
常用数据分析方法:方差分析及实现!
一个复杂的事物,其中往往有许多因素互相制约又互相依存。方差分析是一种常用的数据分析方法,其目的是通过数据分析找出对该事物有显著影响的因素、各因素之间的交互作用及显著影响因素的最佳水平等。
本文介绍了方差分析的基础概念,详细讲解了单因素方差分析、双因素方差分析的原理,并且给出了它们的python实践代码。
本文大纲:
关于方差分析的基础概念
单因素方差分析原理及python实现
双因素方差分析原理及python实现
一、关于方差分析的基础概念
下面我们先重点研究单因素方差分析, 通过一个例子,引出方差分析中的几个概念:
某保险公司想了解一下某险种在不同的地区是否有不同的索赔额。于是他们就搜集了四个不同地区一年的索赔额情况的记录如下表:
尝试判断一下, 地区这个因素是否对与索赔额产生了显著的影响?
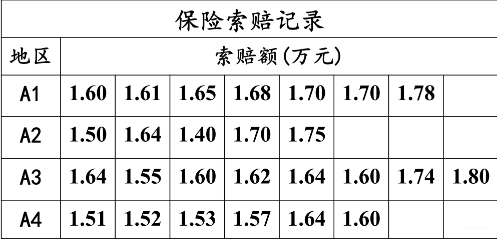
试验指标:方差分析中, 把考察的试验结果称为试验指标, 上面例子里面的“索赔额”。
因素:对试验指标产生影响的原因称为因素, 如上面的“地区”
水平:因素中各个不同状态, 比如上面我们有A1, A2, A3, A4四个状态, 四个水平。
这个类比的话, 就类似于y就是试验指标, 某个类别特征x就是因素, 类别特征x的不同取值就是水平。那么通过方差分析, 就可以得到某个类别特征对于y的一个影响程度了吧, 这会帮助分析某个类别特征的重要性!
二、单因素方差分析原理及python实现
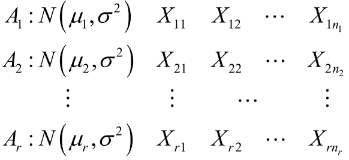
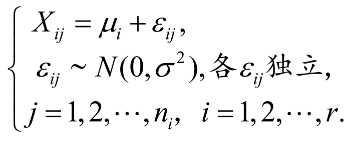
基于上面的分析, 我们就可以把方差分析也看成一个检验假设的问题, 并有了原假设和备择假设:
:
:?不全相等
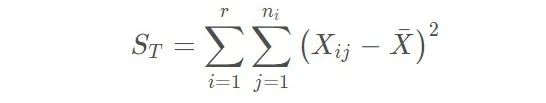
综合所有的水平, 就可以得到误差平方和的公式如下:
而上面两者相减, 就会得到效应平方和:
通过上面的分析,我们会得到以下三点结论:
?(这个分解式为上面模型的方差分析)
这里是因为:
当为真的时候,
基于上面的分析,会得到一个单因素试验方差分析表:
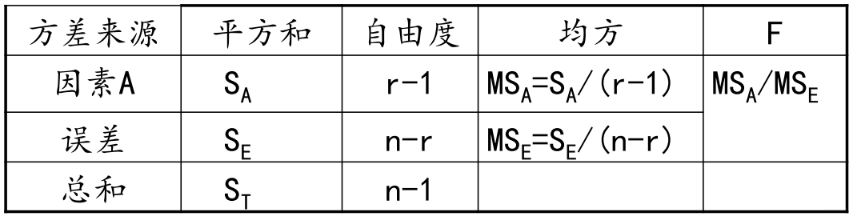
下面就用python实现一下上面的那个索赔额的例子, 看看单因素方差分析是怎么做的:
import pandas as pdimport numpy as npfrom scipy import statsfrom statsmodels.formula.api import olsfrom statsmodels.stats.anova import anova_lm# 这是那四个水平的索赔额的观测值A1 = [1.6, 1.61, 1.65, 1.68, 1.7, 1.7, 1.78]A2 = [1.5, 1.64, 1.4, 1.7, 1.75]A3 = [1.6, 1.55, 1.6, 1.62, 1.64, 1.60, 1.74, 1.8]A4 = [1.51, 1.52, 1.53, 1.57, 1.64, 1.6]data = [A1, A2, A3, A4]# 方差的齐性检验w, p = stats.levene(*data)if p < 0.05:print('方差齐性假设不成立')# 成立之后, 就可以进行单因素方差分析f, p = stats.f_oneway(*data)print(f, p) # 2.06507381767795 0.13406910483160134
