作者:李旭
本文对全美电视广告流量预测的算法与业务经验进行总结。企业中的人工智能算法工程师通常在解决任务前会根据自己的业务“常识”,给予模型一定的假设与先验知识,并选取“常规”解法进行细微调整。然而这样的“常识”一定是准确的吗?我们在对全美电视广告流量预测的项目中发现了诸多有违“常识”的业务特征,同样也采取了有违“常识”的做法。康卡斯特(Comcast)是全美第一大有线电视服务商,旗下的FreeWheel负责高端视频广告的投放。在Viewership Prediction项目中我们的任务是:预测全美各个地区(康卡斯特内部分区)各个电视频道在未来某一小时内可能给出的广告曝光(impression)。这一预测数据将会根据需求在各个维度(时间,地区,频道,用户分类)上进行聚合,用以给广告主提供参考,为广告投递提供决策支持。我们在模型设计与实现上采取了比较不同以往的做法,同时在业务上也发现了有违常识的数据特点。在此对全美电视广告流量预测的算法与业务经验进行总结。我们根据业务要求,进行了整体的模型设计。需求端给出超长时间序列预测的需求,这使得我们在对模型整体结构设计时进行了一些变动。同时在引入统计信息特征时是采用了更高灵活性的方法。我们选取wide&deep为模型原型,并在此基础上根据业务需求与特点进行了相应改进。在这个预测任务中,我们遇到的一大“非凡”挑战是超长的预测长度:需求端要求预测某地区某频道未来三个月每小时的流量,这也就是未来2208个时间步的预测结果。如果使用经典的Seq2Seq模型,那么误差累积效应将导致较远的预测结果会完全失去参考价值。在这一问题上我们采取了direct multi-horizon + element-wise loss的解决方案:1) direct multi-horizon是指根据现有特征与历史序列,直接对未来多个时间步(horizon)进行预测,预测时刻t+1的预测结果yt+1不再作为预测时刻t+2的输入,模型直接捕捉历史序列对未来各个时间步上变量的模式,而不是只预测未来的第一个时间步的结果。因此模型的输出将是一个长度超过2000的向量,而不是2000个标量预测值(实际上当前需求已经调整到未来180天,即4320的输出向量,模型效果损失在可接受范围内。据我们所知这也是业界内前所未有的长度)Taieb and Atiya, 2016 与MQ-R(C)NN等论文已经证明direct multi-horizon具备一定优势;2)?在反向传播计算损失的时候,损失函数将在所有时间步上进行平均并在所有element position上进行传播。在超过2000个向量元素上的损失的平均会带来了极大误差,这会严重影响了模型参数的更新。在此我们使用了自定义的损失函数,保留输出向量上每个element position上的loss值,以向量形式将loss返回给tensorflow的gradients模块,这使得每个小时反向传播路径上的参数都根据自身的损失来计算梯度进行更新,而非一个基于2000个预测值上的平均损失。例如在TensorFlow源码中,对MSE(Mean Square Error)均方差的定义如下:def mean_squared_error(y_true, y_pred): y_pred = ops.convert_to_tensor_v2(y_pred) y_true = math_ops.cast(y_true, y_pred.dtype) return K.mean(math_ops.squared_difference(y_pred, y_true), axis=-1)
