
无监督学习?Yann LeCun说:或许应该叫它预测性学习

??新智元报道??
??新智元报道??
来源:danrose
编辑:白峰
【新智元导读】随着机器学习的不断发展,无监督学习在近年来备受关注。Yann LeCun提出赋予无监督学习新的名字——预测性学习。
 ? ? ? ?
? ? ? ?监督学习、无监督学习和强化学习:机器学习的三驾马车 ?
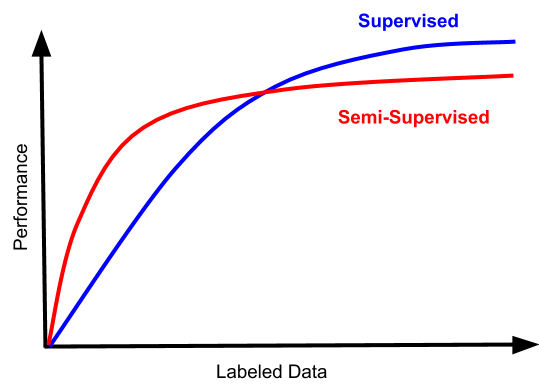
昂贵且复杂的数据标记让监督学习变得困难 ?
 ? ? ? ?
? ? ? ?
无监督学习(预测性学习)正在登上历史舞台
正如Yann LeCun所说,无监督学习是「填补空白」。填补空白不仅仅是将相似的事物归类,填补空白就像是想象。?在训练预测学习模型时,目的是了解当前的世界。?
 ? ? ??
? ? ??
「预测性学习」可能会改变我们的未来 ?
 ? ? ? ?
? ? ? ?
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/





![阿薰kaOr把小肚子又魔鬼训练了二十天[捂嘴哭]](https://imgs.knowsafe.com:8087/img/aideep/2025/11/30/6a7ad77b5a7a386c89053ef93d418986.jpg?w=250)
 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675