无论在技术、产品还是生态上,百度Apollo自动驾驶不断在更新迭代。去年,百度在长沙宣布自动驾驶出租车队Robotaxi测试运营正式开启。今年开始,Apollo在长沙全面开放载人测试运营,目前覆盖的路网面积已达70公里,站点数量50个以上。与此同时,Apollo也发挥自身在自动驾驶车路协同等领域的核心优势,加速智能驾驶示范区建设。目前,他们完成了全国首例L3级别及L4级别的多车型高速场景自动驾驶车路协同演示。? 同时,Apollo生态联盟也在不断壮大,已拥有200+家生态合作方,囊括全球主流的整车、零部件、芯片、通信、出行、初创公司和科研公司,拥有40000多名全球开发者。Apollo已在不同场景落地,疫情期间生态合作伙伴的约100辆无人消毒车在17个城市运行。当然,这些成绩离不开技术积累。今年3月,根据《北京市自动驾驶车辆道路测试报告(2019年)》,百度在多个技术维度上获得第一。在牌照方面,百度是全国目前唯一获得T4驾考牌照的公司。而在自动驾驶专利上,百度的自动驾驶技术专利位列全国第一。那么,百度Apollo在核心技术上具体是如何更迭的?6月30日,在CSDN、百度APP、B站举办的《听大咖 讲论文》——Apollo自动驾驶专场上,百度技术工程师精选了3篇百度智能驾驶领域的年度优秀论文,为开发者揭秘百度Apollo背后的核心技术创新,内容涉及鲁棒LiDAR定位系统的定位模块、控制模块、自动驾驶预测技术等。这些技术为解决因施工修路造成的定位失败问题、车辆的动力学状态问题、周边行人车辆的预测问题,提供了更优越的思路。除此之外,他们还对自动驾驶技术的发展做出展望。王亮,博士,百度Apollo技术委员会主席、百度杰出研发架构师、百度无人驾驶环境感知方向技术负责人。丁文东,现任百度Apollo资深研发工程师,从事自动驾驶中地图构建、激光定位等方向的研发工作。许昕,现任百度Apollo资深研发工程师,园区无人驾驶方向核心开发成员。许珂诚,现任百度Apollo高级软件架构师,Apollo自动驾驶开源平台核心开发成员。以下为四位嘉宾演讲内容的要点摘选,由CSDN(ID:CSDNnews)整理:Apollo现在面临最重要的问题是实现“无人”,要验证商业化的成功,首先在技术上要把人去掉。为此,无人驾驶需要解决的核心问题:
同时,Apollo生态联盟也在不断壮大,已拥有200+家生态合作方,囊括全球主流的整车、零部件、芯片、通信、出行、初创公司和科研公司,拥有40000多名全球开发者。Apollo已在不同场景落地,疫情期间生态合作伙伴的约100辆无人消毒车在17个城市运行。当然,这些成绩离不开技术积累。今年3月,根据《北京市自动驾驶车辆道路测试报告(2019年)》,百度在多个技术维度上获得第一。在牌照方面,百度是全国目前唯一获得T4驾考牌照的公司。而在自动驾驶专利上,百度的自动驾驶技术专利位列全国第一。那么,百度Apollo在核心技术上具体是如何更迭的?6月30日,在CSDN、百度APP、B站举办的《听大咖 讲论文》——Apollo自动驾驶专场上,百度技术工程师精选了3篇百度智能驾驶领域的年度优秀论文,为开发者揭秘百度Apollo背后的核心技术创新,内容涉及鲁棒LiDAR定位系统的定位模块、控制模块、自动驾驶预测技术等。这些技术为解决因施工修路造成的定位失败问题、车辆的动力学状态问题、周边行人车辆的预测问题,提供了更优越的思路。除此之外,他们还对自动驾驶技术的发展做出展望。王亮,博士,百度Apollo技术委员会主席、百度杰出研发架构师、百度无人驾驶环境感知方向技术负责人。丁文东,现任百度Apollo资深研发工程师,从事自动驾驶中地图构建、激光定位等方向的研发工作。