一个爬虫的故事:爬虫兄弟要活不下去了!!!


来源 | 编程技术宇宙

爬虫原理
我是一个爬虫,每天穿行于互联网之上,爬取我需要的一切。

User-agent: * Disallow: /a/ Disallow: /b/ Disallow: /c/



反爬虫技术
现在很多网站都上云了,云上的资源可昂贵了,CPU、内存、存储这些都价格不菲,尤其是网络带宽,价格是真心贵。



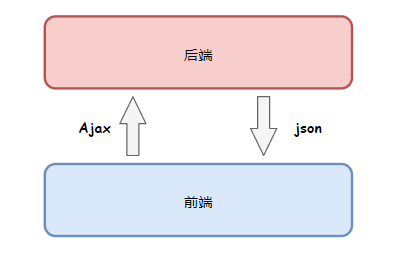
前后端分离
在我的职业生涯中,遇到过一些奇怪的网站,明明网页中有数据,但是我一访问拿到的HTML中啥也没有,一度让我很郁闷。


验证码
到后来,不知道是谁发明的,网站们纷纷用上了一种叫验证码的技术,给我们出了难题。




更多精彩推荐
?被判赔联想525万,常程方回应:提起诉讼;百度自动驾驶出租车在京全面开放;VS Code 1.50版发布|极客头条
点分享 点点赞 点在看



关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

![葛施敏蛋总过节了[awsl]#宠物卖萌中心# ](https://imgs.knowsafe.com:8087/img/aideep/2022/11/11/9e161f1bd9498d3cb88831df807c0ce1.jpg?w=250)



![索微 #不想和你有遗憾首映礼# 圆满结束!谢谢大家喜欢小西[可爱] ](https://imgs.knowsafe.com:8087/img/aideep/2024/12/24/37f4f7bac5bdc46007e95c7c5980f5a7.jpg?w=250)
 程序人生
程序人生
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接







排名
热点
搜索指数
- 1 中共中央召开党外人士座谈会 7904706
- 2 日本附近海域发生7.5级地震 7809281
- 3 日本发布警报:预计将出现最高3米海啸 7713749
- 4 全国首艘氢电拖轮作业亮点多 7616333
- 5 课本上明太祖画像换了 7523115
- 6 中国游客遇日本地震:连滚带爬躲厕所 7426025
- 7 最高13万元一只!实验猴价格暴涨 7331289
- 8 日本地震当地居民拍下自家书柜倒塌 7233990
- 9 女子自驾进猛兽区被老虎咬掉车漆 7140525
- 10 “人造太阳”何以照进现实 7044078