作者:Pulkit Sharma ?翻译:陈超 ?校对:吴振东本文从对比无监督学习和监督学习的特征切入,结合具体的案例来给大家介绍层级聚类的概念、应用场景、主要类型以及Python实现。理解顾客行为在任何工业领域都是至关重要的,直到去年我才意识到这个问题。当时我的CMO(chief marketing officer,首席营销官)问我:“你能告诉我,我们新产品的目标用户应该是什么群体呢?”这对我来说是一个学习的过程。我很快意识到,作为一个数据科学家,将顾客细分以便于公司能够进行客户定制并建立目标策略有多重要。这就聚类概念能派上用场的地方!用户分类通常很棘手,因为我们脑海当中并没有任何目标变量。我们现在正式踏入了无监督学习的领域,在没有任何设定结果的情况下来发掘模式和结构。这对数据科学家来说是充满挑战但却是让人激动的事。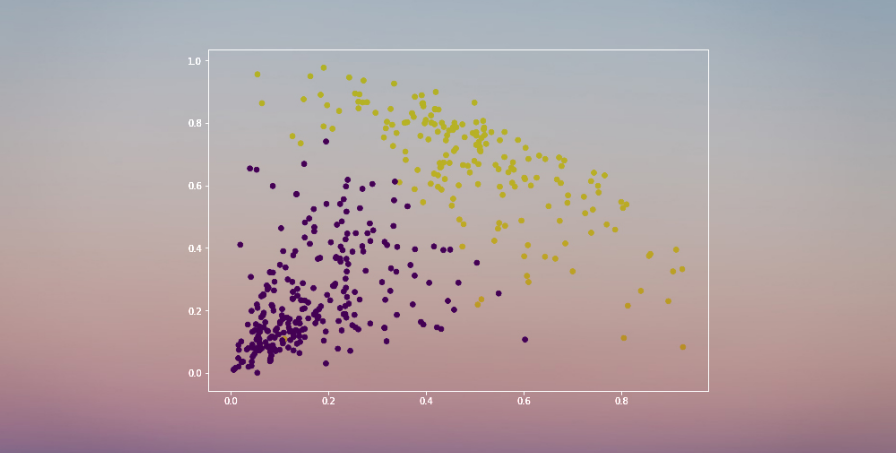
在这里有几种不同的聚类方法(你会在下面的部分看到)。我将向你介绍其中一种——层级聚类。
我们将会学习层级聚类是什么,它优于其他聚类算法的地方,不同层级聚类的方式以及开展的步骤。我们在最后会采用一个顾客分类数据库并实现Python的层级聚类。我喜欢这个方法并且十分确定在你读完本文之后也会喜欢上的!注释:如上所述,聚类的方法很多。我鼓励你查看我们对不同类型聚类所做的指南:https://www.analyticsvidhya.com/blog/2016/11/an-introduction-to-clustering-and-different-methods-of-clustering/utm_source=blog&utm_medium=beginners-guide-hierarchical-clustering
