
模型也可以上网课?!一文看懂服务型蒸馏训练方案
允中 发自 凹非寺
量子位 编辑 | 公众号 QbitAI
自今年年初,由于疫情的原因,为了减少人员聚集,降低病毒扩散的可能性,各大中小学校都陆续开始了网上教学。上网课已经成了家喻户晓的一种学习方式了。
可是你知道吗,在深度学习领域,模型训练也是可以采用网课形式,不用那么震惊,这个真的有!这就是今天要讲的LF AI基金会的EDL项目基于飞桨深度学习平台推出的服务型蒸馏训练方案!

什么是蒸馏训练?
要讲蒸馏训练就要提到知识蒸馏。如今深度学习模型正在往越来越大,网络层越来越深的方向发展。在很多场景下,模型越大,层数越多,模型效果就越好。但受限于推理速度,显存资源等要求,大模型通常无法直接部署,需要对模型进行压缩。
目前主流的压缩方法有裁剪、量化、知识蒸馏等。其中知识蒸馏这一概念是由Hinton等人在2015年发表的《Distilling the Knowledge in a Neural Network》论文中提出的一个黑科技,一种非常经典的模型压缩技术,是将知识从一个复杂模型(Teacher)迁移到另一个轻量级模型(Student)上的方式来实现模型压缩。
其实所谓知识的迁移,其实可以理解为一种训练过程,就是使用Teacher模型来训练Student模型,这种训练方法就是蒸馏训练。在训练出一个效果良好的Student模型后,这个Student模型就可以被用于实际部署了。
如下图所示,训练步骤可以分为两步:
训练好一个Teacher模型。
训练Student模型,即使用Teacher模型的知识来训练Student模型。

△知识蒸馏架构图
所谓Teacher模型的知识是指Teacher模型的推理结果,我们称之为soft label,这个soft label将作为Student网络的训练目标,Student的推理结果需要尽可能接近Teacher的推理结果。与soft label相对应的是hard label,hard label就是真实训练数据的标签。相比于hard label,soft label所含的信息量更大。
举个例子,比如做区分驴和马的分类任务的时候,soft label不会像hard label那样只给马的index值为1,其余类别为0,而是在驴的部分也会提供一个概率值(例如0.3或0.4之类),这样的优势在于使soft label包含了不同类别之间的相似性信息。显而易见,使用soft label训练出来的模型肯定要比单独使用hard label训练出来的模型学习到更多的知识,也就更加的优秀。
知识蒸馏训练的目标函数可由distillation loss(对应teacher soft label)和student loss(对应标注的hard label)加权得到。公式如下,其中p表示Student模型的推理结果,q为teacher的推理结果,y为hard label。
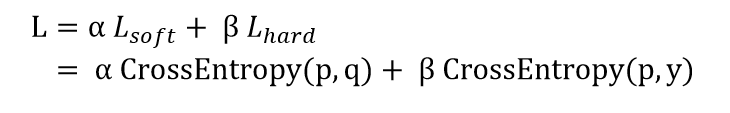
什么是服务型蒸馏训练?