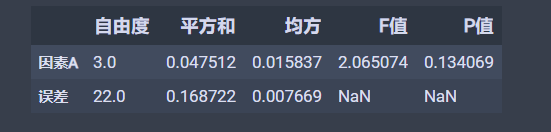
后面通过stats.f_oneway函数就可以直接算出检验假设的值和值。我们这里关注的是值, 拿值和给出的(一般是0.05)比, 如果,我们就接受原假设,否则拒绝原假设,这个例子中是0.134,大于,故接受原假设,认为不同的地区的索赔额没有显著差异。
values = A1.copy()groups = []for i in range(1, len(data)):values.extend(data[i])for i, j in zip(range(4), data):groups.extend(np.repeat('A'+str(i+1), len(j)).tolist())df = pd.DataFrame({'values': values, 'groups': groups})df
数据长这个样子了,也是我们一般见到的pandas的形式:
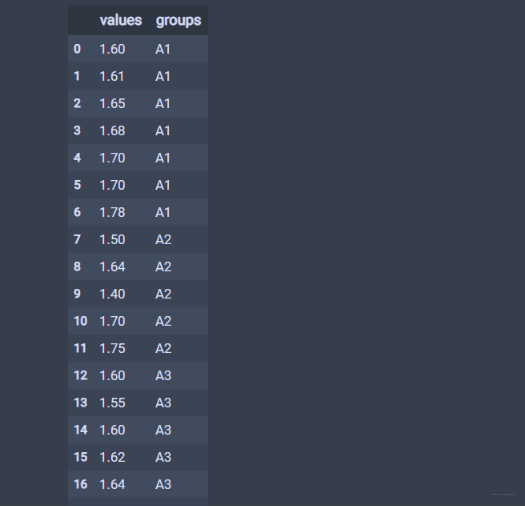
通过下面的方式做单因素方差分析:
anova_res = anova_lm(ols('values~C(groups)', df).fit())anova_res.columns = ['自由度', '平方和', '均方', 'F值', 'P值']anova_res.index = ['因素A', '误差']anova_res # 这种情况下看p值 >0.05 所以接受H0
结果如下:
# 数据格式张这样A1 = [1.6, 1.61, 1.65, 1.68, 1.7, 1.7, 1.78]A2 = [1.5, 1.64, 1.4, 1.7, 1.75]A3 = [1.6, 1.55, 1.6, 1.62, 1.64, 1.60, 1.74, 1.8]A4 = [1.51, 1.52, 1.53, 1.57, 1.64, 1.6]data = [A1, A2, A3, A4]from scipy.stats import shapirodef normal_judge(data):stat, p = shapiro(data)if p > 0.05:return 'stat={:.3f}, p = {:.3f}, probably gaussian'.format(stat,p)else:return 'stat={:.3f}, p = {:.3f}, probably not gaussian'.format(stat,p)for d in data:print(normal_judge(d))
结果如下:
stat=0.942, p = 0.660, probably gaussianstat=0.938, p = 0.655, probably gaussianstat=0.850, p = 0.096, probably gaussianstat=0.918, p = 0.489, probably gaussian
三、双因素方差分析及python实现
