用 Python 详解《英雄联盟》游戏取胜的重要因素!

作者 | deephub
责编 | 王晓曼
出品 | CSDN博客

介绍
在过去的几年里,电子竞技社区发展迅速,曾经只是休闲娱乐的电子竞技产业,到2022年有望创造18亿美元的收入。
虽然在这个生态系统中有很多电子游戏,但很少有游戏像《英雄联盟》那样成为社区的主要元素,该游戏在2019年世界锦标赛期间吸引了超过1亿的独立观众。
《英雄联盟》于2009年底发行,是一款免费的多人在线战斗竞技场(MOBA)视频游戏,由 Riot Games 公司开发,这款游戏在早期就产生了广泛的竞争场景,2011年的第一届世界冠军创造了约160万观众。
随着 Riot 开始了解如何改变才能使游戏更具竞争性和趣味性,这款游戏在受欢迎程度和可玩性方面都有所提高。
在《英雄联盟》的比赛中,两队各有五名玩家,每一队都控制着一个独特的角色或“冠军”,当其中一队位于其基地深处的 Nexus 被摧毁时,比赛就会结束。
在这个过程中,一个团队可以实现很多目标,比如摧毁炮塔,杀死中立的怪物,比如龙和男爵,以获得整个团队的增益,等等。
有些目标,如摧毁至少五个炮塔和一个兵营,是赢得游戏所必需的,而其他目标,如获得第一滴血,是有益的,但不是必须的。
通过这个项目,我想更好的了解这些目标中哪一个是赢得英雄联盟游戏最重要的。就此而言,我提出的问题如下:
英雄联盟最重要的获胜条件是什么?

收集数据
我首先申请了一个使用 Riot Developer Portal 的应用程序,在我的应用程序被接受后,我浏览了 api 列表,以了解我可以请求的数据类型。
不幸的是,没有一种直接的方法可以从一个区域中取出最后X个排名的匹配项,所以我必须找到一种方法来解决这个问题。
我的解决方案是使用召唤者名称列表(用户名)来为每个玩家生成最近的比赛列表。通过 Python 包 Riot-Watcher 的调用,获取了差不多10000行的数据与五个地区最新联赛比赛的前100名玩家的数据。
乍一看,DataFrame 看起来是这样的:
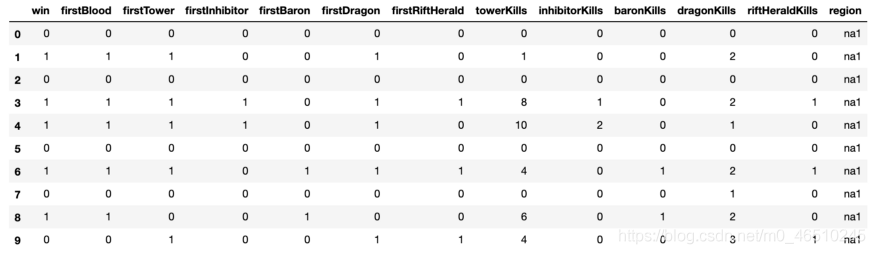
在前7列中,0表示“False”,1表示“True”,而在后面的列中,单元格中编码的数据表示事件发生的次数。每行都包含了一场排位比赛中的一支队伍的统计数据。例如,在第一排,没有获得任何目标的团队首先输掉了整个比赛。

探索性数据分析热图和主成分分析
首先,我发现91%的获胜团队摧毁了第一个兵营,80%杀死了第一个男爵,70%摧毁了第一个塔,63%杀死了第一条龙,59%的获胜团队以第一滴血开始游戏。
现在看来,最重要的获胜条件是摧毁第一个兵营,这是有意义的,因为摧毁一条线路的兵营会给他们的基地带来压力,并允许对方拥有更多的地图控制。
接下来,我可视化了数据集中各列之间的相关性:

