图中第一次复制时因为不知道主库ID和偏移量,因此用“?”和“-1”分别来表示runID 和 offset。当主节点接收到 psync 命令后,会使用 FULLSYNC命令向从节点发送 runID 及offset 两个参数。从节点将其信息保存下来。RDB文件,这是一个老面孔了,持久化时会用到的二进制文件。在这里起着主从数据同步的作用,也就是说主从同步是依赖 RDB 文件来实现的。从节点接收到 RDB 文件后,在本地完成数据加载,算是完成了主从同步。我们回想下 RDB 文件是如何生成的。在持久化那篇文章里,我们介绍过,父进程 fork 了一个子进程来进行生成 RDB 文件。父进程并不阻塞接收处理客户端的命令。那么问题就产生了,当主节点把 RDB 文件发送给从节点时,主节点同时接收的命令又该如何来处理?这一步就是来解决 RDB 文件生成后,父进程又接收到写命令同步的问题的。为了保证主从节点数据的一致性,主节点中会使用缓冲区来记录 RDB 文件生成后接收到的写操作命令。在 RDB 文件发送完成后会把缓冲区的命令发送给从节点来执行。我们再来回顾下整个同步流程,从建立关系,生成 RDB 文件,传输给从节点到最后缓冲区命令发送给从节点。这是一个从节点与主节点同步的完整流程。那么我们再来思考:当有多个从节点,也就是一主多从时,第一次连接时都要进行全量复制。但是在生成 RDB 文件时,父进程 fork 子进程时可能会出现阻塞,同时在传输 RDB 文件时也会占用带宽,浪费资源。不知道你对文章开头的 主-从-从模式是否还有印象。通过对从节点再建立从节点。同步数据时从级联的从节点上进行同步,从而就减轻了主节点的压力。上面的流程我们已经知道了正常情况下主从节点的复制过程了,但是当网络中断导致主从连接失败等异常情况下,主从同步又是如何来进行的?在这里要提到一个增量复制的名词,与全量复制不同的是,它是根据主从节点的偏移量来进行数据同步的。还记得在全量复制里我们所提到过的缓冲区吗?就是用来存储生成 RDB 文件后的写命令的,这里我们称为缓冲区A。主从节点断开连接后,除了会将后续接收到的写命令写入缓冲区A的同时,还会写入到另一个缓冲区B里。在缓冲区B里,主从节点分别会维护一个偏移量 offset。刚开始时,主节点的写位置与从节点的读位置在同一起点,随着主节点的不断写入,偏移量也会逐渐增大。同样地,从节点复制完后偏移量也在不断增加。当网络断开连接时,从节点不再进行同步,此时主节点由于不断接收新的写操作的偏移量会大于从节点的偏移量。当连接恢复时,从节点向主节点发送带有偏移量的psync 命令,主节点根据偏移量来进行比较,只需将未同步写命令同步给从节点即可。从节点第一次进行连接时,主节点会生成 RDB 文件进行全量复制,同时将新写入的命令存储进缓冲区,发送给从节点,从而保证数据一致性;
为了减少数据同步给主节点带来的压力,可以通过从节点级联的方式进行同步。网络断连重新连接后,主从节点通过分别维护的偏移量来同步写命令。CSDN公众号全新搜索技能上线啦!
只要在公众号后台回复消息
就能自动回复想搜索的内容啦!
简直是程序员必备的搜索神器!
猜猜回复“Mysql安装”会出现什么
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/



















 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