可见当y_pred与y_true的维度大于2时,K.mean函数会在整个高维矩阵上计算平均,最后返回标量值(scalar)给gradient模块,作为所有element position上的共同损失来进行反向传播。而改写的eleMSE损失函数:# custom loss function, Element-wise MSEdef ele_ mean_squared_error (y_true, y_pred):y_pred = ops.convert_to_tensor(y_pred)y_true = math_ops.cast(y_true, y_pred.dtype)return K.mean(math_ops.squared_difference(y_pred, y_true), axis=0)
将只对axis=0维度上面进行mean reduce操作,最后将损失以张量形式(vector)返回给gradient模块进行进一步参数更新,损失张量的长度将与时间步一致。实际结果通过A/B Test表明我们在多个聚合维度的MAPE (Mean Absolute Percentage Error)平均绝对误差百分比上最高提升了9%。同时通过进一步研读Tensorflow源码,我们确定了编码的功能与用法正确性。除此之外,值得一提的是,除了超长时间步预测本身会给模型带来的预测精度的挑战,另外一个不可避免的问题是它会导致训练样本与用于推理的样本之间存在一个multi-horizon长度的时间间隔。直观来说,我们的训练数据的特征会是三个月以前的分布,而当前测试数据集的特征分布则是基于现在的样本分布情况。当面临诸如当下疫情造成的影响,人们看电视的习惯由于work from home、裁员失业或者低收入地区大量退订电视服务等社会因素的影响,样本的分布会出现短期突然的改变,在这种情况下处理超长时间步长的模型几乎不能迅速做出反应,模型需要经过一个multi-horizon的时间间隔后才能获取到新样本的数据并拟合其分布。这也是超长时间步长应用场景极少出现的另一个原因。考虑到四周中位数在我们的“前机器学习”时代中的稳定性与普遍应用,我们尝试将四周中位数这一统计信息引入到模型中来进行模型融合。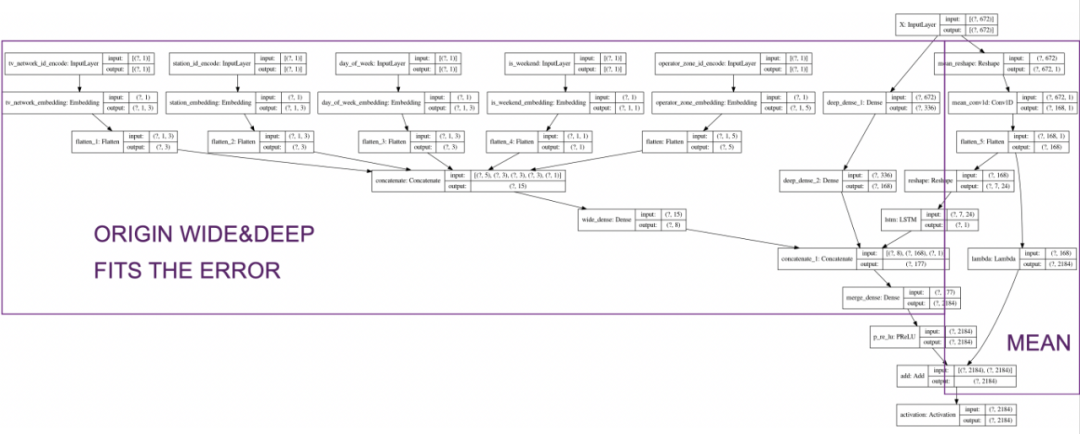
如图是Keras输出的模型结构图,数据从上部输入,每个方块代表一个神经网络层,按箭头方向前向传播,最底层为输出。我们在模型最右侧的path引入了四周中位数这一特征,直接shortcut到最后一层进行模型融合。如此一来带来的好处是,原本的wide&deep模型将仅用来拟合ground truth与四周中位数的残差,预测目标的值域范围大大减小,这非常有利于模型的收敛与预测精度。与此同时,四周中位数的引入直接带来的一大好处是对于“规律零流量”给予了很完美的预测结果。在电视领域经常有电视台在夜间routined关闭电视信号或进行设备调修,在此期间没有广告机会与广告投递,因此在广告曝光序列上会形成稳定周期性的零流量,相比正常流量形成谷底。在仅使用wide&deep模型时,零流量作为负样本look back= 4周的情况下只会出现4次,样本数量不足,模型甚至可能将其视为异常值而泛化掉,通常不能对零流量的出现规律进行良好的捕捉,对零流量时刻的预测结果通常会与常规时间的流量在同一数量级上。而当引入了四周中位数,它会给wide&deep提供一个预测base,而通常在这个base=0的基础上加上残差,预测结果不会偏离太远,规律零流量获得了很好的捕捉。上图是早期仅基于wide&deep的一版模型,可以看到每天的规律零流量几乎都没有预测到,虽然能预测到谷底但是预测出零流量显然比较困难。而下图是现在的模型引入四周中位数后非常明显的效果,曲线中的零流量低谷位置预测值与真实值有非常良好的重合。由此可见,业务层面有价值的直观的统计信息往往能帮助模型对某一特定特征大幅提高捕捉与建模能力。另外,我们发现在线上应用中均值相比中位数能够提供更好的稳定性,受异常值影响较小,因此最后的模型中实际采用的是四周均值。