我还为我的数据中所代表的每个独立地区找到了相同的关联热图,以比较不同地区之间的关联,希望能注意到游戏风格的一些差异。
一般来说,相关矩阵看起来非常相似。一个可能的原因是,我的数据包含了每个地区最好的玩家的比赛,其中许多人是职业选手。
因此,由于良好的游戏实践在竞争性社区中是一致的,所以我的数据中所代表的匹配涉及到那些在每一款游戏中顶级玩家,而这些玩家相对于每个区域中排名较低的玩家来说是相似的。
我现在很想知道数据中的方差是如何用较少的特征来解释的,而不是我用来预测游戏结果的10个特征。在这种程度上,我进行了主成分分析,以了解我可以将数据简化成多少特征,同时保留大部分的方差:
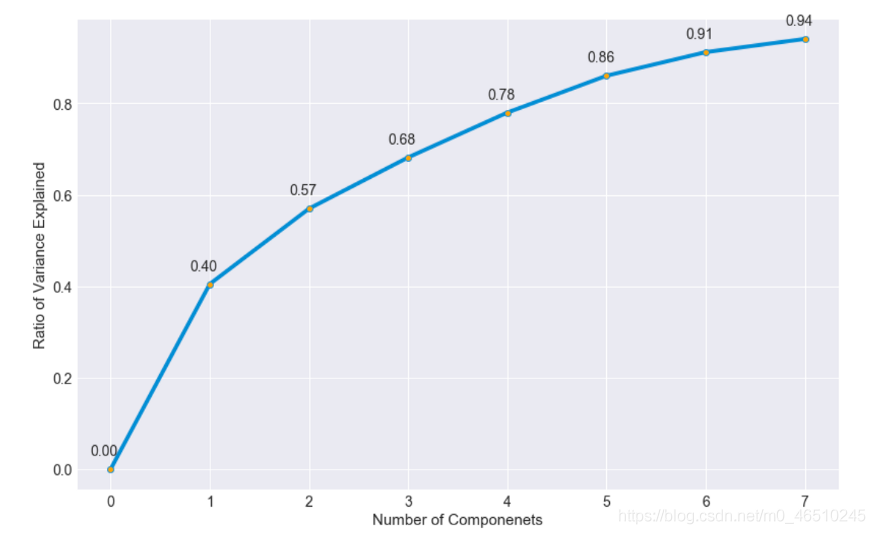
十个预测列中超过80%的方差可以用一半的特征量来解释。这确实很有趣,通过将每个组件与原始数据集的列关联起来,我希望了解在解释数据的差异时哪些特性是最重要的,这可以帮助我弄清楚哪些列对一个团队是否会获胜最关键。

用于生成上述热图的组件来自一个包含六个PCA对象,因为我希望这些组件能够解释数据中超过90%的差异。看来推塔,摧毁兵营,以及一个团队是否摧毁了第一个兵营在确定方差最重要的特征数据,第一个组件解释40%的方差和三个上述列加权最该组件。
重申一下我在这一点上的领悟:
从我的关联热图来看,无论一个团队是否摧毁了第一个兵营,一个团队推掉了多少塔,以及一个团队摧毁了多少兵营都与获胜有最高的相关性。
从我的 PCA 分析来看,团队是否摧毁了第一个兵营,团队摧毁了多少塔,以及团队摧毁了多少兵营在解释数据中的差异方面发挥了最大的作用。