许昕,现任百度Apollo资深研发工程师,园区无人驾驶方向核心开发成员。许珂诚,现任百度Apollo高级软件架构师,Apollo自动驾驶开源平台核心开发成员。以下为四位嘉宾演讲内容的要点摘选,由CSDN(ID:CSDNnews)整理:Apollo现在面临最重要的问题是实现“无人”,要验证商业化的成功,首先在技术上要把人去掉。为此,无人驾驶需要解决的核心问题:- 智能性。在无人情况下,把乘客安全的从A点送到B点,而现在有人类司机的环境下存在一些搏弈需求,要完成这一点非常困难。
- 成本。为什么成本非常重要?因为智能化到了一定程度,就需要一定的规模去验证整个系统的安全性,如果没有很有竞争力的成本,很难把规模提上去。
- 安全性。要把人去掉,要有足够信心达到何种安全标准,比人类司机好多少倍,我们才敢做这样一件事情。
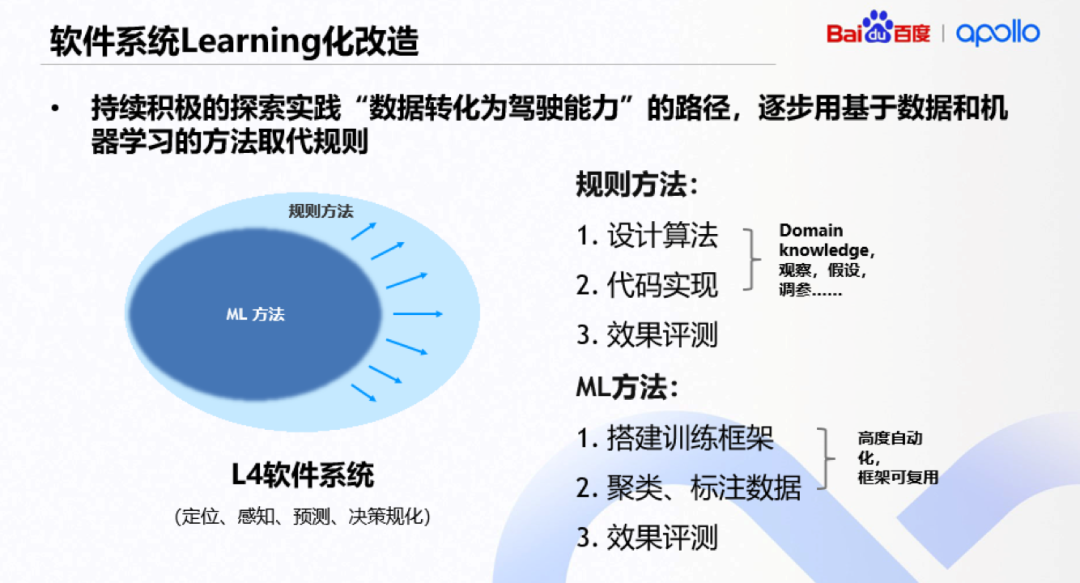
首先是整车软件系统Learning化的改造。虽然很多规则类方法能够快速收敛路上的问题,然后积累里程,迭代系统,但后期会发现很多问题不容易解决。所以会逐步用基于数据和机器学习的方法,取代现在很多系统中使用的规则方法、基本假设和参数。机器学习方法带来了新的研发思路。要搭建一个高度自动化、可复用的训练框架,在遇到问题时,不再通过观察和假设去写代码,而是通过机器学习训练框架编写规则和参数。而在寻找数据驱动路径上,我们搭建了规模化机器学习系统,实现数据闭环。换句话说,利用数据,高效消化规模化测试中产生的海量数据,反哺车端的算法,让无人车愈加聪明。最后,说一下自动驾驶仿真体系的链路,我们目前也有非常完备的仿真评估体系,比如在上车之前,基本对新版本的能力会有非常准确和充分的预期,上路之后得以最大程度保证安全,也能非常有效地提升迭代效率。这个工作的目的是通过LiDAR全局匹配和LiDAR关键里程的互补信息,使定位系统更加鲁棒和准确,进一步解决那些由于施工修路等造成定位系统失效的问题,并且对环境变化进行检测,以便进行定位地图的更新。无人车的定位需要做到全天候24小时稳定并且准确地运行,这是一个比较有挑战的任务。为了完成这个任务,单一传感器很难做到。Apollo的车上装了多种传感器,包括GPS、IMU、相机和LiDAR,分别有一些优缺点,使用并且融合它们会让定位系统更加容易实现全天候24小时稳定准确地运行。对于LiDAR定位来讲,仍然存在挑战场景,包括季节变化、拥挤道路、道路施工、下雪、雨天都会使当前LiDAR定位更加困难。具体需要克服环境变化,避开动态障碍物的影响,并且能够确定我们应该在什么时候、在哪里更新地图,这对无人车商业化部署都很重要。这篇文章的主要动机是基于现在定位的方式,包括MapMatching和Odometry,它们具有一些特性。对于MapMatching来说是一种定位问题,Landmarks对定位做修正,可以根据IMU或者轮速计递推到上图中虚线圈的位置;对于Odometry来说,是一个同时定位和建图的过程。同样,对于当前的无人车,我们通过IMU和轮速计递推到虚线的位置,这里同时兼着一个虚拟Landmarks,通过同时优化Landmarks Poses,能够得到修正后的Poses Landmarks。另外,我们还可以从图模型上对比两个问题,对于MapMatching来讲,假设地图作为已知,根据一些输入和观测量估计定位的位置;在Odometry中,地图和车辆的位置是未知的,所以对应的概率M移到了前面。从地图对比来看,Map Matching依赖的地图是全局的;Odometry构建是局部的,里面包含Landmarks,新的LIDAR数据在两个模块内分别对应自己的map做matching。