
包含近 20 万本图书,OpenAI 级别的训练数据集上线

大数据文摘授权转载自HyperAI超神经
近日,机器学习社区的一篇资源热贴「用于训练 GPT 等大型语言模型的 196640 本纯文本书籍数据集」引发了热烈的讨论。
该数据集涵盖了截至 2020?年 9 月所有大型文本语料库的下载链接。除此之外,它还包含了所有的 bibliotik(一个线上图书资源库)中书籍的纯文本,以及大量用于训练的代码。

196640 册图书数据,训练你的 GPT
就在昨天,reddit 的机器学习社区上,网友 Shawn Presser 发布了一套纯文本数据集,得到一致好评。
这些数据集中共包含 196640 册纯文本数据,可以用于训练 GPT 等大型语言模型。
由于这套数据集包含多个数据集以及训练代码,我们在此不一一赘述,仅将其中的 books1 与 books3 数据集的具体信息列出:
据数据集整理者 Shawn Presser 介绍,这些数据集的质量是非常高的,仅 books1 数据集,就花费了他大约一周的时间,对 epub2txt 脚本进行修复。
此外,他还表示,books3 数据集似乎与 OpenAI 的论文中神秘的「books2」数据集相似。但是,由于 OpenAI 并没有提供这方面的详细信息,所以也无法了解二者之间的任何差异。
不过,在他看来,这份数据集极其接近 GPT-3 的训练数据集。拥有它,下一步,你也可以训练出与 GPT-3 相匹敌的 NLP 语言模型,当然,还有一个条件是,你还需要准备足够的 GPU。

数据集中 books1 数据集部分内容示例
据介绍,books1 数据集中 1800 本图书文本数据,都来自于大型文本语料库 BookCorpus,其中包括诗歌类、小说类等。
比如美国作家 Kristie Lynn Higgins 的《Shades of Gray:Noir, City Shrouded By Darkness》(《灰色阴影:被黑暗笼罩的城市》)、Benjamin Broke 的《Animal Theater》(《动物剧院》)、T·I·韦德的《America One》(《美国一号》)等。
强大的?GPT-3 背后,训练数据集立功劳
关注自然语言处理领域的小伙伴都知道,今年 5 月,OpenAI 斥巨资打造的自然语言处理模型 GPT-3,凭借惊人的文本生成能力,在业界引起高度关注,并且一直以来热度不减。
GPT-3 不仅可以更好地答题、翻译、写文章,还带有一些数学计算的能力。而它之所以拥有这些强大的能力,离不开背后巨量的训练数据集。
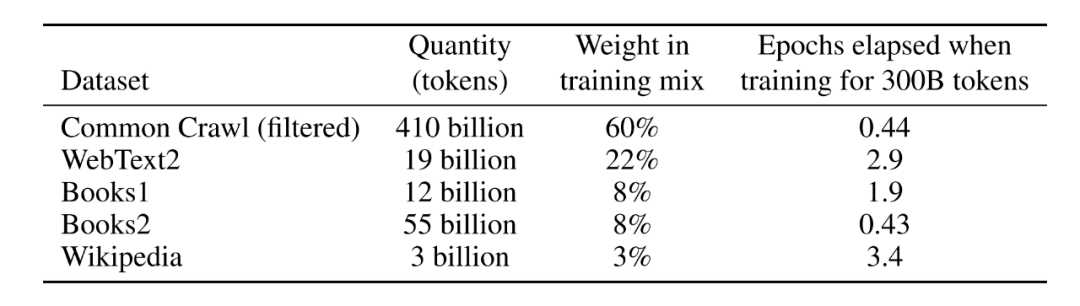
GPT-3?训练数据集一览
据介绍,GPT-3 使用的训练数据集十分庞大,基于包含近 1 万亿单词量的 CommonCrawl 数据集、网络文本、数据、维基百科等数据,它使用的最大数据集在处理前容量达到了 45TB,其训练费用也达到惊人的 1200 万美元。
更大的训练数据集、更多的模型参数,让 GPT-3 在自然语言处理模型中一骑绝尘。
然而,对于普通开发者来说,想要训练出一流的语言模型,暂且不说高昂的训练成本,仅仅在训练数据集这一步,就会被卡住。
因此,Shawn Presser 带来的数据集无疑解决了这一难题,一些网友表示,这项工作他们节省了巨大的成本。
超神经目前已经将 books1 数据集搬运至 https://hyper.ai,搜索关键词「书籍」或「文本」,或点击原文获取数据集。

其它数据集可从以下链接中获取:
books3 数据集下载地址:
https://the-eye.eu/public/AI/pile_preliminary_components/books3.tar.gz
训练代码下载地址:
https://the-eye.eu/public/AI/pile_preliminary_components/github.tar
reddit 原帖:
https://www.reddit.com/r/MachineLearning/comments/ji7y06/p_dataset_of_196640_books_in_plain_text_for/
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675