想要学习更多关于聚类的内容和其他机器学习算法(监督和无监督)可以看看下面这个项目-
https://courses.analyticsvidhya.com/bundles/certified-ai-ml-blackbelt-plus?utm_source=blog&utm_medium=beginners-guide-hierarchical-clustering(1)?聚合式(Agglomerative)层级聚类在我们深入学习层级聚类之前,理解监督学习和无监督学习之间的差异是十分重要的。让我用一个简单的例子来解释这种差异。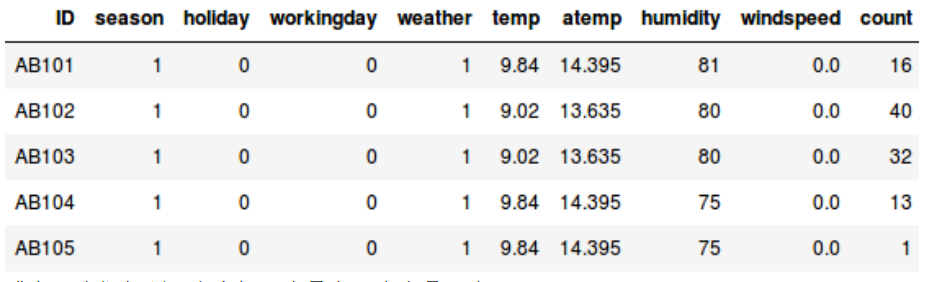
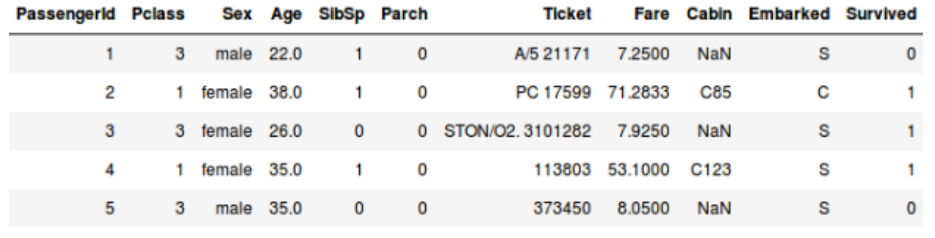
所以说,当我们有目标变量的时候(在上述两个例子当中的数量和生还),基于一系列预测变量或者自变量(季节,假期,性别,年龄等)来预测,这种问题叫做监督学习问题。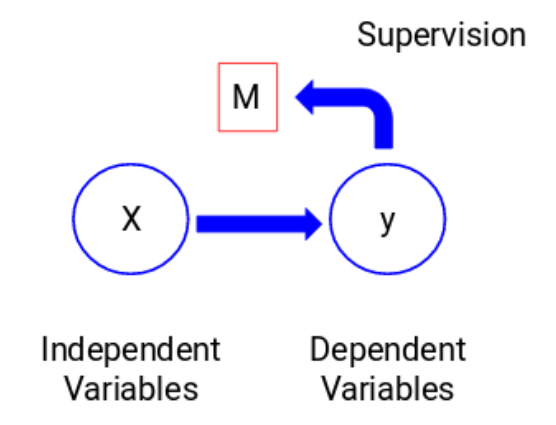
在这里,y是因变量或者叫目标变量,X代表自变量。目标变量依赖于X,因此它也被叫做一个因变量。我们在目标变量的监督下使用自变量来训练模型,因而叫做监督学习。我们在训练模型时的目标是生成一个函数,能够将自变量映射到期望目标。一旦模型训练完成,我们可以把新的观测值放进去,模型就可以自己来预测目标。总而言之,这个过程就叫做监督学习。有时候我们并没有任何需要预测的目标变量。这种问题没有任何外显的目标变量,被叫做无监督学习。我们仅有自变量。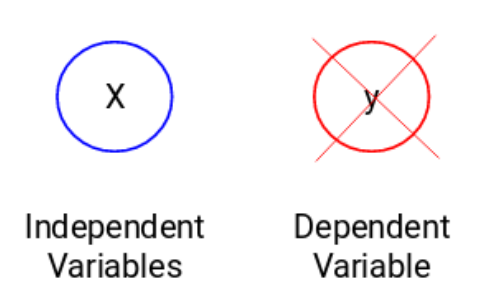
