
推荐 : 你想用深度学习谱写自己的音乐吗?这篇指南来帮助你!(附代码)
学习如何开发一个自动生成音乐的端到端模型
理解WaveNet架构并使用Keras从零开始实现它
在建立自动音乐生成模型的同时,比较了WaveNet和Long-Short-Term Memory的性能

使用WaveNet架构
使用Long-Short-Term Memory(LSTM)


从头开始学习卷积神经网络(CNNs)的全面教程
深度学习要领:长短期记忆(LSTM)入门
学习序列建模的必读教程
音符:单键发出的声音称为音符
和弦:由两个或更多的键同时发出的声音称为和弦。一般来说,大多数和弦包含至少3个键音
八度:重复的模式称为八度。每个八度包含7个白键和5个黑键
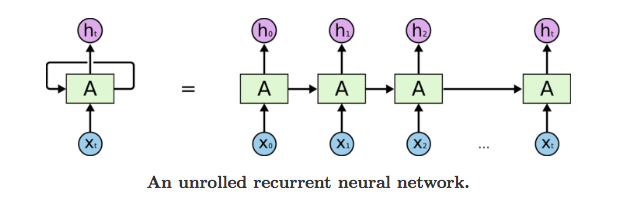
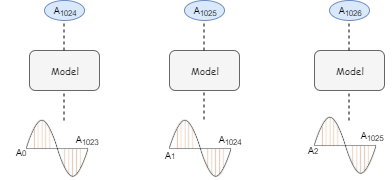
前3个块的输入和输出

卷积神经网络(CNNs)结构的解密
https://www.analyticsvidhya.com/blog/2017/06/architecture-of-convolutional-neural-networks-simplified-demystified/?utm_source=blog&utm_medium=how-to-perform-automatic-music-generation
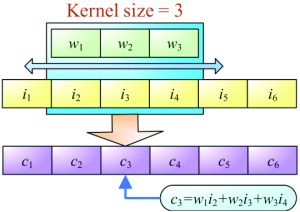
捕获输入序列中出现的序列信息
与GRU或LSTM相比,训练的速度要快得多,因为它们没有循环性的连接
当填充设置为same时,在时间步长t处的输出也与之前的t-1和未来的时间步长t+1进行卷积。因此,它违反了自回归原则
当填充被设置为valid时,输入和输出序列的长度会发生变化,这是计算残差连接所需要的(后面会讲到)

因果卷积没有考虑未来的时间步长,而这是建立生成模型的一个标准
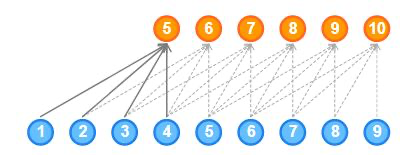
因果卷积不能回溯到序列中过去发生的时间步长。因此,因果卷积的接受域非常低。网络的接受域是指影响输出的输入数量:
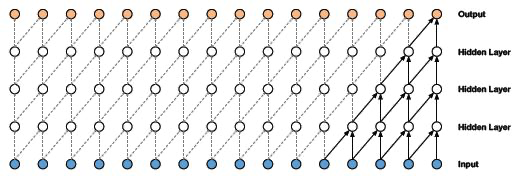

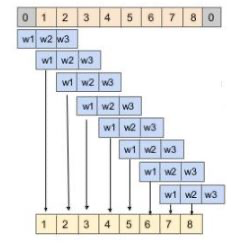
扩张的一维卷积网络通过指数增加每一隐藏层的扩张率来增加接受域:

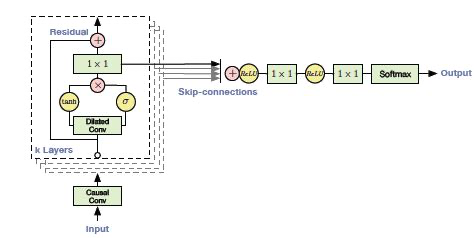
输入进入一个因果一维卷积
输出然后进入到2个不同的扩张一维卷积层并使用sigmoid和tanh激活
两个不同激活值逐元素相乘导致跳跃连接
而跳跃连接和因果一维输出的逐元素相加会导致残差
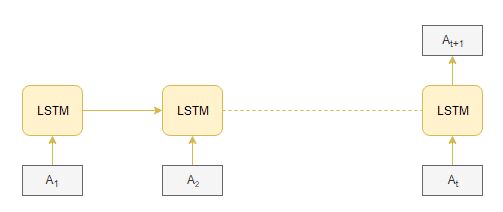
捕获输入序列中出现的顺序信息
由于它是按顺序处理输入信息的,所以它在训练上会花费大量的时间
(https://drive.google.com/file/d/1qnQVK17DNVkU19MgVA4Vg88zRDvwCRXw/view)
1. #library for understanding music2. from music21 import *
1. #defining function to read MIDI files2. def read_midi(file):3.4. print("Loading Music File:",file)5.6. notes=[]7. notes_to_parse = None8.9. #parsing a midi file10. midi = converter.parse(file)11.12. #grouping based on different instruments13. s2 = instrument.partitionByInstrument(midi)14.15. #Looping over all the instruments16. for part in s2.parts:17.18. #select elements of only piano19. if 'Piano' in str(part):20.21. notes_to_parse = part.recurse()22.23. #finding whether a particular element is note or a chord24. for element in notes_to_parse:25.26. #note27. if isinstance(element, note.Note):28. notes.append(str(element.pitch))29.30. #chord31. elif isinstance(element, chord.Chord):32. notes.append('.'.join(str(n) for n in element.normalOrder))33.34. return np.array(notes)
1. #for listing down the file names2. import os3.4. #Array Processing5. import numpy as np6.7. #specify the path8. path='schubert/'9.10. #read all the filenames11. files=[i for i in os.listdir(path) if i.endswith(".mid")]12.13. #reading each midi file14. notes_array = np.array([read_midi(path+i) for i in files])
1. #converting 2D array into 1D array2. notes_ = [element for note_ in notes_array for element in note_]3.4. #No. of unique notes5. unique_notes = list(set(notes_))6. print(len(unique_notes))
1. #importing library2. from collections import Counter3.4. #computing frequency of each note5. freq = dict(Counter(notes_))6.7. #library for visualiation8. import matplotlib.pyplot as plt9.10. #consider only the frequencies11. no=[count for _,count in freq.items()]12.13. #set the figure size14. plt.figure(figsize=(5,5))15.16. #plot17. plt.hist(no)
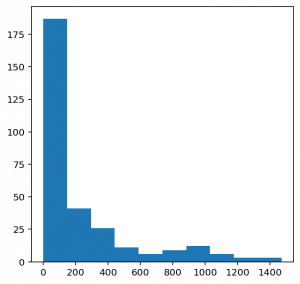
1. frequent_notes = [note_ for note_, count in freq.items() if count>=50]2. print(len(frequent_notes))
1. new_music=[]2.3. for notes in notes_array:4. temp=[]5. for note_ in notes:6. if note_ in frequent_notes:7. temp.append(note_)8. new_music.append(temp)9.10. new_music = np.array(new_music)
1. no_of_timesteps = 322. x = []3. y = []4.5. for note_ in new_music:6. for i in range(0, len(note_) - no_of_timesteps, 1):7.8. #preparing input and output sequences9. input_ = note_[i:i + no_of_timesteps]10. output = note_[i + no_of_timesteps]11.12. x.append(input_)13. y.append(output)14.15. x=np.array(x)16. y=np.array(y)
1. unique_x = list(set(x.ravel()))2. x_note_to_int = dict((note_, number) for number, note_ in enumerate(unique_x))
1. #preparing input sequences2. x_seq=[]3. for i in x:4. temp=[]5. for j in i:6. #assigning unique integer to every note7. temp.append(x_note_to_int[j])8. x_seq.append(temp)9.10. x_seq = np.array(x_seq)
1. unique_y = list(set(y))2. y_note_to_int = dict((note_, number) for number, note_ in enumerate(unique_y))3. y_seq=np.array([y_note_to_int[i] for i in y])
1. from sklearn.model_selection import train_test_split2. x_tr, x_val, y_tr, y_val = train_test_split(x_seq,y_seq,test_size=0.2,random_state=0)