地图匹配和Odometry具有互补特性。一方面,Landmarks Odometry对环境变化和地图失效是鲁棒的,不依赖于预先构建的地图;另一方面,地图匹配提供全局已知并且不会漂移的定位估计,但是地图是实时更新的。总而言之,我们在定位系统中完成它们的融合,会得到更加稳定的定位系统。我们的定位系统包含四个模块:LiDAR INERTIAL Odometry(LIO),LiDAR Global Matching(LGM),Pose Graph Fusion(PGF)和Environmental Change Detect(ECD)。通过LIO的辅助,运用图优化的融合框架,融合了LIO和LGM的结果,实现鲁棒的定位系统,这样使自动驾驶系统能够更好应对不断变化的城市场景定位的挑战,这是主要的影响。而车辆定位的框架,联合全局匹配和局部LIO信息,也能减少受城市变化场景的影响。另外,可以构建紧耦合的LiDAR惯性数据,结合删格数据和LiDAR反射值,进行实时准确的状态估计。鲁棒的定位系统经过了拥堵并且繁忙城市里的每日例行测试,已证明这套系统具有在挑战性环境和动态变化环境中运行的稳定性。https://pdfs.semanticscholar.org/052c/9087a09e9e0bfe739cee9cf704753c2cd44f.pdf控制模块是直接跟车打交道的,它的跟踪精度以及对各工况的适应能力,是自动驾驶中非常重要的一部分。这篇论文主要介绍了如何在不需要获取一些车辆参数,比如发动机参数、轮胎参数的情况下,而且在比较剧烈的载重变化情况中,算法如何识别并适应这种变化。本文说的是物流小车怎么解决载重变化造成状态变化的开发与测试。在这个场景下,空载情况下整车重量是300千克,满载情况下可以达到660千克,载重变化超过1倍。在这种情况下,如果说控制模块无法适应这种载重的变化,在一些指标上,比如未知误差和速度误差就会有比较大的下降,直观来说是车辆的控制性能会下降,可能空载时候跑得挺好,满载的时候速度上不去,该刹的时候刹不下来。本文专门针对这个场景,在不要求额外配置专用传感器的前提下,以及不要求一些车辆参数的背景下,开发了能够适应明显车辆载重变化的控制算法。传统上,采用的方法多以动力学建模为主,根据我们的经验,像重卡这种载重可以超自重几十倍的案例,传统的方法也可以在数分钟内就完成标定。只是用动力学建模的方法,需要用户对动力总成系统比较熟悉,而且需要实时获取比较底层、关键的车辆参数。但很多时候开源社区的用户可能对动力总成系统并不熟悉,或者因为商业合作关系没有办法从OEM拿到比较底层的车辆参数。我们的方法是将车辆纵向动力系统作为一个黑箱对待,不试图对其进行建模,只要发现速度、加速度、油门、刹车对应不上,就把能对应的地方进行调整。这可以类比成梯队下降的方式,当然,我们是没有模型的,所以也不是真正的梯队下降。在物流小车这个特定场景里,我们也提供了这种方法的路车数据,想在该场景下研发的社区用户也可以参考这些数据。对于未来在这个方向上的探索,我们认为大家可以关注如何用类似的思维,去进一步解决在路上遇到的道路坡度、风阻等问题。此外,横纵向同时能够标定的话可以达到更加精确的性能,我们目前的做法是横、纵向分开标定的。比如除了纵向隔离方法之外,我们也使用了横向自动标定的方法,而且单独标横向的话,我们测试方法中收敛的时间大概是几秒钟。但是我们认为未来在一些比较复杂的路况,比如高速或者复杂工况下,如果能够实现横纵向联合标定的话,可能控制性能会更好。