我们试图将全部数据划分成一系列的组。这些组被叫做簇,这个过程叫做聚类。
这种技术通常被用于将总体聚类成不同的组别。常见的例子包括顾客分群、聚类相似的文件、推荐相似的歌或者电影等等。现在有很多算法可以帮助我们完成聚类。最常用的聚类算法是K-means和层级聚类。在此之前,我们需要先知道K-means是怎样工作的。相信我,这会让层级聚类的概念变得更简单。这是一个迭代的过程。它将持续地运行,直到新形成的簇的中心点不再变化,或者到达了最大迭代次数。但是K-means也受到了一些质疑。它通常试图生成规格相同的簇。还有,我们需要在算法开始之前就决定好簇的数量。理想情况下,我们在算法开始时不知道要多少簇,因而这也是K-means所面对的一种质疑。这也恰恰就是层级聚类的优越之处。它解决了预先设定簇的数量的问题。听起来就是在做梦!所以,让我们看看层级聚类是什么以及它是怎样改进K-means的。

现在,基于这些簇的相似性,我们可以把最相似的簇放到一起,并且重复这个过程直到剩余单一的簇: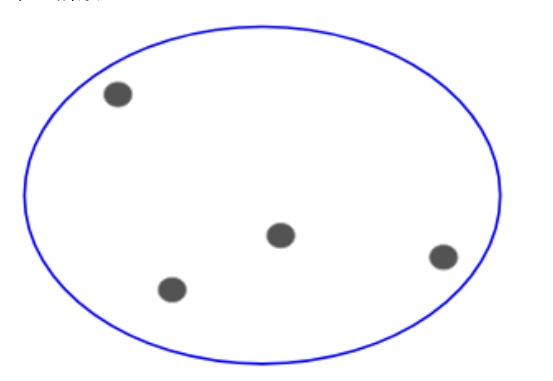
我们有必要建立一个簇的层级,这就是为什么这个算法叫做层级聚类。我们将在下一部分讨论如何决定簇的数量。现在,让我们看看不同类型的层级聚类。把每个点归于单独的一个簇。假设这里有四个数据点。我们把每个点分到一个簇里,在开始时就会有四个簇:
然后,在每一轮迭代中,我们把最相似的点对进行融合,然后重复上述步骤直到只剩单一簇: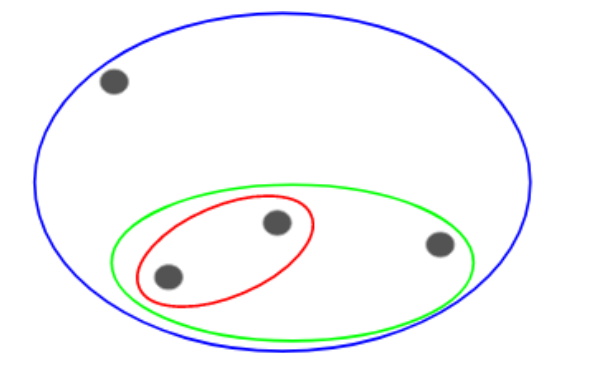
每一步我们都在融合(或者增加)簇,对吧?因此,这种聚类也叫作累加层级聚类。分裂式层级聚类则是一种相反的思路。与一开始划分n个簇(n个观测值)不同,我们开始时只有一个簇,并且把所有的点都纳入这个簇。所以,我们有10个或者1000个点并不重要。所有的点在一开始都在同一个簇中: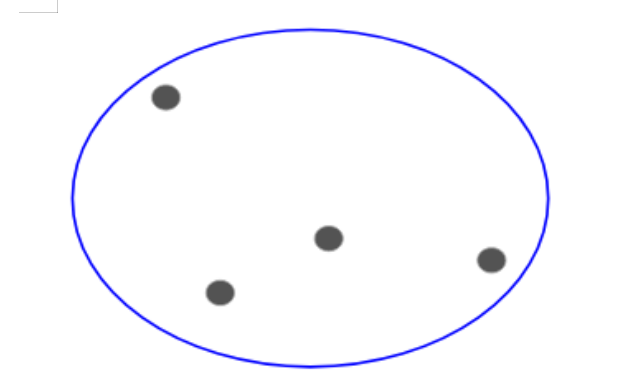
