作者:Jason Brownlee ??翻译:张一然 ?校对:李洁本篇文章主要介绍了几种常用的数据准备方法,以及在数据准备的过程中如何避免数据泄露。原始的数据准备方法是在评估模型性能之前对整个数据集进行处理。这会导致数据泄漏的问题, 测试集中的数据信息会泄露到训练集中。那么在对新数据进行预测时,我们会错误地估计模型性能。为了避免数据泄漏,我们需要谨慎使用数据准备技术,?同时也要根据所使用的模型评估方案灵活选择,例如训练测试集划分或k折交叉验证。在本教程中,您将学习在评估机器学习模型时如何避免在数据准备过程中的数据泄漏。应用于整个数据集的简单的数据准备方法会导致数据泄漏,从而导致对模型性能的错误估计。
为了避免数据泄漏,数据准备应该只在训练集中进行。
如何在Python中用训练测试集划分和k折交叉验证实现数据准备而又不造成数据泄漏。在我的新书
(https://machinelearningmastery.com/data-preparation-for-machine-learning/)
中了解有关数据清理,特征选择,数据转换,降维以及更多内容,包含30个循序渐进的教程和完整的Python源代码。
用原始数据准备方法进行训练-测试评估
用正确的数据准备方法进行训练-测试评估
用原始数据准备方法进行交叉验证评估
用正确的数据准备方法进行交叉验证评估
一种常见的方法是首先将一个或多个变换应用于整个数据集。然后将数据集分为训练集和测试集,或使用k折交叉验证来拟合并评估机器学习模型。尽管这是一种常见的方法,但在大多数情况下很可能是不正确的。在分割数据进行模型评估之前使用数据准备技术可能会导致数据泄漏, 进而可能导致错误评估模型的性能。数据泄漏是指保留数据集(例如测试集或验证数据集)中的信息出现在训练数据集中,并被模型使用的问题。这种泄漏通常很小且微妙,但会对性能产生显著影响。‘’…泄漏意味着信息会提供给模型,这给它做出更好的预测带来了不真实的优势。当测试数据泄漏到训练集中时,或者将来的数据泄漏到过去时,可能会发生这种情况。当模型应用到现实世界中进行预测时,只要模型访问了它不应该访问的信息,就是泄漏。数据泄漏的直接形式是指我们在测试数据集上训练模型。而当前情况是数据泄漏的间接形式,是指训练过程中,模型可以使用汇总统计方法捕获到有关测试数据集的一些知识。对于初学者而言很难察觉到第二种类型的数据泄露。“重采样的另一个方面与信息泄漏的概念有关,信息泄漏是在训练过程中(直接或间接)使用测试集数据。这可能会导致过于乐观的结果,这些结果无法在将来的数据上复现。例如,在某些情况下我们要对数据进行归一化,即将输入变量缩放到0-1范围。当我们对输入变量进行归一化时,首先要计算每个变量的最大值和最小值, 并利用这些值去缩放变量. 然后将数据集分为训练数据集和测试数据集,但是这样的话训练数据集中的样本对测试数据集中的数据信息有所了解。数据已按全局最小值和最大值进行了缩放,因此,他们掌握了更多有关变量全局分布的信息。几乎所有的数据准备技术都会导致相同类型的泄漏。例如,标准化估计了域的平均值和标准差,以便缩放变量;甚至是估算缺失值的模型或统计方法也会从全部数据集中采样来填充训练数据集中的值。数据准备工作只能在训练数据集中进行。也就是说,任何用于数据准备工作的系数或模型都只能使用训练数据集中的数据行。一旦拟合完,就可以将数据准备算法或模型应用于训练数据集和测试数据集。更普遍的是,仅在训练数据集上进行整个建模工作来避免数据泄露。这可能包括数据转换,还包括其他技术,例如特征选择,降维,特征工程等等。这意味着所谓的“模型评估”实际上应称为“建模过程评估”。“为了使任何重采样方案都能产生可泛化到新数据的性能估算,建模过程中必须包含可能显著影响模型有效性的所有步骤。?—第54-55页,特征工程与选择,2019年。”
