作者:Kabalan Gaspard ?翻译:王紫岳 ??校对:陈汉青本文约4000字,建议阅读10+分钟。
本文为大家介绍了作者使用不同的算法来解决Free Flow谜题游戏的心路历程,从一开始的A*,Q-learning,到最后的卷积神经网络,作者详细的介绍了在使用这些算法时遇到的困难和得到的启示。
深度学习比古老的蛮力技术更适合解决FlowFree问题吗?我们都有过这种经历。你拿着手机发呆,想要消磨一些时间,于是你决定放弃自己优秀的思考,打开应用商店的游戏区,看看游戏排行榜。你找到了一个看起来很有趣的谜题游戏,但其实游戏是否有趣并不重要,因为你只想玩半个小时,然后就删掉、忘记它,对么?2个月以后,我完成了两千多关的Flow Free①游戏,并且坚持每一关都得到“完美”评分。这一游戏(自2012年发行以来,这款游戏在iOS和Android平台上都是最受欢迎的游戏之一)的设定相当简单:将不同颜色的阀门分别连起来,并且不能有线相交。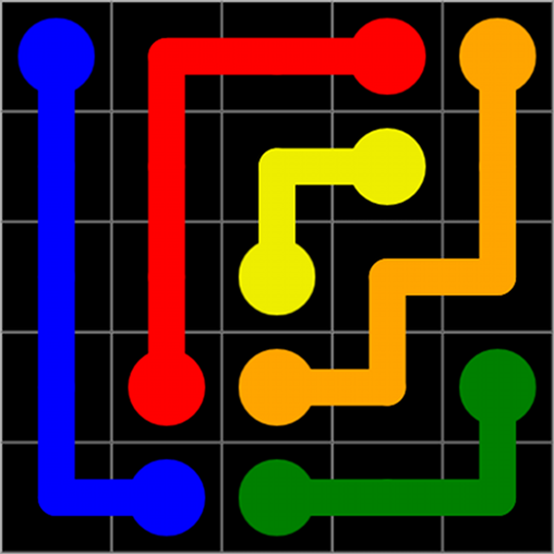
截图中的关卡可能看起来很简单,但是它的难度确实在不断提升。随着关卡的进行,我发现我自己想出了一些可以帮助我更快完成这些高级关卡的策略(例如:尽可能的保留外层边界空白,避免在未填满的方形中创建“港湾”等)。浏览网上论坛时,我看到其他的玩家都有他们自己的技巧,有的和我的一样,有的则略微不同。这就引出了问题——计算机能否通过“经验”,而非蛮力,来学习这些技术?
从基础开始:A*?
如今的深度学习问题大部分可以归结为要使用哪种算法。我以A*搜索作为开始。尽管它本身不是深度学习,但是它也很好的说明了这个问题内部的复杂性,并且也给了我们一些机会,来使用更高级的、能够自我驱动的启发式算法。由于空间的复杂性太大,以至于我无法一次性解决问题。所以我开始按颜色递归地解决问题(如果给定路径被“堵塞”,就回溯到上一种颜色)。在启发式算法中,我使用了较为可信的曼哈顿距离。我在四种尺寸的板子上测试了我的算法:微型(2?4)、小型(5?5)、中型(8?8)、大型(14?14)。我保证了大型和中型的板子上的颜色比一般的颜色要少。因为大、中型的板子的确会使问题更难,对人和计算机都是如此(更多可能的路径/选择/状态)。这个算法在小型板子上运行的很好,但是花了相当多的时间。因此,我为下一个状态的函数增加了一些规则,以此希望强化学习的算法能够自己找出这些规则:防止同色相邻方格不连接,或者出现空“港湾”。
我那台7岁的电脑得到的结果是很让人开心的,但是仍需改进:
惭愧地说,我可能花在Tkinter图形函数上的时间比实际的AI要多如果你觉得你是第一个这么做的,那你很有可能就错了
