
想让周杰伦唱《一剪梅》?这个能编曲的AI或许可以做到。

美国的歌手,作曲家,作词家或许都要失业了,本就不富裕的家庭又蒙上了一层寒霜。而这一切都因为一台 Jukebox(?自动点唱机?)。

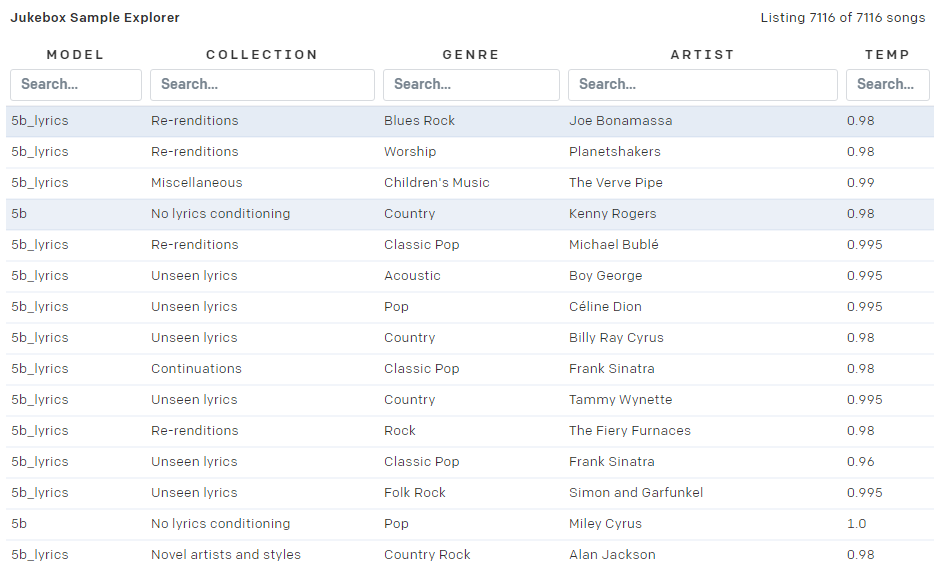
不好意思放错图了,是这个 Jukebox!

4 月份的最后一天,OpenAI( 旗下的 OpenAI ?Five 成功在 DOTA 比赛中击败职业选手?)发布了自己的新产品 Jukebox(?自动点唱机?)。
对于国人来说?Jukebox?这个名字可能比较陌生,但在美国的 40?到 60?年代可谓是风靡一时。在那段时间,每个大型的酒馆或者娱乐场所都会放置一台自动点唱机,只有投入硬币,就可以选择自己想要听的歌曲。

同样的,在 OpenAI 的新产品之中,只要你输入流派、歌手和歌词,它就可以自动演唱歌曲,甚至还能创造出全新的从未存在过的音乐。
打个比方来说,你可以让 Jukebox 用费玉清的声音用五月天的风格演唱着周杰伦的《 晴天 》,又或者是让马老五( maroon 5 )的主唱亚当用说唱的风格演唱泰勒?·?斯威夫特的《 Love story 》。
这一切简直太 Awesome 了!!简直震惊世超。
事实上,Jukebox 并不是人类第一款可以自动生成音乐的 AI,自动音乐的历史可以追溯到半个世纪以前,只是之前的产品都没有像 Jukebox 那样全能。
在 Jukebox 之前,人们曾经创造过能出生成钢琴乐谱的算法,能生成歌手声音的数字解码器,以及能够模拟各种音色的合成器,后来又演变出各种各样的虚拟歌姬。
初音未来(?日本 VOCALOID 虚拟歌手?),她可以唱歌,但是不能创造音乐。▼

但是无论是钢琴谱,又或者是虚拟歌姬,他们能做到到也只有单一的变化,如果要求他们制作一手复杂的交响乐,那实在是太困难了。
突破是来自法国科学家 Pierre Barreau 和他的团队,在经过一番努力之后,他们联手推出了能够独立演奏古典音乐的 AIVA。

Pierre Barreau 个人简介,长得又帅,成就又高,着实令人羡慕了。▼

基于深度学习技术,AIVA 可以学习莫扎特、巴赫、贝多芬等名家作品,制作出自己对音乐理解的数学模型,从而能够站在大师的肩膀上演奏或者创造新的音乐。
AIVA 能做到哪一步呢,将 AIVA 创造的音乐和其他作者的音乐混合在一起,即便是专业的音乐家也无法听出区别。

而在 2017 年 3 月,AIVA 还成为?“?法国及卢森堡作曲家协会?”( SACEM )的首个非人类会员。
而在 6 月的卢森堡国庆日庆典开幕上,AIVA 还登场弹奏了自己创造的 Let’z make it happen 。
这着实令人羡慕了,毕竟这是很多音乐人终其一生都难以达成的成就。
AIVA 已经很强大了,但是还不够强大,科学家的野心不满足于只能创造交响乐,他们还想要更多,想要流行音乐,要让 AI 能够像人一样演唱。
但是想要完成这个任务可不容易,接力棒早早就放在那里,数年间一直无人来取。
直到一位猛男的出现,而这个猛男,恰巧就是 Jukebox!

