

作者 |?Xinrui Wang, Jinze Yu
译者 |?刘畅
出品?| AI科技大本营(ID:rgzani100)
卡通爱好者的福利来了。
现在,通过在Cartoonize这个应用上一键上传你拍摄的图像或视频,就可以在很短时间内将它卡通化。其核心技术来自CVPR 2020的投稿论文,作者的背景是字节跳动和东京大学,他们提出了用白盒卡通表征实现图像卡通化。
目前,这项工作已在GitHub获得1400个Stars。作者称,他们还计划很快将开源所有代码。下一步,他们的目标是通过将模型移植到tensorflow.js来适应实时视频推理。
GitHub链接:
https://github.com/SystemErrorWang/White-box-Cartoonization
来看看这项工作的卡通化效果。

很有卡通化的味道吧?

视频卡通化的效果也可以。
当然,如果你想在这款应用上上传你拍摄的图片或视频来进行卡通化,这是地址:
https://cartoonize-lkqov62dia-de.a.run.app/cartoonize
本文提出了一种将图像卡通化的方法。通过观察卡通绘画行为并咨询卡通艺术家,本文提出可以从图像中分别识别三个白盒表示:一是卡通图像平滑表面的轮廓表示,二是针对稀疏色块和全局内容的结构表示,三是在卡通图像中反映高频纹理,轮廓和细节的纹理表示。作者利用生成对抗网络(GAN)框架来学习提取的表示并将图像卡通化。本文方法的学习目标是分别基于每个提取的表示,从而使本文的框架可控和可调整。这使本文的方法能够满足不同风格和不同用处的艺术家的要求。最后,对本文方法进行了定性和定量的比较分析,以及用户研究,以验证这种方法的有效性。结果是本文方法在所有比较中均优于之前的方法。最后,消融实验表明了本文框架中每个部分的作用。卡通是一种流行的艺术形式,且已广泛应用于各种场景。现代卡通动画工作流程允许艺术家使用各种资源来创作内容。通过将真实世界的图片转换为可用的卡通场景素材,创造了一些著名的漫画,该过程称为图像卡通化。各种卡通风格和用处需要基于特定任务或者先验知识才能开发可用的算法。例如,某些卡通工作流程更加关注全局调色板主题,但是线条的清晰度却是次要问题。在其他一些工作流程中,稀疏和干净的色块在艺术表达中起着主导作用,但是主题却相对较少强调。这些变量因素给黑盒模型带来了不小的挑战,例如,当面对不同用例中艺术家的不同需求时,简单地更改训练数据集是无济于事的。因此有了用于图像卡通化的CartoonGAN网络,其中提出了一种具有新颖边缘损失的GAN框架,并在某些情况下取得了良好的效果。但是,使用黑盒模型直接拟合训练数据会降低其通用性和风格化质量,在某些情况下会导致较差的效果。为了解决上述问题,本文对人们绘画的行为和不同风格的卡通形象进行了大量的观察,并咨询了少数几位卡通艺术家。根据本文的观察结果(如上图所示),本文建议将图像分解为几种卡通表征方式,并将它们列出如下:第一步:提取一个带权重的低频内容表示图片的轮廓特征(surface representation)。这个低频内容保留了边缘/纹理等细节。这与艺术家画卡通时通常先描绘形状类似。第二步:针对输入图像,提取一个分割图,并且在每个分割区域上使用一个自适应的色彩算法来生成结构表征(structure representation)。这是模仿画卡通画时,边界清晰且色块稀疏的胶片(celluloid)风格。第三步:纹理表征(texture representation)是用来保持绘画细节和边缘的。将输入图像转换为仅保留相对像素强度的图像,然后引导网络独立地学习高频纹理细节。这与艺术家素描与上色是独立的两个过程类似。单独提取的卡通表征形式使卡通化问题可以在生成神经网络(GAN)框架内进行端到端的优化,使其可扩展和可控,更加适用于实际的使用场景,并可以针对特定任务进行微调以轻松满足多样化的艺术需求。本文在各种风格不同的场景中测试了本文的将真实图片卡通化的方法。实验结果表明,该方法可以生成色彩和谐,令人愉悦的艺术风格,清晰锐利的边缘以及明显更少的伪影。本文还显示,通过定性定量的实验和用户研究,本文方法是优于之前的最新方法。最后,本文进行了消融实验以说明每种表征方式的作用。最后,本文的贡献如下:根据对卡通绘画行为的观察,本文提出了三种卡通表示:轮廓表示,结构表示和纹理表示。然后引入图像处理模块以提取每个表示。
在提取表示的指导下优化了基于GAN的图像卡通化框架。用户可以通过平衡每个表示的权重来调整模型输出的样式。
已经进行了广泛的实验,表明我们的方法可以生成高质量的卡通图像。我们的方法在定性比较,定量比较和用户偏爱方面均优于现有方法。
图4显示了本文提出的图像卡通化框架。它将图像分解为轮廓表征,结构表征和纹理表征,并引入了三个独立的模块来提取相应的特征表示。GAN的框架包含了一个生成器和两个判别器。一个判别器是区分卡通图的输出和轮廓特征,另一个判别器是区分卡通图的输出和纹理特征。预训练的VGG网络用于提取高级特征,并对提取的结构表示和输出之间以及输入图片和输出之间的全局内容施加空间约束。损失函数中每部分内容的权重都可以调整,这使用户可以控制输出样式并使模型适应各种用处。作者定义了一个网络F_dgf,以图片I为输入,并以它自己为guide map,输出提取的去掉纹理和细节的外观特征F(I,I)。同时定义了一个判别器D_s,用以判断真实图和卡通图的输出分布是否一致。损失函数就是经典的gan的损失函数,如下,其中Ic为输入的卡通图,Ip为真实图。一般超像素算法会把每个区域用区域内的均值来填充,但是作者通过实验发现这样效果不好。因此作者使用了改进的算法,他把算法称之为“adaptive coloring”,其实就是一个分段函数:结构损失如下,其中VGG_n是使用VGG16预训练好的提取图片特征的网络,F_st为专门处理结构损失的网络。作者认为亮度和颜色信息会使人很容易分辨真实和卡通图片,因此在学习纹理特征的时候,作者把RGB图转为了单通道的图,这样就排除了亮度和颜色信息的影响。Frcs公式如上图所示,把RGB三个通道分开处理,Y表示的是RGB图转化成的灰度图。在本实验中α等于0.8,而3个β值则在-1~1之间随机。此处也定义了一个D_t判别器,来判断经过F_rcs后的输出是来自生成器生成的还是动漫图。如下所示:其中TV损失是为了降低总方差,可以促进生成图像的平滑,并减轻高频的噪音。公式如下:?content的损失是为了让经过生成器后的真实图语义不变,这里也用到了预训练后的VGG。本文算法是基于tensorflow实现的,代码已开源。训练的超参基本都是常规的训练参数,而loss权重的超参是基于对训练集的统计确定的。作者对模型的性能和效果均做了分析,效果如下,本文算法在对比的算法中,是最高效的。下图效果展示了本文算法的泛化能力,能够处理多种复杂的真实场景,包含人、动物、植物等等。接下来作者做了消融实验,以FID为评价标准,结果如表格2所示。计算出的FID度量标准表明,卡通表征是有助于缩小现实世界的图像和卡通图像之间的距离,因为与原始图像相比,所有三个提取的卡通表征都具有较小的FID。图10是显示消融实验中,每个特征表示的结果。图8展示了本文算法的可调控性。结果显示可以通过在损失函数中调整每个特征表征的权重来调整卡通化结果的样式。图9与表格3是本文算法与其它算法定性定量的对比。可以看出,本文算法是更优的。本文中,作者提出了一种基于GAN的白盒可控的图像卡通化框架,该框架可以从真实图像中生成高质量的卡通化图像。输入图像被分解为三个卡通表征:轮廓表征,结构表征和纹理表征。然后使用相应的图像处理模块来提取用于网络训练的三个表征,并且可以通过调整损失函数中每个表征的权重来控制输出风格。最后进行了广泛的定量和定性实验,验证了本文方法的性能。同时消融实验也证明了每个特征表示带来的作用。https://systemerrorwang.github.io/White-box-Cartoonization/paper/06791.pdf