说完蒸馏训练了,下面我们进入正题,来看看我们这个服务型蒸馏训练到底是个什么东东!蒸馏训练可以分为如下三种方式:
离线蒸馏训练
离线蒸馏训练的方式很像是老师(Teacher)把要讲课的内容录制成视频交给学生(Student)去自学,然后学生根据课程视频自学成才。所以离线蒸馏训练就是先使用Teacher模型做推理并将结果保存在磁盘中,然后Student模型使用磁盘中保存的样本和Teacher模型的推理结果作为数据集进行训练。这种训练方式下Student模型训练和常规训练一致,方法简单。不过这种训练方式一般需要数据增强,而且需要占用巨大的磁盘空间,因此应用环境受到了一定的限制。
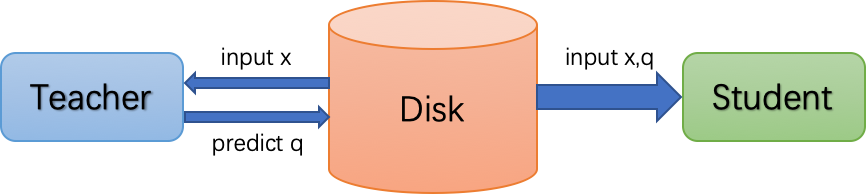 △?离线蒸馏训练
△?离线蒸馏训练
常规蒸馏训练
常规蒸馏训练是指将Teacher模型和Student模型放入同一网络中,固定Teacher模型参数只做前向,Student模型则正常做反向传播训练。这也是目前主流的蒸馏训练方式。这和现实生活中常规的教学方式很像,老师和学生在一个教室里,老师说一句,学生听一句。但是这种训练方式不仅Teacher模型本身需要占用较大的空间,而且由于Teacher和Student是1对1的绑定关系,Student模型的训练完全依赖Teacher模型,Student模型要等Teacher模型输出一个batch的推理结果才可以训练,而teacher模型也要等Student训练完一个batch,才能开始下一个batch的推理,对整体的训练速度有一定的影响。
服务型蒸馏训练
服务型蒸馏训练是基于EDL(Elastic Deep Learning,弹性深度学习框架)提出的一种训练方案。EDL是Linux基金会(LF)旗下负责人工智能和大数据深度学习领域的基金会LF AI正在孵化的重要项目之一。如今在云计算资源蓬勃发展的条件下,利用弹性资源进行深度学习模型训练和推理将成为一种普遍现象,因此EDL项目应运而生。EDL项目可以使云上深度学习模型的训练和推理变得更容易和更有效。而服务型蒸馏训练方案就是EDL项目结合百度飞桨开源深度学习平台而推出了一种新的训练方案,可谓出身名门!

与常规蒸馏训练相比,服务型蒸馏训练将Teacher模型和Student模型解耦,Teacher模型被部署为线上推理服务,Student模型则以客户端的身份通过互联网实时发送样本到Teacher模型获取推理结果进行训练,这就如同让模型上网课。那么让模型上网课可以给用户带来什么收益呢?咱们往下看!

△?服务蒸馏训练
服务型蒸馏训练的价值
相比于常规的蒸馏训练模式相比,服务型蒸馏训练可以给用户带来如下收益:
节约显存资源。由于Student模型和Teacher模型的解耦,所以服务型蒸馏训练可以使用异构的资源,也就是把Student模型和Teacher模型的部署到不同的设备上。原先受限于显存大小而难以部署到单个GPU卡上的蒸馏网络可以通过该方式部署到不同卡上。
提升训练速度。由于节约了显存资源,这样就可以使Student模型能够训练更大的batch size;同时由于Student模型和Teacher模型是异构流水线,Student模型不用等Teacher模型推理结束后再训练,综合上述两个原因,可以大大提高训练速度。
提高训练资源利用率。在实际应用中,我们可以将Teacher模型部署到线上的弹性预估卡集群,利用线上预估卡闲时的算力资源提升蒸馏任务中Teacher模型侧的吞吐量。同时由于Teacher模型可以弹性调度,不用担心高峰时线上实例被抢占造成的任务失败。相当于把teacher对训练卡的资源需求转移到了在线GPU卡上,在v100等离线训练资源受限的情况下,使用在线卡对训练进行加速,以节约宝贵的训练资源。
此外,在离线集群上,结合调度策略,还可以将Teacher模型部署到集群碎片资源,或者如k40等使用率较低的资源上,充分利用集群的空闲、碎片资源。
提升训练效率。用户可以根据Teacher和Student的吞吐性能灵活设置Teacher和Student的比例,也就是说多个老师可以教多个学生,而不是只能保持1比1的家教模式,最大限度地提高训练的产出。
为了验证服务型蒸馏训练的效果,我们在ImageNet数据集上使用普通训练、常规蒸馏训练和服务型蒸馏训练几个不同方式来训练ResNet50_vd模型。

在精度上,可以看出相比于普通训练,蒸馏训练提升了ResNet50_vd模型近2%的精度。而服务型蒸馏训练和常规蒸馏训练在精度上持平。当然该模型的蒸馏精度远不止于此,关于知识蒸馏更多提升精度的技巧请参考如下地址:
https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/distillation/index.html
在速度上,相比于普通训练,常规蒸馏训练由于Teacher模型占用了很大一部分算力,所以在相同训练资源的情况下,训练速度仅为普通训练的35.9%。而服务型蒸馏训练由于使用了额外的在线P4弹性资源,将Teacher对训练卡的资源需求转移到了弹性卡上,所以相比于普通训练,仍保持有82.8%的训练效率,速度为常规蒸馏训练2.3倍。
如果继续增加Teacher资源,理论上EDL服务型蒸馏训练的速度是可以和普通训练速度持平的。当然常规蒸馏训练如果加大资源,也是可以继续加速的,不过这样就占用了更多宝贵的v100训练资源了。
服务型蒸馏训练既然那么厉害,那它是怎么做到的呢?咱们来看看它的具体实现。
服务型蒸馏训练的实现方案
从具体实现的角度看,服务型蒸馏训练之所以被称为服务,就是因为它将Teacher模型部署成了服务端,而Student模型成了客户端。如下图所示,该方案可以描述为将Teacher模型被部署为在线可容错弹性服务,而在Student模型一侧则通过DistillReader来封装Student模型与Teacher模型之间的通信,访问Teacher服务。下面咱们分别介绍下DistillReader和可容错弹性服务都是啥?
