
GAN不只会造假:捕获数据中额外显著特征,提高表征学习可解释性,效果超越InfoGAN | IJCAI 2020
杨净 鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
提起GAN,你或许会想起真假难辨的人脸生成。

但其实,GAN的能力并不只局限在图像生成上。
用GAN做无监督表征学习,就可以去做图像分类了,就像那个半路出家的BigBiGAN,秒杀了一众专注分类20年的AI选手。
现在,最新研究表明,在无监督环境中,GAN在学习可解释性表征方面也大有可为。
在实际情况中,有一些表征可能是各种因素相互作用的结果,忽略这些相互作用可能会导致无法发现更多的特征。
针对这一问题,AI独角兽明略科技联合两所高校,提出了一个新的正则化器,对潜伏空间变量的相互作用施加结构约束,有效地探索数据中额外的显著特征。

目前已入选IJCAI 2020会议论文。
用GAN提取信息纠缠的显著特征
现有的无监督学习可解释表征的方法着重于「从数据中提取独立不纠缠的显著特征」,但是这一方法忽略了显著特征的纠缠可能会提供有用信息。
而认识到这些信息纠缠,可以提高表征的可解释性,从而提取出更高质量和广泛的显著特征。
也就是说,要实现更好的可解释性,需要同时考虑非纠缠和信息纠缠的显著特征。
基于此,本文的核心方法是:用生成对抗网络GAN,来学习非纠缠和信息纠缠的可解释性表征。
具体来说,就是提出了一个正则化器,对潜在变量的信息纠缠进行结构性约束,使用贝叶斯网络对这些交互进行建模,做最大似然估计,并计算负似然分数以衡量分歧。
基于InfoGAN
先来了解一下这篇文章的背景。
这篇文章是以InfoGAN为基础。它是当前最先进的用于「离散表征学习」的生成对抗网络,通过将GAN的对抗损失函数与一组观测值和生成器输出之间的相互信息进行正则化来进行离散表征。
它于2016年首次提出,由加州大学伯克利分校、OpenAI联合开发,能够完全以无监督学习的方式来学习离散表征。

InfoGAN学习的可解释性表征与现有的监督方法学习的表征相比具有竞争力。互信息最大化鼓励网络将解耦变量与生成的输出联系起来,迫使生成器给这些变量赋予意义。
由于互信息分量难以计算,InfoGAN通过最大化变量下限来近似计算。
但其正则化器并不能保证发现的显著特征之间的独立性。实际情况中,这些特征可能会相互影响,存在纠缠的情况。
于是,IJCAI的这篇论文用GAN学习可解释性表征问题,并同时考虑了离散变量和信息纠缠变量。
文章提出利用依赖结构,建模观测值和数据显著特征之间的关系,并将这种结构作为GAN训练的约束条件。
建模变量关系
为了在观测变量和显著特征之间施加结构化关系,本文利用了判别器的特征提取能力。
在GAN训练中,判别器学习从训练数据中提取显著特征,生成器根据判别器的输出进行更新。

以上图为例,绿色节点为输入的观测数据,红色节点为判别器提取出来的潜码(latent code),这些节点组成的图就是依赖结构。
如果在观测变量与显著特征之间施加一个结构化关系,那么观测变量将与训练数据的显著特征联系在一起。
正如图中提取出的三个特征,其中两个引出第三个。而连接红绿两点的线代表了观测变量与潜码之间的因果关系,让观察变量控制生成器输出的显著特征。
然后,将一组观测变量与判别器潜码的「联合分布」表示为贝叶斯网络的形式。
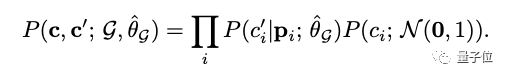
但需要注意的是,通过估计每个局部条件概率的参数,而不是直接估计联合分布参数,由此获得对各个因果关系重要性的控制。
之所以选择贝叶斯网络,主要有如下原因,
1、与大多数独立性检验相比,贝叶斯网络结构能够表示更精细的变量关系。
2、建立变量联合分布模型所需的数据量比非结构化的方法要少。
3、捕捉显著特征之间的「因果关系」可以提高可解释性,也就是说,一些变量如何纠缠可能会提供关于数据的额外信息,以及独立因子所代表的内容。
将带有结构损失的GAN正则化
之后,研究团队设计来一个正则化器,利用如下等式中定义的似然函数所取的值,来指导GAN的训练。
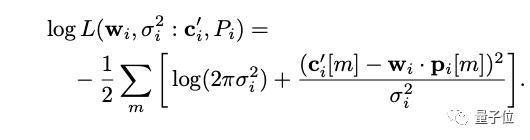
由于似然函数衡量的是给定模型的数据概率,所以当最大似然估计插入时,这个函数所取的值提供了一个天然的度量标准来衡量G对数据的拟合程度。
其中,G为给定的「联合分布」和局部条件参数的最大似然估计。
与最大似然估计过程不同的是,本文是操纵分布本身来寻找一个给定的G所代表的最佳数据生成器。
损失函数为:
最终,利用所提出的损失函数,将GAN训练的正则化为:
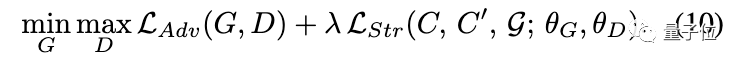
通过提出的结构损失正则化,GAN学习表示训练数据分布,同时观测变量和潜码关系遵循指定的图形结构,这样就可以控制提取变量的相互作用。
换句话说,为了提取相互之间完全独立的潜在变量,可以定义一个观测变量和潜码之间具有一对一连接的图结构。
另一方面,为了提取相互引起的变量,还可以在潜在变量之间增加连接。
实验结果:超越SOTA
所以,GAN学习可解释表征的效果如何?
研究人员在合成数据集和真实世界数据集上进行了实验验证。
实验中,正则化是在和InfoGAN相同的判别器和生成器架构上实现的,同时采用网格搜索来调整参数。
MNIST数据集
在MNIST数据集中,实验所采用的图结构如下。