在我使用强化学习之前,我一直尝试优化我的A*算法。当我发现Matt Zucker的一篇优秀的博客文章②时,他已经为Flow Free建立了一个A*解算器(很高兴的看到,我不是唯一一个有这种困扰的人),并且更加仔细地考虑过要把这些状态从他的A*搜索中剔除。更让人惊讶的是,他发现了一个只有6条规则的简单SAT算法,这比他最好的A*搜索法还表现还要好,而且在SAT中求解时间也非常短(对于14x14的板甚至低于1秒)。到目前为止,我们似乎都得出了同样令人沮丧的结论:对于这类(非对抗性的,封闭的)谜题游戏,简单的蛮力技术将超过基本的人工智能算法。不过,我不可能止步不前。毕竟,引发这一实验的问题仍然存在:作为人类玩家,在玩了几个关卡后,我们就能发现一些能够更有效地打败Flow Free谜题特定的技巧。为什么机器不能学习同样的技术呢?提到强化学习
我非常兴奋地在Flow Free问题中尝试了Q-learning算法,因为“AI”中的“I”即将要发挥它真正的作用了。A*搜索的工作也绝不是浪费时间,因为我们可以使用它的结果作为Q-learning智能体的状态-动作空间。状态空间由板上的方块颜色和哪条路径(颜色)目前是“活跃的”两部分组成。一个“动作”是指填充活跃路径的下一个方块。在一开始犯了一些基础的错误之后,智能体很快就学会了如何解决小型板问题(1.5秒内100次迭代)——到目前为止看起来还不错。但在中板上,花了10分钟,经过10000次迭代后,仍然没有结果: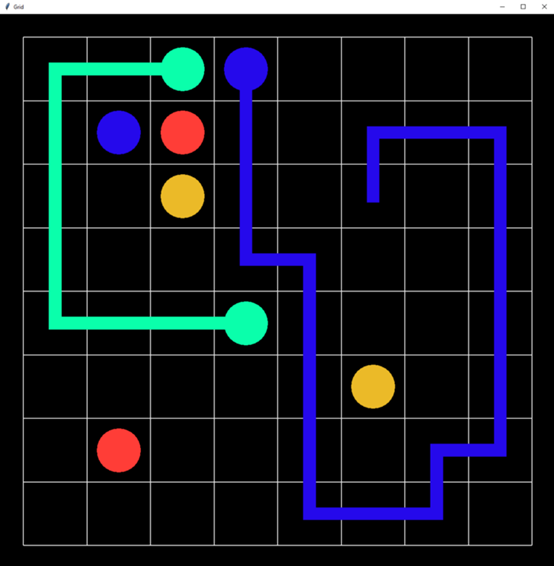
当你听到“人工智能”时,你想的结果可能和这个不一样。为了改善这种情况,我开始调试标准Q-learning的参数(学习率α、贴现率γ、勘探/开发率ε),但这并没有很大帮助,所以我将注意力转向到奖励函数。除了实际的“奖励”之外,还需要一个参数与奖励函数进行权衡(否则风险就会变得规范化,这会不利于整个机器学习活动):智能体是否会因为解决了一条路径获得奖励,而不是解决了整个谜题之后。不幸的是,这并没有起到多大作用。最后,逐渐清晰的是,算法之所以会在更大的板上苦苦挣扎,仅仅是因为操作空间太大了。相比于A*搜索,Q-learning在这种情况下确实做出了更明智、更有帮助的选择,但在大多数情况下,即使在10000次迭代之后,Q-learning 智能体还没有看到确切的结果。因此,下一步自然就是:近似 Q-learning
近似Q-learning的应用是十分有吸引力的,尤其是在游戏中。与其让智能体在给定的状态下决定最佳的操作,不如让它在每一步都能快速计算出一些直观、独立于具体状态(棋盘的配置)之外的特性,并让它自己决定哪些是最重要的。这在游戏中会担任游戏改变者的角色,例如Pcaman(举个例子,下一步的决策是基于最近的豆子和最近的幽灵,而不是在每种可能状态下的一个动作),当然也可以是状态数量太多,以至于让准确Q-learning失效的Flow Free。现在是开发人员需要权衡利弊挑选“正确”的特征的时候了。于是,我将列表精简到只有我认为在很多情况下重要的特征(例如,每条路径的剩余曼哈顿距离)。还有一些我认为重要的、只需要让算法计算的特征(但无法证明)。这些特征包括: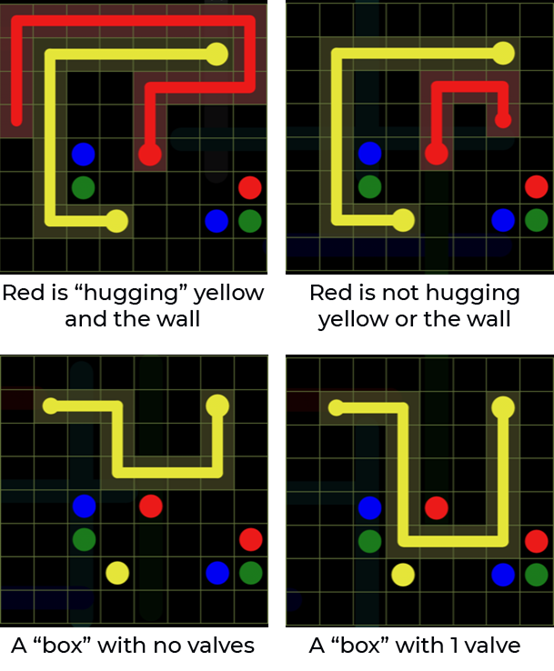