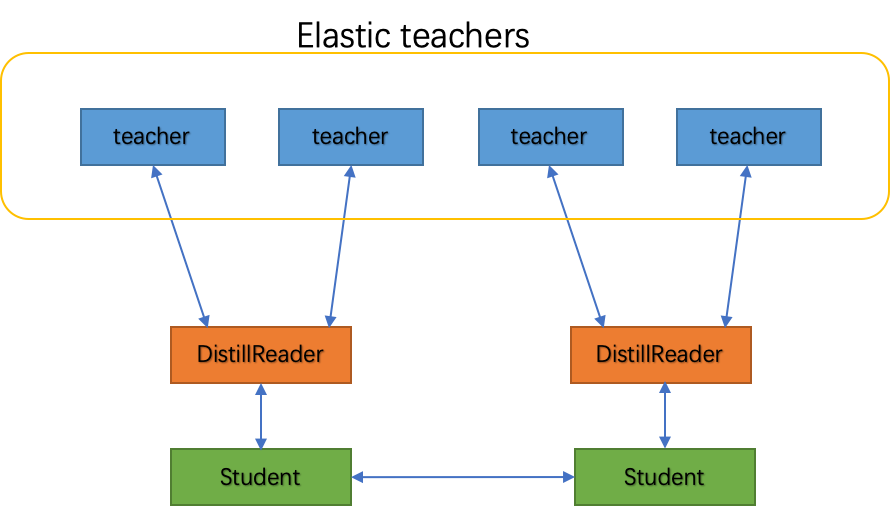
△?服务型蒸馏训练架构图
DistillReader
DistillReader用来代表Student模型向Teacher模型进行通信,从而产生可供Student模型训练的数据reader。如下图所示,Student模型将训练样本和标签传入训练reader,DistillReader从训练reader中读取训练样本发送给Teacher模型,然后获取推理结果。推理结果和原训练reader中的数据封装在一起,返回一个包含推理结果的新reader给Student模型,这样TEACHER模型的推理和STUDENT模型的训练就可以流水行并行起来了。
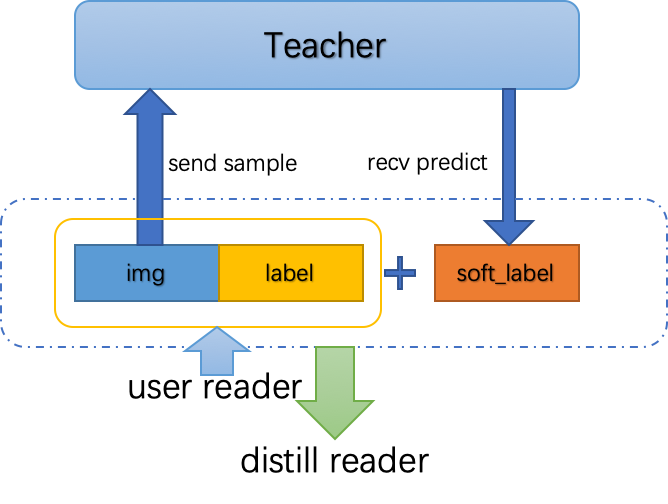 △?DistillReader功能示意图
△?DistillReader功能示意图
可容错弹性服务
可容错弹性服务的实现架构如下图所示,首先我们通过Paddle Serving将多个Teacher模型部署成服务,并注册服务到Redis数据库中;Student模型则作为客户端从服务发现中查询所需的Teacher服务;服务发现从Redis数据库查询并按某种负载均衡策略返回客户端所需的Teacher列表;每当Teacher变化时,客户端就可以实时拿到最新Teacher列表,连接Teacher进行蒸馏训练,不用担心发生由于连接到被收回的Teacher资源而导致任务失败的请况。
 △?弹性伸缩服务架构图
△?弹性伸缩服务架构图
如下图所示,该图是服务型蒸馏训练运行的流程图,图中可以看到STUDENT模型给TEACHER模型发送样本并获取推理结果,而TEACHER模型服务侧则可以随意增删,弹性调整。
 △?服务型蒸馏训练流程图
△?服务型蒸馏训练流程图
在了解了实现方案后,那么怎么使用服务蒸馏训练呢?下面我们通过一个操作示例为大家简单介绍一下。
服务型蒸馏训练实践
我们通过训练图像分类模型来给大家演示下如何使用服务型蒸馏训练。由于仅是演示,这里我们使用的是单机环境,也就是说服务端和客户端部署在了同一个服务器上,服务端的IP地址是127.0.0.1。如果部署在不同设备上,修改下代码中的IP地址即可。
环境准备
请执行如下命令拉取镜像,镜像为CUDA9.0的环境,在里面我们预装了EDL、飞桨核心框架和Padde Serving等相关依赖。
docker?pull?hub.baidubce.com/paddle-edl/paddle_edl:latest-cuda9.0-cudnn7
nvidia-docker?run?-name?paddle_edl?hub.baidubce.com/paddle-edl/paddle_edl:latest-cuda9.0-cudnn7?/bin/bash
启动Teacher模型
请执行如下命令在1号GPU卡启动Teacher服务,其中Teacher模型为图像分类模型ResNeXt101_32x16d_wsl,服务的端口号为9898,并启动了内存优化功能。
cd?example/distill/resnet