通常的统计特征都是在数据准备阶段生成,而本项目为了进行快速实验,模型的四周中位数采用固定参数的空洞卷积直接在模型中生成,在效率上没有观察到明显的损失。将统计特征的生成从data preparing pipeline剥离并后延融合至模型内部并不是常见做法,但在效率没有明显损失的前提下,这可以为特征工程与实验提供较高的灵活性。除了应用机器学习基本技术对算法进行设计与优化,在开发过程中,我们通过不断观察数据也对其分布特点有逐渐加深的了解。实验上最优的配置一定是最合理的配置吗?大事件/体育赛事的发生一定会对电视流量产生促进作用吗?这些我们都将在本节给予分析。我们在上一节进行了模型融合后,wide&deep输出的最后一层使用的激活函数是ReLU,ReLU过滤掉了所有小于0的输出,这直接导致的结果是我们的预测值是永远大于等于前四周的中位数的。虽然我们的业务在长期来看是随着时间发展而增长的趋势,但是从周期性或季节性上来看这种特点并不一定。我们尝试了Linear(不使用非线性激活函数)、LeakyReLU和PReLU三种不同的激活函数,实验结果也比较令人意外,ReLU取得了最好的效果,并且随着激活函数第三象限曲线斜率的增大效果逐渐变差。后来通过从业务上检查数据我们发现,全网流量在一年中有规律性的增减趋势,这可能与人们的看电视习惯/冬夏令时/寒暑假/节假日有关系。而项目开发阶段正值9月和10月,因此我们看到相对于9月的四周中位数,10月明显是上升的趋势,所以使用ReLU可以较好的获得预测结果,但也可以想像相较于8月预测9月的情况,我们可能需要Leaky的特性。因此最终我们选择使用PReLU来使模型自行学习Leaky程度,而没有依照常识选择在实验数据集上表现最优的激活函数设置。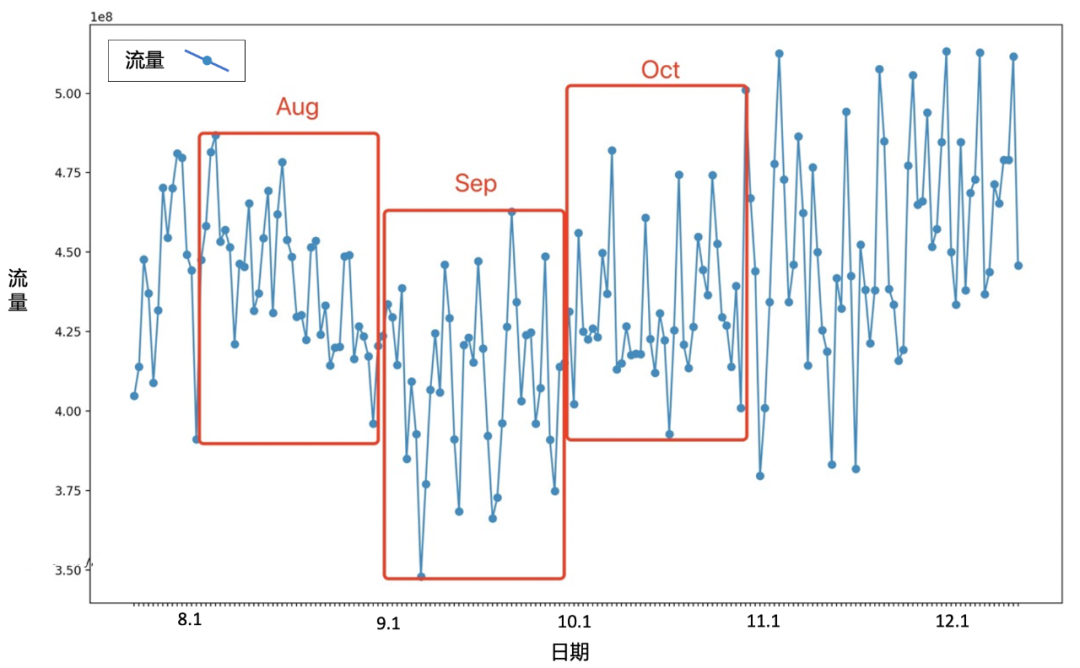
电视广告业的一个先验常识是,大型节假日(如圣诞节、感恩节)和大事件(大型体育赛事如超级碗、美国大选等)会比较明显的影响人们看电视的pattern,提升当天/时间段的全网流量。然而从数据分析的结果来看,大事件本身实际上对流量的影响非常有限。并非所有节日都会对电视流量造成影响,严格来说我们只看到了圣诞节前后流量确实发生了明显变化(如图左),而且并非都是预想的促进作用,流量可能由于人们外出活动(集会/游行/购物)而出现低谷,同时电视台在特殊节日播放的特别节目也会临时改变人们的观看习惯。某些频道也只对某些特定的节日或体育赛事敏感(如图右)。从另一个角度来看,“并非所有电视台的流量都获得提升”这一结论也是合理的,当某个台播放特别节目而吸引更多观众时,必然会有其他电视台流量的流失。大年三十的“春晚”会带来cctv1的收视率峰值,然而也不可避免的造成其他电视台的收视率下跌。尽管这部分流量提升也可能来自不活跃观众,但事实上“几乎不看电视”的不活跃观众的行为基本上非常稳定,活跃用户与不活跃用户两个集合之间没有频繁的人员变动。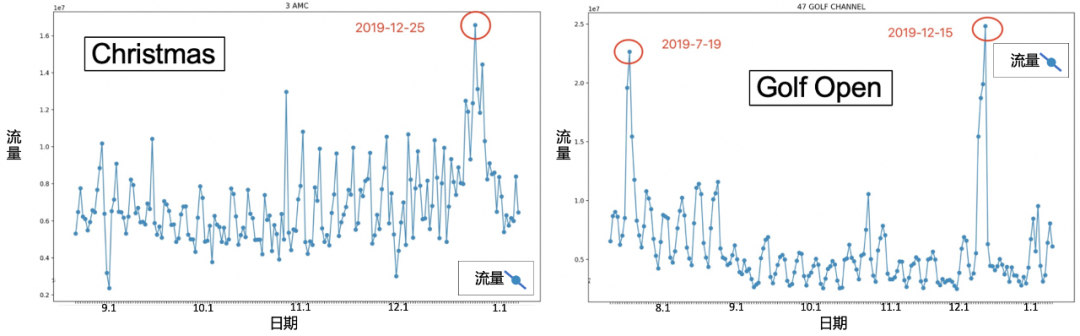