使用逻辑回归进行数据建模
我使用了 Logistic 回归模型来理解《英雄联盟》排名比赛的获胜条件。我的过程是首先将我的数据分割成一组特征和一组目标,其中我的特征是除 ‘win’ 和 ‘region’列 之外的所有列,我的目标是‘win’列。
然后我将我的数据分解为一个列集和一个测试集,通过 Logistic 回归模型进行运行,并检查分类报告和混淆矩阵,确保有较强的预测能力。当逻辑回归模型在整个数据集上运行时,模型的精度和召回率分别为。86和。85。
从这里开始,我对只包含一个区域的数据子集进行逻辑回归,比如只在 NA、BR 等中进行的匹配,并在一个 Pandas 数据模型中记录模型的系数。这个数据图被可视化了,所以我可以比较不同的区域:
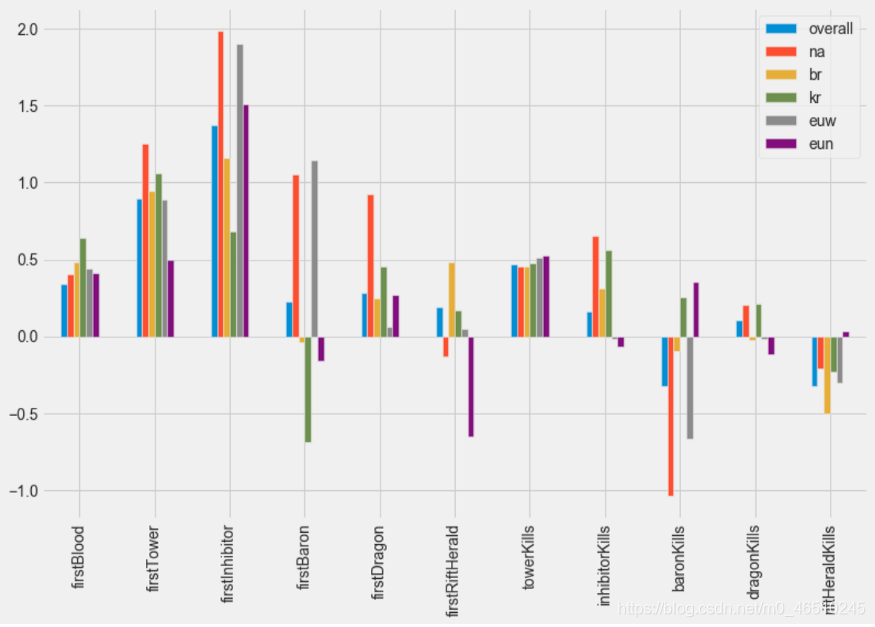
回归系数描述预测变量和目标变量之间的关系。例如,当我们看上面的一血预测变量时,第一个拿到一血的队伍是对比赛结果的适度预测,因为第一个拿一血的队伍更有可能获胜。
另一方面,峡谷先驱的击杀实际上是在相反的方向上相关的(除了EUNE),并且获得更多峡谷先驱击杀的队伍更有可能输掉。
通过这个分析过程,我了解了哪些专栏更能预测胜利,帮助我回答了关于《英雄联盟》中获胜条件的问题。

结论
通过我的项目,我得出以下结论:
根据我的逻辑回归模型,按照最大到最小的顺序,第一个兵营,第一个塔,塔摧毁是数据集中最重要的获胜条件(这是推塔游戏)。
根据我的关联热图,从最大到最小,塔摧毁,第一个兵营,兵营摧毁数是数据集中最重要的获胜条件(这是推塔游戏)。
虽然获得第一个 baron 的 NA 和 EUW 团队更有可能获胜,但随着杀死的baron 数量的增加,这些地区的团队更有可能失败。
与其它地区相比,在 NA 地区的团队更有可能赢得第一只龙,这一事实或许表明在 NA 地区的游戏更倾向于龙的爱好者和围绕龙的战斗滚雪球式的游戏(当一个团队在游戏中扩大一个小优势以赢得胜利)。
KR游戏并没有受到一个特性的不均衡影响。这可能表明KR的队员比其它地区的队员更了解如何在劣势中有戏,这促使团队比其它地区的团队更经常地赢得组合目标。
本文源代码:https://github.com/ankushbharadwaj/league-of-legends-win-conditions
译者注:这个模型没有使用 “region”列作为训练参数使用国服数据训练可能是个败笔,毕竟处理祖安的玩家数据可能需要更多的自然语言处理技术提取聊天的特征,这才是祖安人胜利的关键!
声明:本文为 CSDN 博主「deephub」的翻译文章,版权归作者所有。
原文:https://blog.csdn.net/m0_46510245/article/details/108116199


更多精彩推荐
?实用小技能 | 用 Word 和 Excel 自制一个题库自判断答题系统! ?中国数据库产业的“高地战事” ?融资 2000 万美元后,他竟将核心代码全开源,这……能行吗? ?Get了!用Python制作数据预测集成工具 | 附代码 ?学会这10大高性能开发技术,轻松躲过裁员名单! ?小心!你可能玩了假的DeFi 点分享 点点赞 点在看



关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 应变克难开新局 7904853
- 2 外交部回应美批准对华出售H200芯片 7809606
- 3 日本气象厅:一周内或发生9级地震 7714651
- 4 “好房子”长啥样 7618876
- 5 你点的三家外卖可能出自同一口锅 7519716
- 6 山姆就“麻薯盒中出现活老鼠”致歉 7428082
- 7 中方回应向日本出口稀土出现延误 7333206
- 8 受贿超11亿!白天辉被执行死刑 7236514
- 9 一定要在这个年龄前就开始控糖 7138002
- 10 入冬以来最大范围风雪天气来了 7048747