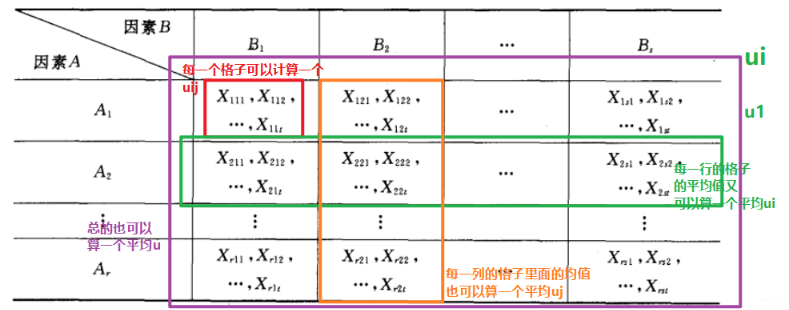
那么就开始引入一些新的公式, 因为既然每个格子里面有平均, 那么每一行的格子和每一列的格子也会有平均, 整体上也会有平均, 所以下面就定义三个公式:
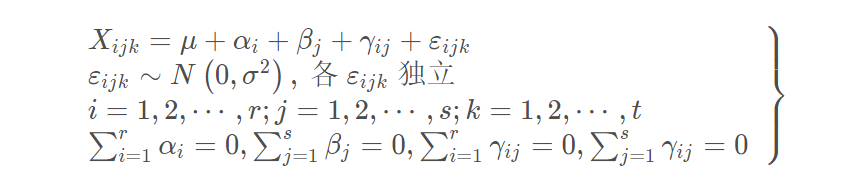
这个就是双因素试验方差分析的数学模型。对于这个模型, 我们就会有三个假设检验的问题了:
因素A对于试验结果是否带来了显著影响
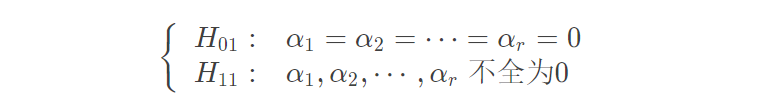
因素B对于试验结果是否带来了显著影响
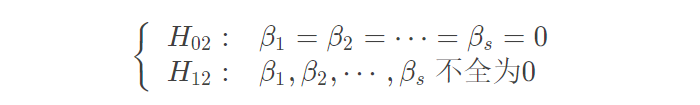
两者的组合对于试验结果是否带来了显著影响

与单因素的情况类似, 我们依然是采用平方和分解的方式进行验证。首先我们得先计算四个平均值:
因素A的水平因素B的水平的平均值:
因素A的水平上的平均值:
因素B的水平平均值:
总平均值:
有了上面的平均值, 我们就可以得到偏差平方和了, 总偏差平方和如下:

就得到了
这里也给出每个平方和的自由度,的自由度,?自由度是,?自由度是,?自由度,?自由度是。那么和单因素水平分析那样, 我们可以得到每个假设下面的拒绝域形式:

导入这次用到的包(依然是单因素分析时的ols和anova_lm)
import pandas as pdimport numpy as npfrom scipy import statsfrom statsmodels.formula.api import olsfrom statsmodels.stats.anova import anova_lm# 这三个交互效果的可视化画图from statsmodels.graphics.api import interaction_plotimport matplotlib.pyplot as pltfrom pylab import mpl # 显示中文# 这个看某个因素各个水平之间的差异from statsmodels.stats.multicomp import pairwise_tukeyhsd
3.1、无交互作用的情况
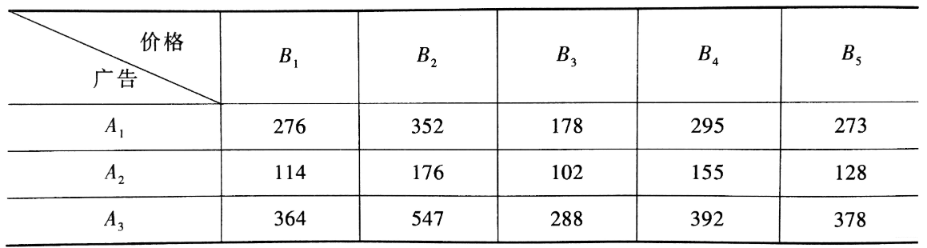
下面进行双因素方差分析,简要流程是,先用pandas库的DataFrame数据结构来构造输入数据格式。然后用statsmodels库中的ols函数得到最小二乘线性回归模型。最后用statsmodels库中的anova_lm函数进行方差分析。
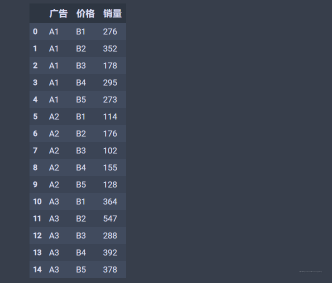
dic_t2=[{'广告':'A1','价格':'B1','销量':276},{'广告':'A1','价格':'B2','销量':352},{'广告':'A1','价格':'B3','销量':178},{'广告':'A1','价格':'B4','销量':295},{'广告':'A1','价格':'B5','销量':273},{'广告':'A2','价格':'B1','销量':114},{'广告':'A2','价格':'B2','销量':176},{'广告':'A2','价格':'B3','销量':102},{'广告':'A2','价格':'B4','销量':155},{'广告':'A2','价格':'B5','