现在,在每一次迭代中,我们把簇中最远的点分离出来,并且重复上述过程直到每个簇都只有一个点:
我们每一步都在分裂(或划分)簇,因此叫做分裂式层级聚类。聚合式聚类被广泛应用于工业当中,在本文当中也将重点关注。一旦我们掌握了聚合式,分裂式层级聚类也将变得非常简单。我们在层级聚类当中把最相似的点或类进行融合——我们已经知道这一点。现在问题是——如何决定哪些点相似哪些点不相似呢?这才是聚类当中最重要的问题之一!这里有一种计算相似性的方式——计算簇中心点之间的距离。距离最近的点被认为是相似的点,我们可以融合它们。我们可以把这个叫做基于距离的算法(因为我们计算了簇之间的距离)。在层级聚类中有一个临近矩阵(proximity matrix)的概念。这个矩阵存储了每对点之间的距离。让我们来用一个例子来理解这个矩阵和层级聚类的方法。
假设一个老师想把她的学生分成不同的组。她有每个学生在一次作业当中所取得的分数,基于这些分数,她想把学生分成不同的组。这里没有关于分组的固定的目标。因为老师并不知道哪种学生应该分配到什么组,它不能用监督学习问题来描述。所以,我们将使用层级聚类把学生分成不同的组。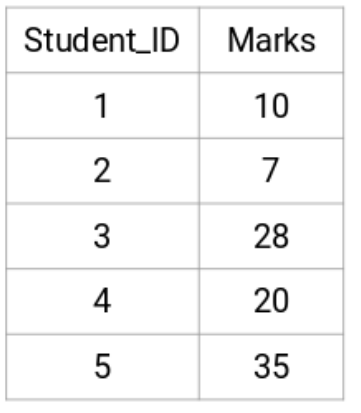
首先,我们创造一个邻接矩阵,这个矩阵会告诉我们这些点之间的距离。我们计算了每两个点之间的距离,会得到一个n*n的方形矩阵(n是观测值的数量)。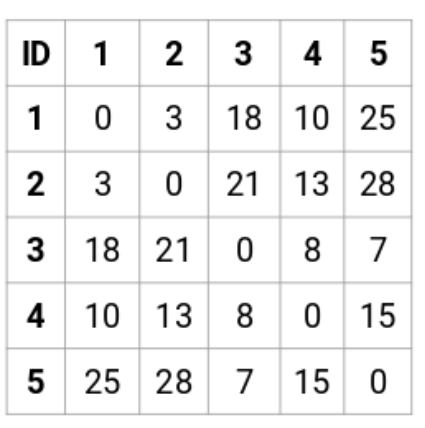