结果显示,尽管InfoGAN很好地捕捉到了旋转特征,但如下图中(b)和(d)所示,粗细特征并没有被充分区分开。
基本上,对于所有InfoGAN生成的数字,粗细度增加,数字也会旋转。同时,一些数字的特征会出现丢失,比如「5」。
本文提出的新方法则成功捕捉了这两个不同的视觉特征,并且不影响数字的数字特征。
? ? ? ?
另外,研究人员也测试了两种方法的泛化能力。
模型仍然在 ci∈[-1,1] 的条件下训练,但在 ci∈{-2,0,2} 的条件下生成图像。
结果表明,新方法比InfoGAN的泛化能力更强,在输出图像变粗的同时,携带了更丰富的数字特征。

另外,研究人员发现,在使用该正则器学习的表征中,粗细度增加的同时,数字宽度也会增加。这暗示了宽度和粗细特征之间存在信息纠缠。
进一步的实验表明,基于本文提出的正则化器,可以引导GAN的训练,以探索更多的显著特征。
利用信息纠缠,有可能拆分出其他显著特征相互作用的产物,也有可能发现纠缠在一起但显著的新特征。
研究人员如下图所示调整了图结构。这使得GAN趋向于发现2个会影响第3个特征的潜伏特征。

研究人员观察到,c1和c2分别捕获了宽度和粗细度的特征,而c3则捕获了宽度和粗细度的混合特征。
这一结果说明,反馈给学习网络G的图结构,能够引导GAN发现遵循期望的因果关系的变量。
3D Faces Dataset
研究人员还在3D Faces数据集上进行了实验。该数据集包含24万个人脸模型,这些人脸模型的旋转度、光线、形状和高度会随机变化。
结果同样表明,InfoGAN并没能提取第4个混合特征。而本文提出的正则器能够引导GAN捕获旋转、仰角、光线、宽度这全部4个特征。
dSprites Dataset
之后,研究人员在dSprites数据集上对新方法进行了实验。
这个数据集通常被用来给不同的表征学习模型所实现的解构进行评分和比较。
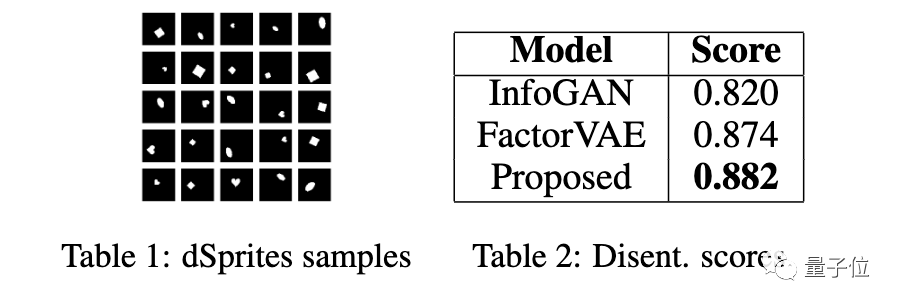
结果显示,该方法在得分上超过了SOTA方法。
最后总结一下:通过定性和定量比较,研究人员证明了本文提出的正则化器可以从数据中发现比SOTA更广泛的显著特征,并且实现了比SOTA更强的泛化性能。
研究人员表示,下一步,他们将完成两个目标:
· 设计一种学习最佳图结构的算法来探索显著特征
· 进行非图像数据集的实验
作者介绍
这篇论文的作者,分别来自路易斯安那大学拉斐特分校、约翰内斯·开普勒大学林茨分校,以及国内AI独角兽明略科技。
第一作者是来自路易斯安那大学拉斐特分校的Ege Beyazit博士研究生。
他的研究方向是机器学习和数据挖掘。
此外,明略科技集团首席科学家、明略科学院院长,IEEE&AAAS fellow吴信东也参与了这项研究。
传送门
论文地址:
https://www.ijcai.org/Proceedings/2020/273
— 完 —
本文系网易新闻?网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
报名 |「隐私计算+AI」技术直播
不了解任何隐私AI技术的情况下,开发者怎样做到只改动两三行代码,就将现有AI代码转换为具备数据隐私保护功能的程序?


量子位?QbitAI · 头条号签约作者
?'?' ? 追踪AI技术和产品新动态
喜欢就点「在看」吧 !
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 量子位
量子位
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675