
shiro权限绕过漏洞-开发者的挣扎之路


前言
近期shiro多次对权限绕过问题进行了修复,在此对相关漏洞进行学习分析,了解整个修复过程中的安全对抗策略。
本地环境:idea + ?shirodemo项目代码
(shirodemo链接地址:
https://github.com/hex0wn/learn-java-bug/tree/master/shiro-auth)


CVE-2020-1957
?
版本<1.5.0
有人在github上提交pr(链接地址:
https://github.com/apache/shiro/pull/127)表示可以通过在末尾增加/,绕过shiro的权限认证。随后官方对这个pr进行了合并,发布了版本1.5.0。
使用修复前的最后一个版本1.4.2进行测试,配置的路径拦截规则如下:

? map.put("/doLogin", "anon");
? map.put("/hello/*", "authc");
bean.setFilterChainDefinitionMap(map);
? ? ? ?
顺利通过 /hello/a/ 绕过权限限制

调试看看漏洞现场的具体情况,根据补丁信息(链接地址:
https://github.com/apache/shiro/pull/127/commits/e61a29cd6ad4724cf9d85c463103c01f6bafdc44)
把断点打在PathMatchingFilter.pathsMatch和PathMatchingFilterChainResolver.getChain函数。
程序运行后停在getChain函数中,它调用getPathWithinApplication获取URI路径,然后遍历filterChains逐个进行匹配pathMatches
?

实际的匹配逻辑在方法AntPathMatcher.doMatch,先将pattern和path解析成字符串数组,此时会忽略多余的分隔符/。然后逐项进行匹配,存在**则会跳出循环并且倒序再匹配,在matchString中对*和?进行匹配处理。
总结一下ant匹配语法:
?:匹配一个字符
*:匹配零个或多个字符串
**:匹配路径中的零个或多个路径
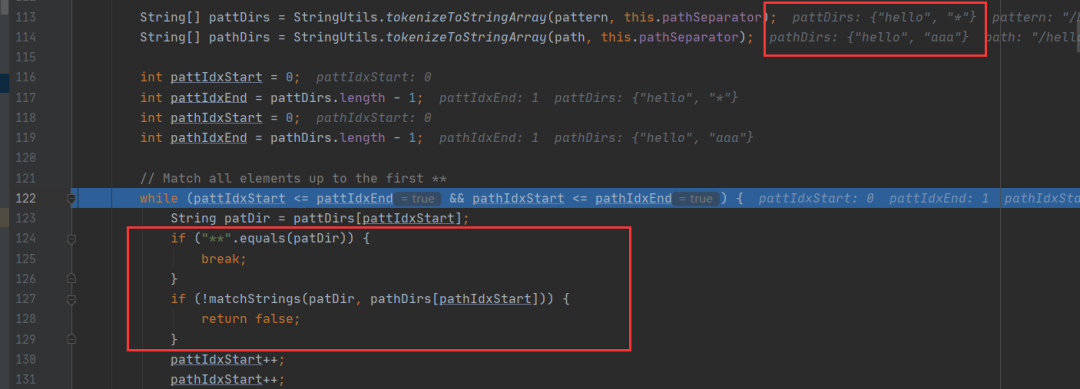
正向匹配完所有字符数组,然后会校验pattern和path的末尾的斜线是不是一致。这里校验失败导致绕过了校验
?
1.5.0补丁
在调用pathMatches进行匹配查找之前把path和pattern最后的/删除
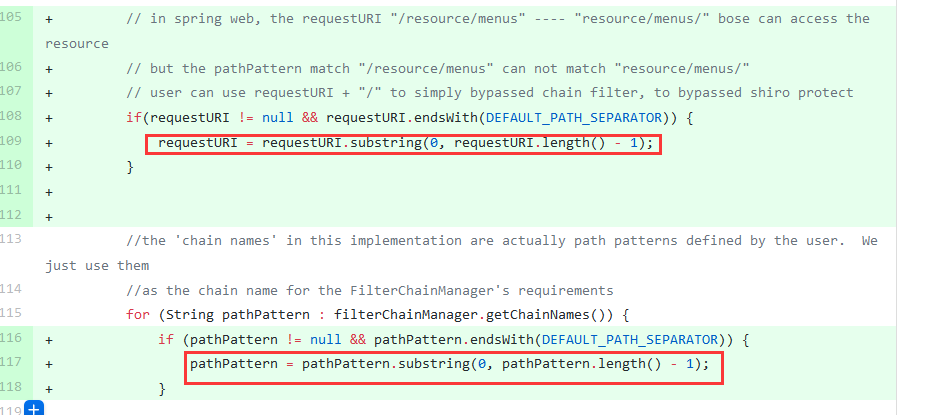
1.5.0补丁绕过
由于tomcat的特性,可以通过;来绕过。访问/hello;/aaa/
此时getPathWithinApplication获取到的路径为/hello,导致绕过。