这个矩阵的对角线永远是0,因为每个点到自己的距离总是0。我们将使用欧氏距离公式来计算剩下的距离。所以,让我们来看看我们想计算的点1和2之间的距离:类似地,我们可以计算所有点之间的距离,并且填充这个邻接矩阵。
不同颜色表征不同的簇。你可以看到数据中的5个点构成了五种不同的簇。第二步:接下来,在邻接矩阵中找到距离最短的点,并且把这些点融合。然后更新邻接矩阵。
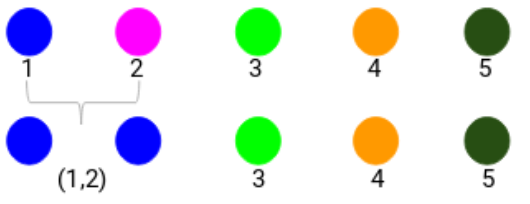
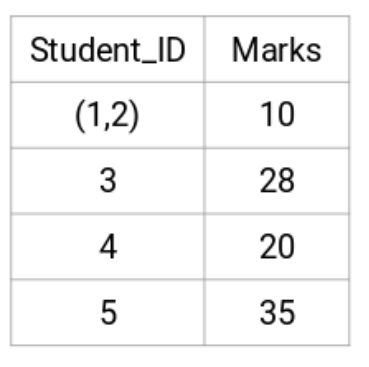
在这里,我们取了两个点(7,10)中的最大值来代替这个集群的标记。我们也可以用最小值或者平均值代替。现在,我们将再一次计算这些簇的邻接矩阵: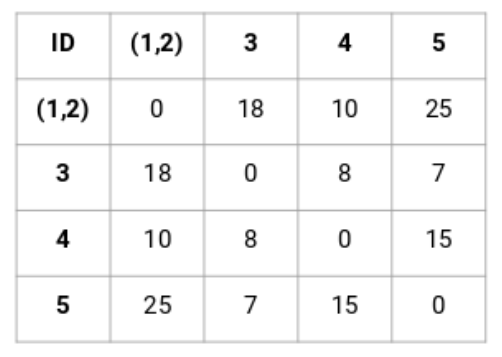
我们先看邻接矩阵当中的最小值,然后融合簇中最接近的一对。我们在重复上述步骤之后将得到以下融合的簇:
我们开始有5个簇,最后只有一个单一的簇。这也就是聚合式层级聚类的工作方式。但是棘手的问题仍然存在——怎么决定簇的数量呢?让我们看看下一部分。准备好回答这个从开始就一直在提的问题了吗?为了获得层级聚类的数量,我们使用了一个叫树状图的绝妙概念。让我们回到老师-学生的例子。无论何时融合两个类,一个树状图都会记录这些类之间的距离并且以图的形式进行表征。让我们看看树状图是什么样的:
我们把样本放到x轴,距离作为y轴。无论两个簇何时融合,我们都将加入树状图内,连接点之间的高度就是这些点之间的距离。让我们来建立例子的树状图:
需要花点儿时间来加工上述图片。我们开始融合了样本1和2,这两个点之间的距离是3(指的是在上一部分出现的第一个邻接矩阵)。让我们来把它放到树状图上: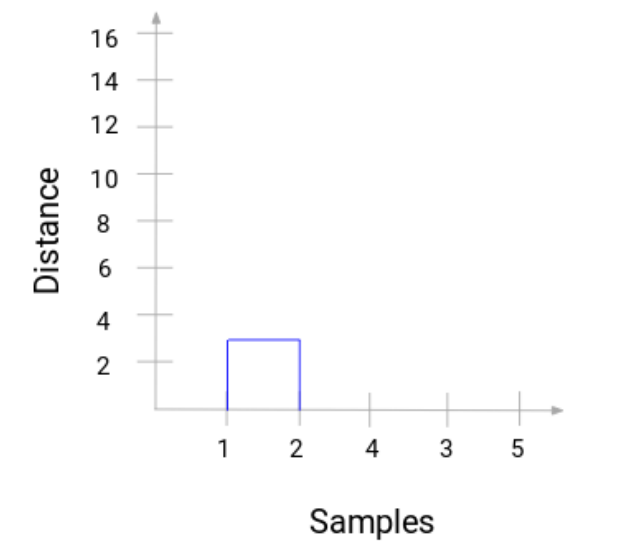