销量':128},{'广告':'A3','价格':'B1','销量':364},{'广告':'A3','价格':'B2','销量':547},{'广告':'A3','价格':'B3','销量':288},{'广告':'A3','价格':'B4','销量':392},{'广告':'A3','价格':'B5','销量':378}]df_t2=pd.DataFrame(dic_t2,columns=['广告','价格','销量'])df_t2
数据长这样:
# 方差分析price_lm = ols('销量~C(广告)+C(价格)', data=df_t2).fit()table = sm.stats.anova_lm(price_lm, typ=2)table
结果如下:
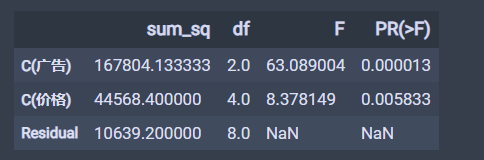
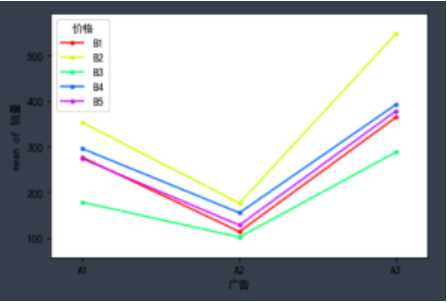
fig = interaction_plot(df_t2['广告'],df_t2['价格'], df_t2['销量'],ylabel='销量', xlabel='广告')
结果如下:
再来分析一下单因素各个水平之间的显著差异:
# 广告与销量的影响 注意这个的显著水平是0.01print(pairwise_tukeyhsd(df_t2['销量'],?df_t2['广告'],?alpha=0.01))?#?第一个必须是销量,?也就是我们的指标
结果如下:
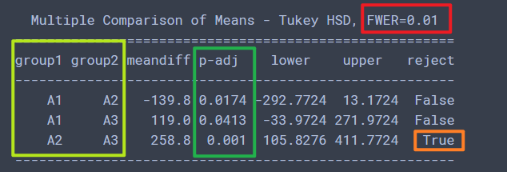
这个可以得到的结论是在显著水平0.01的时候, A2和A3的p值小于0.01, reject=True, 即认为A2和A3有显著性差异。
3.2、有交互作用的情况
由于因素有交互作用,需要对每一个因素组合??分别进行?次??重复试验,称这种试验为等重复试验。

dic_t3=[{'燃料':'A1','推进器':'B1','射程':58.2},{'燃料':'A1','推进器':'B1','射程':52.6},{'燃料':'A1','推进器':'B2','射程':56.2},{'燃料':'A1','推进器':'B2','射程':41.2},{'燃料':'A1','推进器':'B3','射程':65.3},{'燃料':'A1','推进器':'B3','射程':60.8},{'燃料':'A2','推进器':'B1','射程':49.1},{'燃料':'A2','推进器':'B1','射程':42.8},{'燃料':'A2','推进器':'B2','射程':54.1},{'燃料':'A2','推进器':'B2','射程':50.5},{'燃料':'A2','推进器':'B3','射程':51.6},{'燃料':'A2','推进器':'B3','射程':48.4},{'燃料':'A3','推进器':'B1','射程':60.1},{'燃料':'A3','推进器':'B1','射程':58.3},{'燃料':'A3','推进器':'B2','射程':70.9},{'燃料':'A3','推进器':'B2','射程':73.2},{'燃料':'A3','推进器':'B3','射程':39.2},{'燃料':'A3','推进器':'B3','射程':40.7},{'燃料':'A4','推进器':