https://arxiv.org/abs/1808.10134许珂诚:数据驱动的自动驾驶预测架构及其在Apollo平台上的应用百度Apollo在创新性、实用性和规模化方面都有很深厚的工作积累,我们的预测模块已能够实现一套全自动化、跨区域、规模化部署的解决方案。预测技术作为自动驾驶中一个承上启下的关键组成部分,近两年受到学界和工业界的认识,有许多优秀论文在算法创新上做了很多工作,对于特定问题也有比较好的效果提升。但针对日益强烈的跨区域规模化发展需求,鲜有论文提出完整解决方案。第一,模型跨区域部署。大部分预测模型都是从实际路测中学习,从原始数据到模型的端到端过程包含很多道工序。当我们在往跨区域规模化方向发展,需要源源不断收集新的区域数据来强化模型,一个能打通线上线下、具备高度自动化的数据流水线非常必要,这篇论文其中一部分内容就是介绍Apollo的预测模型如何设计这个方案。第二,对于一些线上方法不可避免地有一些参数需要调整。有些参数是为了适应某个地区的交通状况,到了新的区域就需要重新调试,传统人工调试方法显然不能满足规模化发展要求,因为参数调试需要耗费人力和时间。对于这个问题,解决方法是数据驱动的自动化调参机制。第三,线上计算耗时高。现在许多工作优化预测模型有很好的表现,但模型都相对比较复杂,实际应用中有比较高的耗时。在Apollo开源平台,我们通过工程化的优化,把一些复杂模型计算耗时限制在了可接受的范围之内。这是Apollo预测模块的整体框架。其中两个重要的算法内容:一个是语义地图在Apollo平台的部署中用于轨迹点预测,另一个是预测模型之后的轨迹点生成方法以及它的自动调参机制。
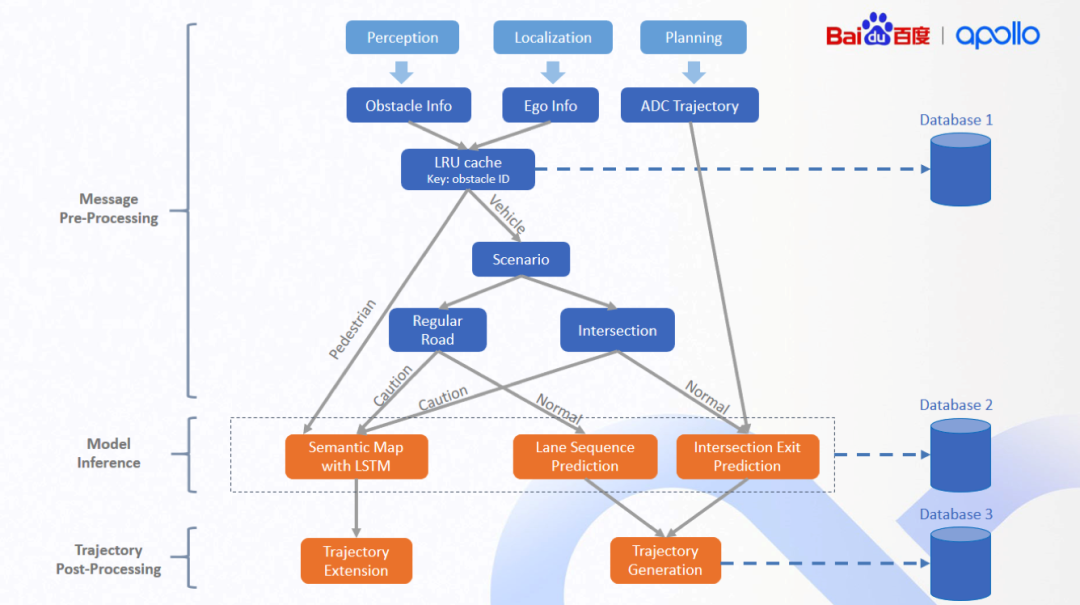
在模型部署方面,我们会给优先级较高的障碍物运用语义地图和LSTM等模型直接预测轨迹点,这是近两年研究使用较多的建模方法,它可以通过图片方式兼顾静态地图信息和动态交互信息。不过,因为涉及语义地图绘制以及模型中包含对图像CNN网络处理,所以耗时会比较高,实际运营中部署难度比较大。百度Apollo平台从工程上进行优化,成功部署了这个模型,通过在加州两个不同城市测试结果来看,模型表现非常稳定,验证了这套架构具有快速跨区域部署的能力。此外,出于效率考虑,我们只对caution级别的障碍物运用这样的模型,对于其他普通优先级的障碍物,我们会根据场景来预测相应行为,并且根据预测出来的行为生成合理的轨迹。总结一下,我们的目标是让预测技术能够实现快速高效的跨区域部署,为此设计一套全自动数据流,高效并且能够保持线上线下一致性。另外,我们还有两个算法层面的应用,一个是基于地图轨迹预测的模型部署,另一个是轨迹生成方法中数据驱动的自动调参机制。https://arxiv.org/abs/2006.06715


更多精彩推荐
?Python 编程语言的核心是什么?
?英伟达 VS. 英特尔:后浪来袭!
?B 站 Up 主自制秃头生成器,独秃头不如众秃头?
?干货!仅有 100k 参数的高效显著性检测方法
?看完这篇 HashMap ,和面试官扯皮就没问题了
?密码学应用的四个进化阶段 | 博文精选
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






















![玥宝_aikk2024如约而至[送花花] ](https://imgs.knowsafe.com:8087/img/aideep/2024/1/16/8f4c9115b8b8de6905897d2a621b73de.jpg?w=250)




 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