既然我们已经熟悉如何应用数据准备以避免数据泄漏,那么让我们来看一些可行的示例。在本节中,我们利用合成二进制分类数据集分出训练集和测试集,并使用这两个数据集评估逻辑回归模型, 其中输入变量已归一化。我们将使用make_classification()函数创建包含1000行数据和20个数值型特征的数据。下面的示例创建了数据集并总结了输入和输出变量数组的形状。
运行这段代码会得到一个数据集, 数据集的输入部分有1000行20列, ?20列对应20个输入变量, 输出变量包含1000个样例对应输入数据,每行一个值。
接下来我们要在缩放后的数据上评估我们的模型, 首先从原始或者说错误的方法开始。原始方法首先对整个数据集应用数据准备方法,其次分割数据集,最后评估模型。我们可以使用MinMaxScaler类对输入变量进行归一化,该类首先使用默认配置将数据缩放到0-1范围,然后调用fit_transform()函数将变换拟合到数据集并同步应用于数据集。得到归一化的输入变量,其中数组中的每一列都分别进行过归一化(例如,计算出了自己的最小值和最大值)。
下一步,我们使用train_test_split函数将数据集分成训练集和测试集, 其中67%的数据用作训练集,剩下的33%用作测试集。
通过LogisticRegression 类定义逻辑回归算法,使用默认配置, 并拟合训练数据集。
拟合模型可以对测试集的输入数据做出预测,然后我们可以将预测值与真实值进行比较,并计算分类准确度得分。

运行上述代码, 首先会将数据归一化, 然后把数据分成测试集和训练集,最后拟合并评估模型。由于学习算法和评估程序的随机性,您的具体结果可能会有所不同。在本例中, 模型在测试集上的准确率为84.848%
我们已经知道上述代码中存在数据泄露的问题, 所以模型的准确率估算是有误差的。接下来,让我们来学习如何正确的进行数据准备以避免数据泄露。利用训练集-测试集分割评估来执行数据准备的正确方法是在训练集上拟合数据准备方法,然后将变换应用于训练集和测试集。
然后,我们可以定义MinMaxScaler并在训练集上调用fit()函数,然后在训练集和测试集上应用transform()函数来归一化这两个数据集。
我们只用了训练集而非整个数据集中的数据来对每个输入变量计算最大值和最小值, 这样就可以避免数据泄露的风险。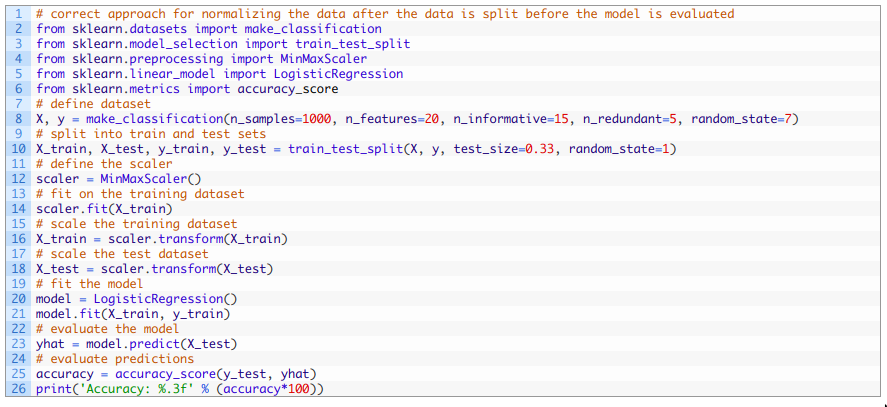
运行示例会将数据分为训练集和测试集,对数据进行正确的归一化,然后拟合并评估模型。由于学习算法和评估程序的随机性,您的具体结果可能会有所不同。在本例中,我们可以看到该模型在测试集上预测准确率约为85.455%,这比上一节中由于数据泄漏达到84.848%的准确性更高。我们预期数据泄漏会导致对模型性能的错误估计,并以为数据泄漏会乐观估计,例如有更好的性能。然而在示例中,我们可以看到数据泄漏导致性能更差了。这可能是由于预测任务的难度。
在本节中,我们将在合成的二分类数据集上使用K折交叉验证评估逻辑回归模型, 其中输入变量均已归一化。您可能还记得k折交叉验证涉及到将数据集分成k个不重叠的数据组。然后我们只用一组数据作为测试集, 其余的数据都作为训练集对模型进行训练。将此过程重复K次,以便每组数据都有机会用作保留测试集。最后输出所有评估结果的均值。k折交叉验证过程通常比训练测试集划分更可靠地估计了模型性能,但由于反复拟合和评估,它在计算成本上更加昂贵。具有交叉验证的原始数据准备首先要对数据进行变换,然后再进行交叉验证过程。我们将使用上一节中准备的合成数据集并直接将数据标准化。