不幸的是,有了这些特征之后,Q-learning智能体甚至不能解决小型板问题,即使我们改变了Q-learning的参数也不行。但是,这也是个有趣的实践。例如,该算法在“没有阀门的盒子”上附加了一个强大的负权重,这意味着它能够了解到,没有阀门的盒子会导致谜题无法解决。
或许有了更大的谜题样本,它就能更好地学会如何真正地解决它们,但我很兴奋地看到它能真正地找到重要的东西。这在AI中是一个非常有趣的现象,尤其是在游戏AI中非常普遍:即使一个算法不能赢得游戏,它也可以帮助人类找到玩的更好的技巧。走向监督学习:卷积神经网络
一开始,我对通过监督的方法来实现Free Flow的想法存有偏见。首先,这需要大量的Free Flow游戏样本,而这些游戏很难在公共互联网上找到。其次,似乎与Free Flow最接近的监督学习方法——神经网络——是一个臭名昭著的黑盒算法,它会妨碍这个练习最有趣的部分:查看算法学习何种技术来解决这个难题。然而,后来我偶然读到了Shiva Verma在《Towards Data Science 》③杂志上的一篇文章,他在其中做了一些与数独游戏非常相似的事情:本质上是把一个数独游戏板当作一个图像,然后使用卷积神经网络(CNN)来解决它。作者在数独游戏中取得了很好的效果,这让我重新审视了我最初的想法,并尝试了这种方法来实现Flow Free。当然,第一个困难是获得输入的数据:用解析文本格式来寻找Free Flow谜题的答案,要比数独谜题更困难。最初,我发现寻找文件最好的方法是查看Android应用程序的代码,它有一千多个以文本格式存储的谜题:
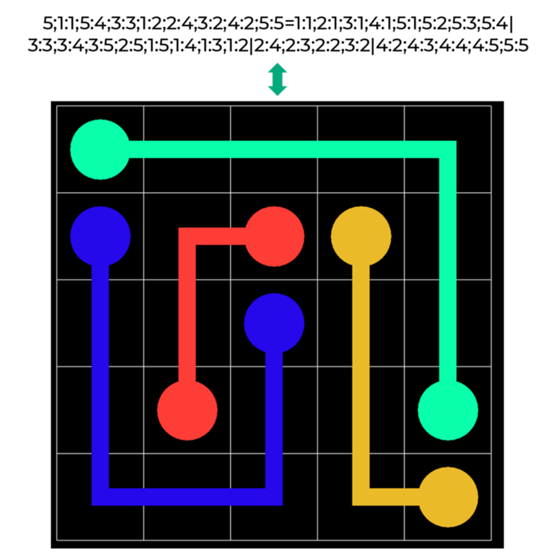
CNN的初始结果是令人失望的:尽管CNN正在学习它任务是创建路径,而不是仅仅在孤立地填充颜色,但在测试样本中只有0%的谜题被解决了。我们需要更多的数据
调整分层、训练次数、内核大小和其他类似的常见疑点并没有多大帮助。这似乎又回到了数据科学家最常见的问题:没有足够的数据,世界上最好的算法也什么都不是。我找到的其他最好的数据来源是www.flowfreesolutions.com,它有成千上万的对于全新的Free Flow问题的解法,比我的解法要多... 但是是图片格式的。尽管我尝试了无数次,通过各种渠道联系他们(甚至提供了经济奖励),我还是没能让他们给我发送一个可解析的文本版本的解决方案。好吧,这不是一篇免费的人工智能文章——当一个人有现代图像处理器的时候,谁还需要底层的解决方案矩阵呢?使用子项目建立一个Free Flow④解决方案图像处理器:
利用对称性来增加我们可用的数据
这就产生了几千个用来研究的数据点,但这仍然不是很多。但后来我意识到,就CNN而言,颜色的确切值并不重要,重要的是颜色是不同的。所以我们可以将颜色重新排列,并且仍然有另一个非冗余的数据点。即使对一个只有六种颜色的5x5的板来说,这可以给我们的CNN提供多达6!= 720倍的研究数据点(当然,等大的板和更多的颜色会有更多可选的组合)。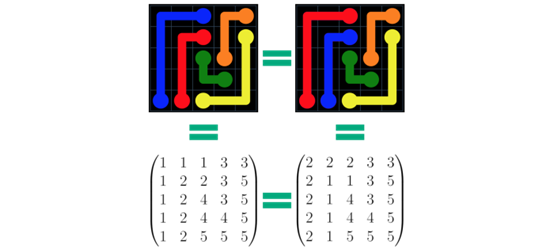