'B1','射程':75.8},{'燃料':'A4','推进器':'B1','射程':71.5},{'燃料':'A4','推进器':'B2','射程':58.2},{'燃料':'A4','推进器':'B2','射程':51.0},{'燃料':'A4','推进器':'B3','射程':48.7},{'燃料':'A4','推进器':'B3','射程':41.4},]df_t3=pd.DataFrame(dic_t3,columns=['燃料','推进器','射程'])df_t3.head()
结果这样:
下面是方差分析:
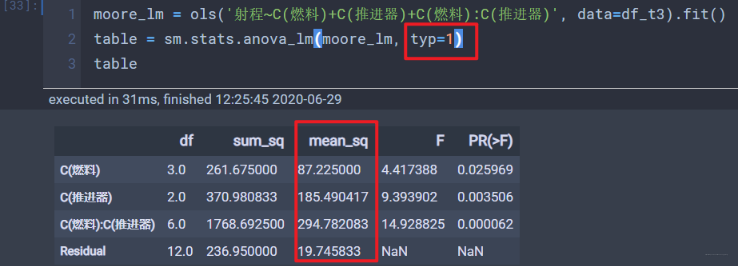
moore_lm = ols('射程~燃料+推进器+燃料:推进器', data=df_t3).fit()table = sm.stats.anova_lm(moore_lm, typ=1)table
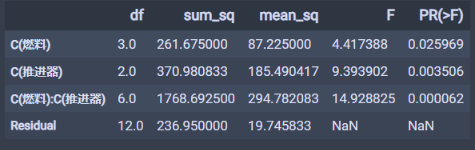
fig = interaction_plot(df_t3['燃料'],df_t3['推进器'], df_t3['射程'],ylabel='射程', xlabel='燃料')
结果如下:
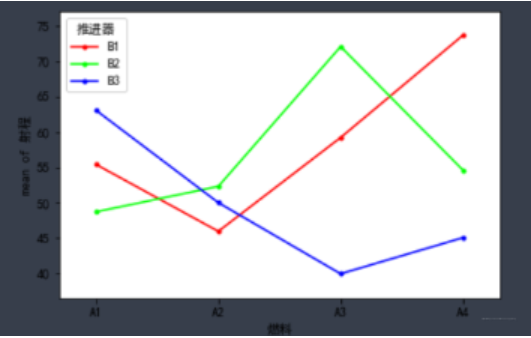
从这个图里面可以看出, (A4, B1)和(A3, B2)组合的进程最好。黄金搭档。单因素差异性分析:
print(pairwise_tukeyhsd(df_t3['射程'], df_t3['燃料']))结果:
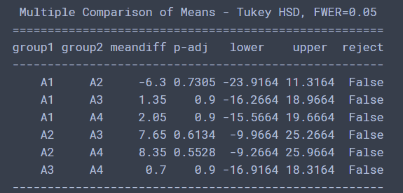
两个实验到这里就结束了, 这里再补充两点别的知识:
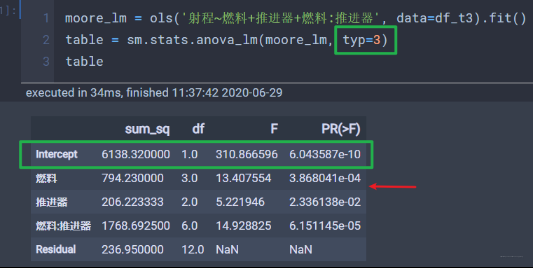
'射程~C(燃料)+C(推进器)+C(燃料):C(推进器)' :相当于射程是y(指标), 燃料和推进器是x(影响因素), 三项加和的前两项表示两个主效应, 第三项表示考虑两者的交互效应, 不加C也可。
'射程~C(燃料, Sum)*C(推进器, Sum)'和上面效果是一致的, 星号在这里表示既考虑主效应也考虑交互效应*'销量~C(广告)+C(价格)':这个表示不考虑交互相应
但是要注意, 考虑交互相应和不考虑交互相应导致的Se(残差项)会不同, 所以会影响最终的结果。
四、写到最后
方差分析这块到这里就结束了, 随着这篇文章的结束也意味着概率统计的知识串联也到了尾声, 简单的回顾一下本篇的内容, 这篇文章主要是在实践的角度进行的分析, 方差分析在统计中还是很常用的, 比较适合类别因素对于数值指标的影响程度:
首先从单因素方差分析入手, 这个只考虑了一个因素对于指标的影响, 先分析了原理,然后基于python进行了实现。实际应用中,一般是会点原理,然后使用工具实现方差分析,会看结果,这样就算入门了。
然后就是进行双因素方差的分析, 重点补充了带有交互效应的形式原理和python实现, 这样与文档形成一种互补。最后是带有交互和不带交互的双因素方差的实验。
实际应用中, 或许可以通过这种方法去分析类别特征的重要性或者关联性,以及类别和类别特征之间的交互作用等。
「完」

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675