想要达成这个成就。第一步,就需要我们把现实中的音乐转换为电脑中的数字信息,好在音频数字化技术早已成熟,如今天天用手机听歌的我们不用太费心思。
真正的难题在于一首流行歌曲中同时存在着多种因素,比如打击乐器发出的低频音、中高频的乐器声、以及歌手本身的声音,所有的声音混杂在一起。
在这种情况下,如果想要?AI?像人一样演唱,就需要先把这些声音分离然后再重新组合在一起。
这并不是一个简单的问题。为了解决这个问题,研究人员的头顶日渐稀薄。
开始时,他们尝试了许多方法都失败了,直到有人从隔壁的图形分层 VO — VAE 技术中获得了灵感,使用新的 VQ — VAE 模型才取得新的突破。

而这个VQ—VAE模型呢,也不是一件简单的事情。
研究人员需要从 3 个不同的层次对音乐进行数字建模,但是在每一层会使用不同的编码精度,比如顶层会采用 128 倍压缩倍率保留最基本的音乐信息。而底层则采用 8 倍争取保留最多的音乐细节。
在生成音乐时,一系列的转换器会从上到下生成代码,然后,凭借下层的解码器就可以将它们生成新的音频。

这样还是有点抽象,让我们换一种方式表达。
你可以想象我们现在要临摹一副画卷。但是不直接临摹。首先我们去制作不同层次分层图,也就是要在三张纸上分别临摹原画卷的某一部分。
第一张记录轮廓信息(?音乐的风格,特色,旋律等?),第二,第三张纸则记录尽可能多的色彩、阴影信息等(?歌手的音色,乐曲的音质?)。
这样我们就得到了三张分别记录不同层次信息的临摹作品,只需要把三张作品叠在一起就可以得到一副精度不是那么高的仿图。
这个过程类似纸雕作品,通过雕刻不同的层次细节,再利用光影就可以实现令人惊艳的效果。

图源网络
进一步来说,如果我们临摹的作品足够多,那我们能够得到的层次图就越多。
这下只要将不同层次的分层图合并在一起,就能够创造出之前不存在的作品。
这也是 Jukebox 能够用费玉清的声音,五月天的风格唱周杰伦的《?晴天?》的原因。

就如同前文所说,借助这样的算法,再辅以大量的高精度歌曲进行训练之后,Jukebox 就可以创造新的音乐了。
等一切都成熟之后,用户就可以通过输入想要的流派、艺术家和歌词,获取全新的音乐。
而?Jukebox 团队也在官网上放出了不少已经创造好的作品。?
第一耳听感,仿佛就是歌手原声一样,但是由于经历过多次压缩,导致声音细节损失严重,导致听起来像是隔着一层厚厚的罩子,含混不清。网友们戏称这是歌手酒醉之后的 KTV 版本。
尽管歌曲清晰度不高,依然可以明显感受到歌手的风格,甚至非常小的细节,Jukebox 也能够完美的还原。
AI 似乎太强大了,强大到让人害怕。
回到文章最初,这么强大的 AI 真的会导致歌手,作曲家,作词家失业吗?
在回答这个问题之前,我想向你们推荐一首歌曲的现场 —— 中岛美嘉《?曾经我也想一了百了?》。
这是中岛美嘉演唱会的结尾曲,当时的她,正饱受病痛折磨,双耳几近失聪。演唱过程中,甚至于一度听不清曲子的鼓点。为了找到节奏她只得跪下身子,将手覆在音响之上用手掌感受节奏。

这是一首不完美的歌曲,因为节奏的混乱,中岛美嘉有多处地方都出现了破音,跑调,但是依然被观众评选为演绎的最完美的版本之一。
同样的,在 2010?年 DUO 演唱会时,陈奕迅在演唱《?浮夸?》时也是几度破音,现场版和专辑里面差别很大,但是也同样被评为陈奕迅的最佳现场之一。

又或者像是 Queen 乐队在舞台上和 6 万多人一起合唱,台上台下心意相通的时刻,这些都是 AI 永远无法替代的瞬间。

就如同许多人说过的那样,听音乐一定要听现场版。当我们在参加演唱会的时候,不仅仅是在听歌手演唱,也是在看歌手在舞台上的表演。
音符、旋律、时间。。。数学家们能从理论上能证明音乐是可以被穷举的。而对于排列组合这种有规律的事儿,AI 可太擅长了。
但是,作为表演艺术的一部分,歌手的演出并不是简简单单用旋律就可以定义的。
中岛美嘉在演唱时对生命的呼唤,陈奕迅在演唱《?浮夸?》时都痛苦的演绎,和分手后的歇斯底里,乃至于 queen 的万人大合唱,它们都是独一无二的,是人类在音乐史上的闪光点。
它们所展现的灵光和带来的感动是人类独享的。
规则让 AI 拥有了执行创作的能力,但是握着能打开创造世界大门的钥匙的一直都是人类。


关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 差评
差评
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675