首先要定义k折交叉验证步骤。我们将使用重复分层的10折交叉验证,这是分类问题的最佳实践。重复是指整个交叉验证过程要重复多次,在本例中要重复三次。分层意味着每组样本各类别样本的比例与原始数据集中相同。我们将使用k = 10的10折交叉验证。我们可以使用RepeatedStratifiedKFold(设置三次重复以及10折)来实现上述方案,然后使用cross_val_score()函数执行该过程,传入定义好的模型,交叉验证对象和要计算的度量(在本例中使用的是准确率 )。
综上,下面列出了使用带有数据泄漏的数据准备进行交叉验证评估模型的完整示例。
运行上述代码, 首先对数据进行归一化,然后使用重复分层交叉验证对模型进行评估。由于学习算法和评估程序的随机性,您的具体结果可能会有所不同。在本例中,我们可以看到该模型达到了约85.300%的估计准确度,由于数据准备过程中存在数据泄漏,我们知道该估计准确度是不正确的。
接下来,让我们看看如何使用交叉验证评估模型同时避免数据泄漏。使用交叉验证时,没有数据泄漏的数据准备工作更具挑战性。它要求在训练集上进行数据准备,并在交叉验证过程中将其应用于训练集和测试集,例如行的折叠组。我们可以通过定义一个建模流程来实现此目的,在要拟合和评估的模型中该流程定义了要执行的数据准备步骤的顺序和结束条件。“ 为了提供可靠的方法,我们应该限制自己仅在训练集上开发一系列预处理技术,然后将这些技术应用于将来的数据(包括测试集)。—第55页,特征工程与选择,2019年。”
评估过程从错误地仅评估模型变为正确地将模型和整个数据准备流程作为一个整体单元一起评估。此类使用一个包含定义流程的步骤的列表。列表中的每个步骤都是一个包含两个元素的元组。第一个元素是步骤的名称(字符串),第二个元素是步骤的配置对象,例如变换或模型。尽管我们可以在序列中使用任意数量的转换,但是仅在最后一步才应用到模型。
之后我们把配置好的对象传入cross_val_score()函数进行评估。
综上所述,下面列出了使用交叉验证时正确执行数据准备而不会造成数据泄漏的完整示例。

运行该示例可在评估过程进行交叉验证时正确地归一化数据,以避免数据泄漏。由于学习算法和评估程序的随机性,您的具体结果可能会有所不同。本例中,我们可以看到该模型的估计准确性约为85.433%,而数据泄漏方法的准确性约为85.300%。与上一节中的训练测试集划分示例一样,消除数据泄露带来了性能上的一点提高, 虽然直觉上我们会认为它应该会带来下降, 以为数据泄漏会导致对模型性能的乐观估计。但是,这些示例清楚地表明了数据泄漏确实会影响模型性能的估计以及在拆分数据后通过正确执行数据准备来纠正数据泄漏的方法。
在本教程中,您学习了评估机器学习模型时如何避免在数据准备期间出现数据泄露的问题。原文链接:
https://machinelearningmastery.com/data-preparation-without-data-leakage/
译者简介:张一然,哥本哈根大学计算机系硕士毕业, 研究方向为图像补全。现从事自然语言处理工作。感兴趣方向为计算机视觉和自然语言处理,喜欢看书旅游。转自:数据派THU 公众号;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
END
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