除了超长的预测multi-horizon,在我们的项目中算法面临的另一个困难是特征的匮乏。我们要预测地区频道小时这一粒度上的流量,而由于各种因素我们所拥有的特征只有相关id,时间信息(小时,weekday)以及历史流量,这就像我们在推荐场景下,没有商品信息,没有用户画像,只有用户与商品的id及其历史交互的显示反馈,这在当今的推荐场景下是难以想象的。在这种情况下,我们决定自行生成关于频道的特征向量。每个地区内部都有大量的household观看历史,所以我们将household与电视频道的观看记录生成交互矩阵,采用协同过滤的方式,进行基于SVD的MF(矩阵分解),使用交替最小平方法ALS在spark上进行求解,获得关于频道的稠密特征向量。不过遗憾的是,我们尝试了不同长度与不同迭代轮次的特征向量,对最终模型效果的提升都非常有限,考虑到整个系统pipeline的复杂度与时间成本,最终没有上线。不过我们仍然认为打破常规进行跨场景的技术迁移应用这样的解题思路是很有意义的,是一次有益的尝试。同样也希望在今后面临特征匮乏的相似任务上能够有所借鉴,希望在其他任务中起到作用。除了以上,我们的模型还有很多可以进行改进与进一步探索的地方。比如在模型选型之初没有进行太多的模型设计,简单地选择了wide&deep,用wide来捕捉静态特征,用deep部分捕捉时序特征,没有进行特征交叉。除此之外当数据收集整理后还可以进行特征的扩充,包括频道(title),类型(tag)与描述信息(description),然后通过NLP的相关方法做进一步处理,相对地还有与地区相关的census信息包括地区人口,平均收入,受教育程度,地区产业行业等。从业务角度也仍然有更多的东西值得挖掘,比如我们会想当然地认为周六日与工作日人们的电视观看模式有所不同,然而实际上,周日晚的流量与工作日晚上的更相近,周五晚上的电视收看模式与周末晚上更相近,在weekday viewership pattern问题上存在一个分布偏移,并且与周末电视流量会升高这一预想并不一致的是,人们在周末可能会外出或聚餐,在许多频道上的流量并不会有预想的提升,甚至可能相比工作日有所下降。由此可见,许多基于“常识”的预期和假设都需要数据进行进一步验证才能获得更准确严谨的结论,这也正是数据科学的使命与价值。最终,模型效果如下表,我们最终的metrics的评估是在各个维度上聚合的结果,可以看到除了最终Model4的效果除了好于fallback的四周中位数结果外,在各种优化过程中模型的效果也在不断提升,一部分来自于深度学习本身的技术,另一部分则来自于对业务不断深入的理解。 | | | |
| | | |
| | | |
| Model1 (element-wise loss) | | | |
| | | |
| | | |
| | | |
“常识”并不总是适用的。全美电视广告流量预测从需求、模型设计、参数设置方式、业务发现和探索过程中“不走寻常路”,避开了许多“常识”陷阱。很多时候业务“常识”会带给算法工程师有偏差的先入为主的观念,这一点尤其是有经验的算法工程师需要注意的,数据科学还是应该回归到数据本身,去挖掘具体问题的数据分布与业务背景,用数据说话。很有可能大幅提升模型效果的“金钥匙”就蕴含在这些有违“常识”的独特业务特点里。
作者简介:李旭,本科就读于北航,研究生毕业于清华大学软件工程专业,工学硕士学位,现就职于FreeWheel北京研发中心机器学习团队任算法工程师。读研期间论文及主要工作涉及基于深度学习的表征学习与推荐系统可解释性方向,目前在FreeWheel进行广告库存预测与实时竞价场景下的价格推荐等项目。转自:?数据派THU 公众号;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