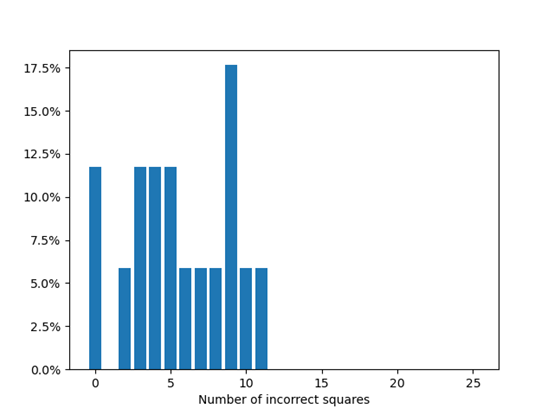
一位朋友指出,这实际上是游戏AI中增加数据点的常见方式。在720x的数据点的情况下,我们最终在一个20-epoch模型,使用大小约为200k的数据点测试集,在我7岁的GPU上运行了20分钟后得到的准确率为12%。需要注意的是,我们在这里使用了一个严格的衡量成功的标准:即使板子少用了一个单元格,我们也将其视为失败。但是,失败比成功有趣得多。在几乎所有的失败中,CNN正确地解决了板子的很大一部分,剩下的部分人们则很容易完成它。从这个意义上讲,CNN能够解决文章最初的问题:凭直觉学习人类的技巧:
结论
后续:读者和编者的建议
我们请了一些更有经验的AI/ML专家(非常感谢Matt Zucker⑤、Youssef Keyrouz⑥和Mark Saroufim⑦)来检阅这篇文章,他们建议尝试以下想法来改进CNN算法。第2部分文章的主题可能会详细介绍,您也可以在https://github.com/kgaspard/flow-free ai上自己动手尝试这些想法(以及本文中详细介绍的方法):链接:
①:https://www.bigduckgames.com/
②:https://mzucker.github.io/2016/08/28/flow-solver.html
③:https://towardsdatascience.com/solving-sudoku-with-convolution-neural-network-keras-655ba4be3b11
④:https://github.com/kgaspard/flow-free-ai/blob/master/imageParser.py
⑤:https://mzucker.github.io/swarthmore/
⑥:https://www.researchgate.net/profile/
Youssef_Keyrouz
⑦:https://medium.com/@marksaroufim
原文标题:
Deep Learning vs Puzzle Games
原文链接:
https://towardsdatascience.com/deep-learning-vs-puzzle-games-e996feb7616
译者简介:王紫岳,悉尼大学Data Science在读研究生,在数据科学界努力奋斗的求知者。喜欢有挑战性的工作与生活,喜欢与朋友们热切交谈,喜欢在独处的时候读书品茶。张弛有度,才能够以最饱满的热情迎接有点忙碌的生活。转自:?数据派THU 公众号;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