wget?--no-check-certificate?https://paddle-edl.bj.bcebos.com/distill_teacher_model/ResNeXt101_32x16d_wsl_model.tar.gz
tar?-zxf?ResNeXt101_32x16d_wsl_model.tar.gz
python?-m?paddle_serving_server_gpu.serve?\
??--model?ResNeXt101_32x16d_wsl_model?\
??--mem_optim?True?\
??--port?9898?\
??--gpu_ids?1
启动Student模型训练
请执行如下命令在0号GPU卡启动Student模型,启动的student模型为ResNet50_vd,。
python?-m?paddle.distributed.launch?--selected_gpus?0?\
??./train_with_fleet.py?\
??--model=ResNet50_vd?\
??--data_dir=./ImageNet?\
??--use_distill_service=True?\
??--distill_teachers=127.0.0.1:9898
其中train_with_fleet.py是用于启动训练的脚本,用户需要在其中添加蒸馏训练相关的代码,如果用户想了解脚本的修改方法或可以参考如下地址。
https://github.com/elasticdeeplearning/edl/blob/develop/example/distill/README.md
以上就是本文介绍的所有内容了。如果在使用过程中有问题,或者有什么好的建议,欢迎在EDL代码库提ISSUE。
传送门
EDL项目地址:https://github.com/elasticdeeplearning/edl
如果您加入飞桨官方QQ群,您将遇上大批志同道合的深度学习同学。官方QQ群:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:https://www.paddlepaddle.org.cn
飞桨Paddle Serving项目地址:
GitHub:https://github.com/PaddlePaddle/Serving
Gitee:?https://gitee.com/paddlepaddle/Serving
飞桨开源框架项目地址:
GitHub:?https://github.com/PaddlePaddle/Paddle
Gitee:?https://gitee.com/paddlepaddle/Paddle
— 完 —

量子位?QbitAI · 头条号签约作者
?'?' ? 追踪AI技术和产品新动态
喜欢就点「在看」吧 !
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 量子位
量子位
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675