推荐阅读
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








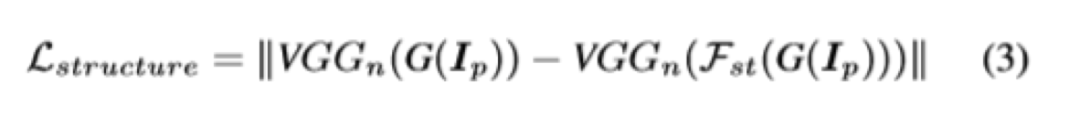
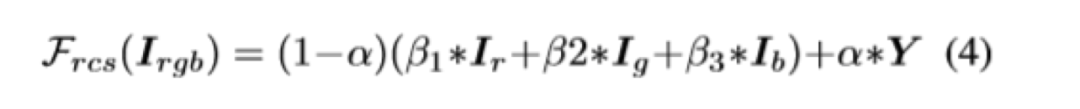

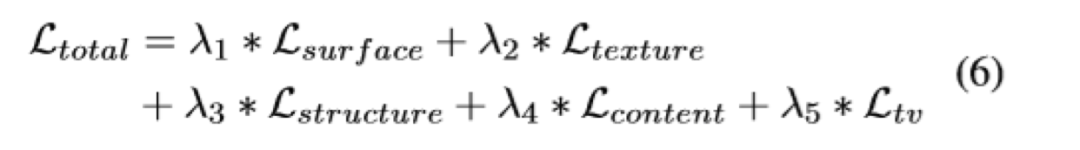
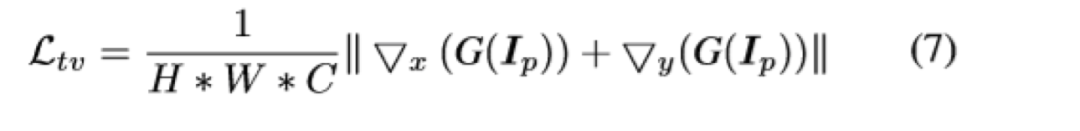
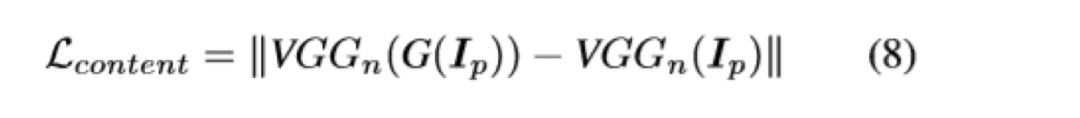













 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