在这里,我们可以看看融合的样本1和2。垂直的线代表两个点之间的距离。相似的,我们把融合簇的所有步骤画到图上,最后可以得到如下树状图: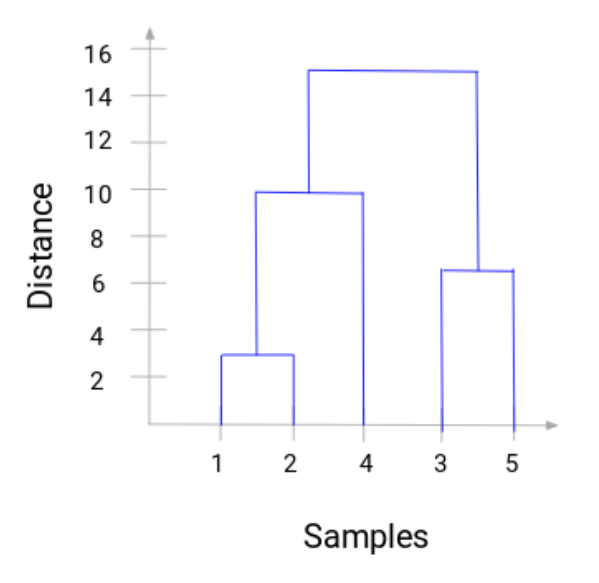
我们可以清晰地把层级聚类的步骤进行可视化。垂直线的距离越长,簇之间的距离越远。现在,我们可以设置一个距离阈限,并画一条水平线(一般的,我们会用这种方式来设置阈限,它会切断最常的垂直线)。让我们设置阈限为12,然后画一条水平线。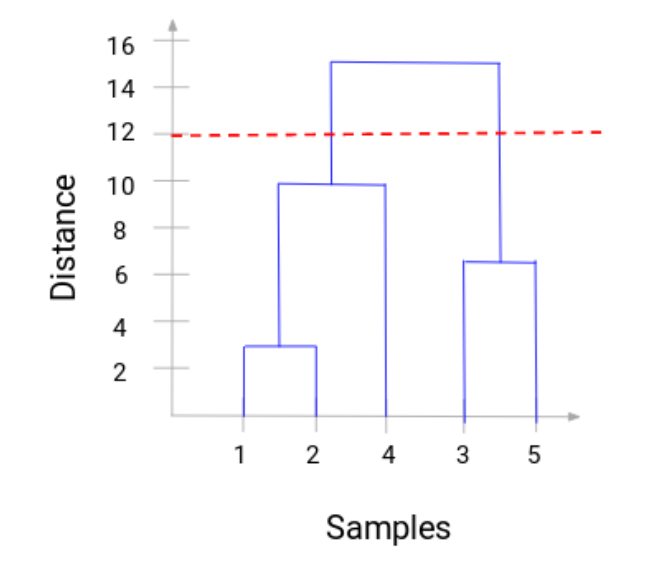
类的数量是与阈值先相交的垂直线的数量。在上述例子里,因为红线与两条垂直线交叉,我们将有2个类。一个类包括样本(1,2,4),另一个类包括样本(3,5)。非常清晰对吗?这就是我们在层级聚类中使用树状图确定类的数量的方式。在下一部分,我们将实际应用层级聚类帮助你理解本文中所学到的概念。我们将开始解决一个批发顾客分类问题。你可以在这里下载数据集(https://archive.ics.uci.edu/ml/machine-learning-databases/00292/Wholesale%20customers%20data.csv)。
这个数据托管在UCI机器学习知识库当中。本问题的目标是对一个批发商的顾客基于他们在不同产品类型(例如牛奶、食品杂货、地区等等)的年度开支进行分类。让我们先来探索一下数据,然后再利用层级聚类进行顾客分类。
view rawimporting_libraries.py?hosted with??by?GitHubhttps://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100034460&isMul=1&isSend=0&token=886063492&lang=zh_CN#file-importing_libraries-py