?
网传的另外一个PoC :
/fdsf;/../hello/1,
但我在本地复现报404错误
?
1.5.2补丁
针对1.5.0的绕过,官方发布了1.5.2版本进行修复。
在WebUtils.getRequestUri函数中,原先从request.getRequestURI()获取路径,现在拼接getContextPath、getServletPath、getPathInfo三部分。

至此CVE-2020-1957的生命结束,但新一轮的抗争由此开始。
CVE-2020-11989
再仔细看看WebUtils.getRequestUri方法,其中会调用decodeAndCleanUriString和normalize对uri进行处理。
decodeAndCleanUriString先会对uri进行url解码,然后如果存在;则截取前半部分字符串。而normalize则是对\、//、/./、/../进行处理。

根据decodeAndCleanUriString就能构造出新的绕过 /hello/%253ba,shiro解析出来的URI是/hello/,与pattern ?/hello/*匹配不上。
除了通过截断URI还可以通过插入路径分隔符让*匹配不上,使用?/hello/a%252fa,shiro解析到的/hello/a/a 同样也匹配不到 /hello/*
?
1.5.3补丁
直接拼接getServletPath和getPathInfo,不再进行解码操作。removeSemicolon函数用来截取分号;

?
把1.5.2中对WebUtils.getRequestUri的改动进行了还原,并且标记为Deprecated。getServletPath和getPathInfo只是进行了封装,本质还是从request对象中获取数据
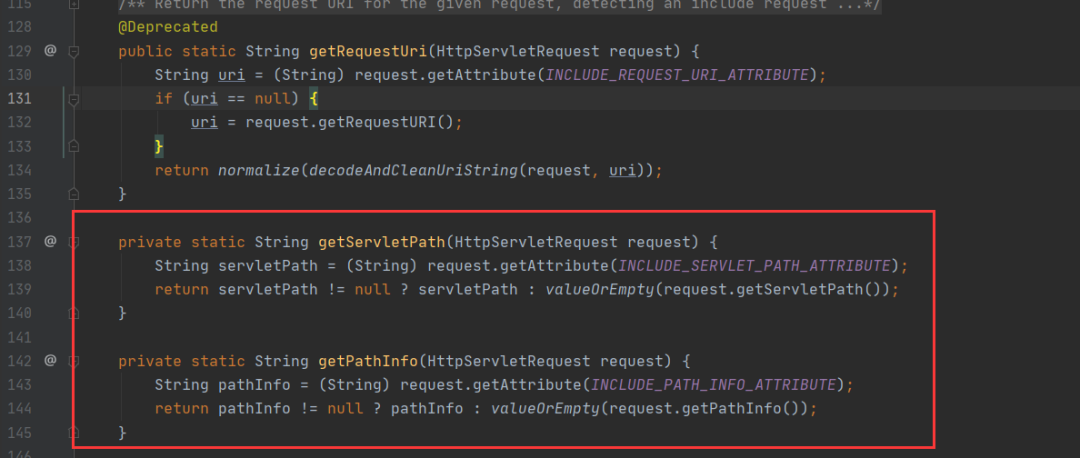
CVE-2020-13933
咋一看补丁没什么问题,但仔细想想这里却别有洞天。
在getServletPath和getPathInfo之前,tomcat已经对;进行了normalize处理,这里的;其实是url中的%3b,不太明白开发者为什么要在这里处理。可以继续用%3b截断path来绕过pattern校验,PoC:/hello/%3ba。
这个PoC只影响1.5.0到1.5.3版本,但不影响最开始的1.4.2版本。因为1.5.0补丁引入的代码会将path和pattern最后的/删除,导致pathMatches函数中pattern:/hello/* 匹配不到path:/hello/了,中间的多次绕过都利用了这一点。


终局之战

1.6.0版本的修复方式有点狠,新增InvalidRequestFilter检查getRequestURI()中是否存在黑名单元素(";", "%3b", "%3B" "\\", "%5c", "%5C" )以及非打印字符。
?

修复方式比较有效,但也引入了一个bug。原本客户端没设置cookie的情况下,重定向到登录页时会带参数 /login;jsessionid=xxx,但目前302后会导致请求400 Bad Request。
shiro权限绕过的问题也许没有真正落幕,期待下一次绕过的出现。
?
参考链接
https://issues.apache.org/jira/browse/SHIRO-682
https://segmentfault.com/a/1190000019440231
https://www.freebuf.com/vuls/231909.html
https://xlab.tencent.com/cn/2020/06/30/xlab-20-002/



关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 斗鱼安全应急响应中心
斗鱼安全应急响应中心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675