1. def lstm():2. model = Sequential()3. model.add(LSTM(128,return_sequences=True))4. model.add(LSTM(128))5. model.add(Dense(256))6. model.add(Activation('relu'))7. model.add(Dense(n_vocab))8. model.add(Activation('softmax'))9. model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')10. return model
1. from keras.layers import *2. from keras.models import *3. from keras.callbacks import *4. import keras.backend as K5.6. K.clear_session()7. model = Sequential()8.9. #embedding layer10. model.add(Embedding(len(unique_x), 100, input_length=32,trainable=True))11.12. model.add(Conv1D(64,3, padding='causal',activation='relu'))13. model.add(Dropout(0.2))14. model.add(MaxPool1D(2))15.16. model.add(Conv1D(128,3,activation='relu',dilation_rate=2,padding='causal'))17. model.add(Dropout(0.2))18. model.add(MaxPool1D(2))19.20. model.add(Conv1D(256,3,activation='relu',dilation_rate=4,padding='causal'))21. model.add(Dropout(0.2))22. model.add(MaxPool1D(2))23.24. #model.add(Conv1D(256,5,activation='relu'))25. model.add(GlobalMaxPool1D())26.27. model.add(Dense(256, activation='relu'))28. model.add(Dense(len(unique_y), activation='softmax'))29.30. model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')31.32. model.summary()
mc=ModelCheckpoint('best_model.h5',?monitor='val_loss',?mode='min',?save_best_only=True,verbose=1)??
1. #loading best model2. from keras.models import load_model3. model = load_model('best_model.h5')
1. import random2. ind = np.random.randint(0,len(x_val)-1)3.4. random_music = x_val[ind]5.6. predictions=[]7. for i in range(10):8.9. random_music = random_music.reshape(1,no_of_timesteps)10.11. prob = model.predict(random_music)[0]12. y_pred= np.argmax(prob,axis=0)13. predictions.append(y_pred)14.15. random_music = np.insert(random_music[0],len(random_music[0]),y_pred)16. random_music = random_music[1:]17.18. print(predictions)
1. x_int_to_note = dict((number, note_) for number, note_ in enumerate(unique_x))2.?predicted_notes?=?[x_int_to_note[i]?for?i?in?predictions]??
1. def convert_to_midi(prediction_output):2.3. offset = 04. output_notes = []5.6. # create note and chord objects based on the values generated by the model7. for pattern in prediction_output:8.9. # pattern is a chord10. if ('.' in pattern) or pattern.isdigit():11. notes_in_chord = pattern.split('.')12. notes = []13. for current_note in notes_in_chord:14.15. cn=int(current_note)16. new_note = note.Note(cn)17. new_note.storedInstrument = instrument.Piano()18. notes.append(new_note)19.20. new_chord = chord.Chord(notes)21. new_chord.offset = offset22. output_notes.append(new_chord)23.24. # pattern is a note25. else:26.27. new_note = note.Note(pattern)28. new_note.offset = offset29. new_note.storedInstrument = instrument.Piano()30. output_notes.append(new_note)31.32. # increase offset each iteration so that notes do not stack33. offset += 134. midi_stream = stream.Stream(output_notes)35. midi_stream.write('midi', fp='music.mid')
convert_to_midi(predicted_notes)??
由于训练数据集的规模较小,我们可以对预训练的模型进行微调,以建立一个鲁棒的系统
尽可能多地收集训练数据,因为深度学习模型在更大的数据集上泛化更好
原文链接:
https://www.analyticsvidhya.com/blog/2020/01/how-to-perform-automatic-music-generation/
原文题目:
Want to Generate your own Music using Deep Learning? Here’s a Guide to do just that!
译者简介:吴金笛,雪城大学计算机科学硕士一年级在读。迎难而上是我最舒服的状态,动心忍性,曾益我所不能。我的目标是做个早睡早起的Cool Girl。
「完」

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675