https://gist.github.com/PulkitS01/8ac9bf3b54eb59b4e1d4eaa21d3d774e/raw/6cea281dc4dea42bbcb2160e6cef1535cad765e7/reading_data.py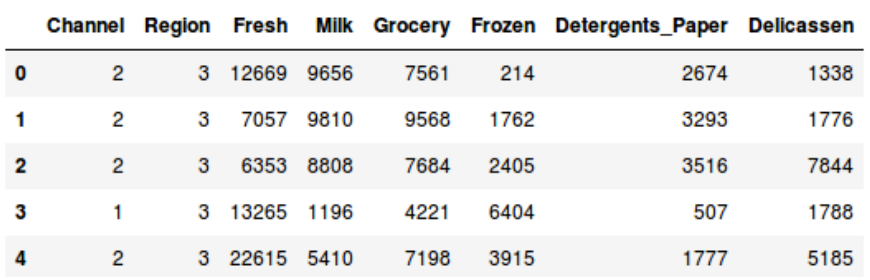
这里有很多产品种类——生鲜、牛奶、杂货等等。数值代表被每个顾客所购买的数量。我们的目标是从这个数据中进行类的划分,可以把相似的顾客划归到同一类。我们将使用层级聚类解决这个问题。但是在实际应用层级聚类解之前,我们需要把数据集进行归一化以便于所有变量的尺度是相同的。为什么这一步很重要呢?因为如果变量尺度不同,模型偏向那些拥有更大量级的变量像是生鲜或者牛奶(如上表格)。

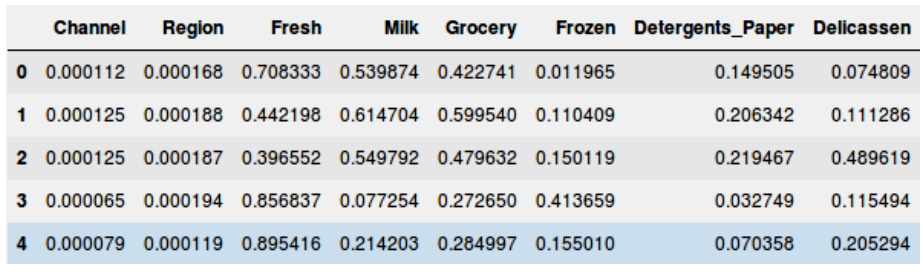
在这里,可以看到所有变量的尺度几乎是相似的。现在,我们可以开始进行层级聚类了。首先画出树状图来帮助我们决定这个问题当中簇的数量:
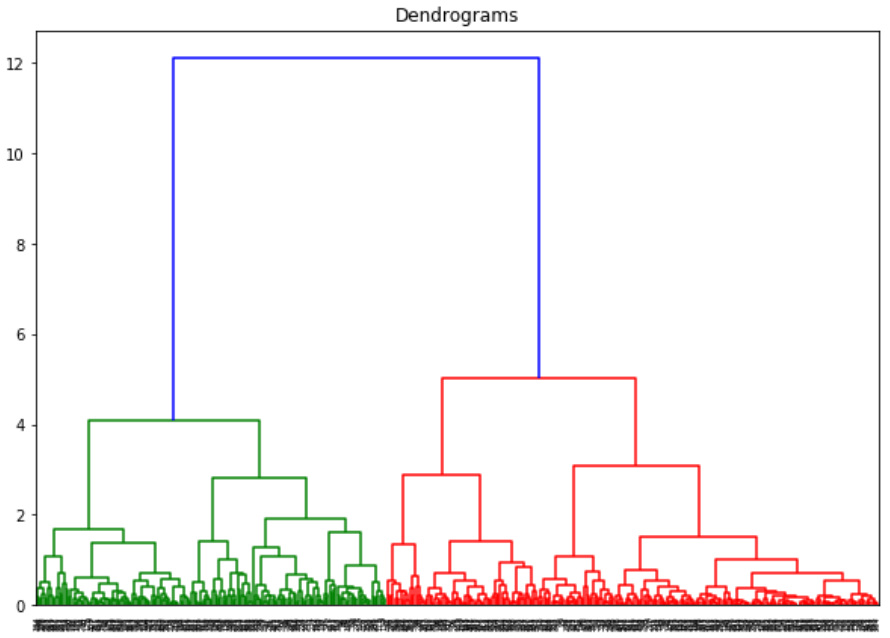
X轴为样本,y轴表征样本之间的距离。距离最大的垂直的线是蓝色的线,因此我们可以决定阈值为6,然后切断树状图:
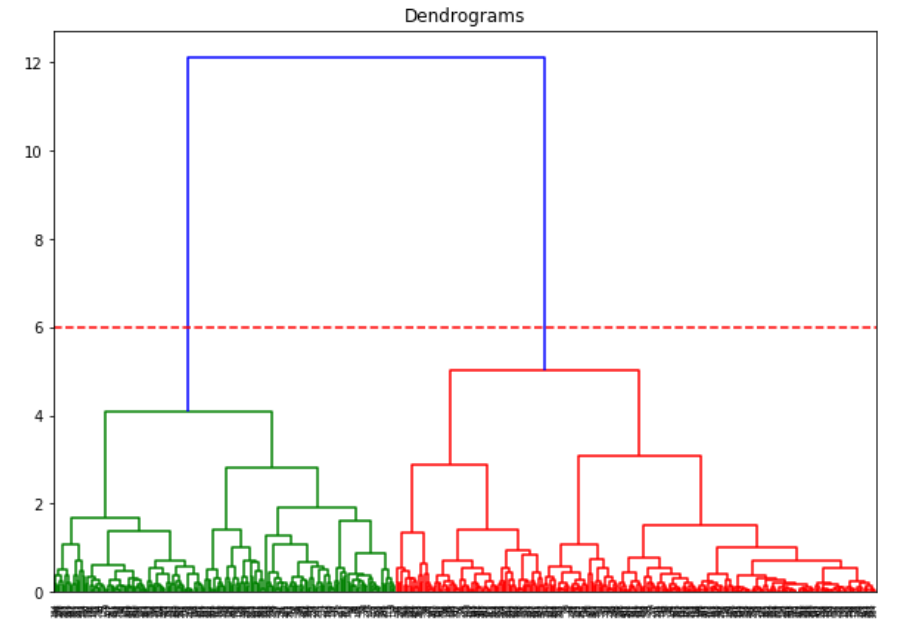
这条线有两个交点,因此我们有两个簇。让我们使用层级聚类:


在我们定义2个簇之后,我们可以看到输出结果中0?和1的值。0代表属于第一个簇的值,而1代表属于第二个簇的值。现在将两个簇进行可视化:
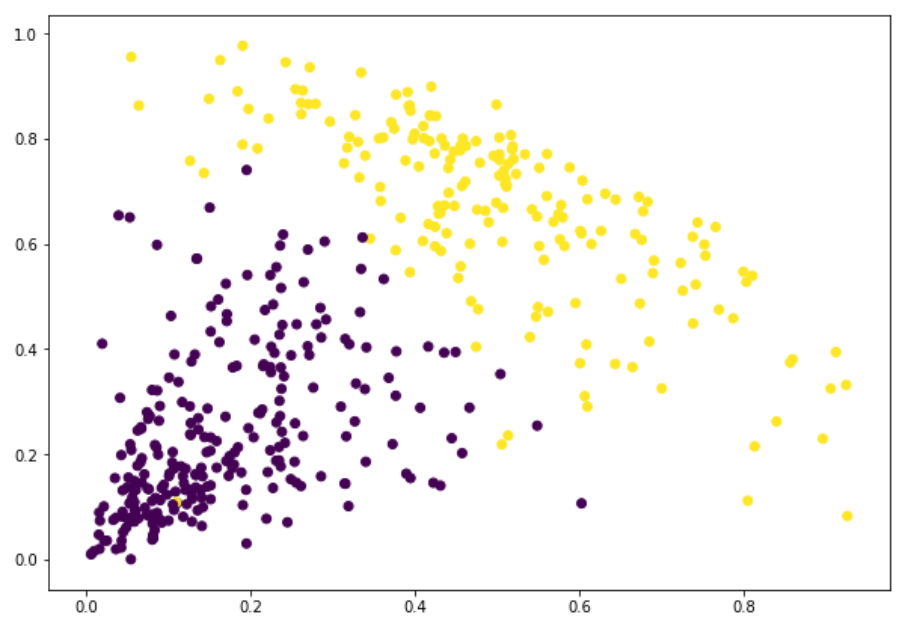
太棒了!我们现在可以清晰地看到两个簇。这是我们用Python来实现层级聚类的过程。层级聚类是一种非常有用的划分观察值的方法。优势在于无需预定义集群数量,这使它比k-Means更具优势。如果你对数据科学还比较陌生,强烈建议你学习实用机器学习课程(https://courses.analyticsvidhya.com/courses/applied-machine-learning-beginner-to-professional?utm_source=blog&utm_medium=beginners-guide-hierarchical-clustering)。这是你可以在任何地方找到的最全面的端到端的机器学习课程之一。层级聚类只是课程中涵盖的众多主题之一。A Beginner’s Guide to Hierarchical Clustering and how to Perform it in Pythonhttps://www.analyticsvidhya.com/blog/2019/05/beginners-guide-hierarchical-clustering/译者简介:陈超,北京大学应用心理硕士在读。本科曾混迹于计算机专业,后又在心理学的道路上不懈求索。越来越发现数据分析和编程已然成为了两门必修的生存技能,因此在日常生活中尽一切努力更好地去接触和了解相关知识,但前路漫漫,我仍在路上。
转自:?数据派THU 公众号;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




