作者:Thomas Gey ?翻译:廖倩颖 ?校对:和中华本文约2300字,建议阅读5分钟。
探索性数据分析已失势,Pandas-profiling万岁!用更省力的办法完美呈现你的数据。
?
在大部分数据科学领域中,我们获得的数据并不如网上专门为机器学习模型的应用而设计和准备的数据干净和完整。大部分情况下,外部来源的数据不是结构性差就是不完整,这时候就需要你来把这些数据变得更可用!
虽然数据科学家注意到了数据质量的重要性,但这对于商业领导者来说并不是个事。他们更关注如何尽早使用技术来维持竞争优势,而很少理解技术的实际应用。这意味着人们会在“量大出奇迹”的借口下,利用数据集里的一切信息并希望获得最好的结果。由于思维方式的差异,在建模前一个数据科学家一般花费80%时间准备数据集。

为什么是80%时间?因为有缺失值,不平衡的数据,没有任何意义的字段,删除重复数据后的数据,过时数据和其他原因。人们最近才意识到数据的重要性。但是,即使趋势逆转,数据也很难轻易访问和结构良好。一个坏数据集的后果很简单也很符合逻辑:用这些数据集建立的预测模型将会有低准确率和低效率。用不正确的数据训练模型会产生偏差,你的结果将与现实相去甚远。一个糟糕的模型无法被部署,所以对于公司来说开发这样的模型是净损失。
一个用锈铁制造的汽车不能正常驾驶,甚至在最糟糕的情况下,根本不能驾驶…没有人愿意使用或购买一辆生锈的汽车。所以,数据集对于你的项目至关重要。项目在技术和经济层面上的成功取决于你所选择数据的质量。在机器学习项目中,跳过数据评估步骤可能会浪费大量时间,你将不得不从头开始项目。所以现在看来,数据科学家们花那么多时间调查和准备数据集是合乎逻辑的!为了确保我们的数据集是有用的,一个好的实践操作是EDA,即探索性数据分析。EDA是一种熟悉数据集的方法。通过这个反思性工作,可以保证处理的是有趣,连贯和干净的数据。这一步是可视化的而且是基于摘要统计和图形表达。通过EDA,数据科学家可以发现哪一个特征重要或者特征之间的相关性。此外,EDA可以让你发现错误或者缺失值,检测异常值或者驳回一个假设。特征变量的选择之后会被用于机器学习。一般来说,在探索性数据分析之后的步骤是特征工程/数据增强,在这一过程中,你需要把原始数据进行处理,赋予他们额外价值。对于这个例子,我使用了一个非常适合EDA的数据集,即FIFA 19完整的球员数据集。它包含多种数据类型,缺失值,并且有许多适用的指标。对这个数据集的几个完整的分析可以在这里找到。我使用JupyterLab作为IDE,因为它的灵活性和用户友好的界面。
import pandas as pd%time?data?=?pd.read_csv("fifa.csv",?delimiter=',',?index_col=0)

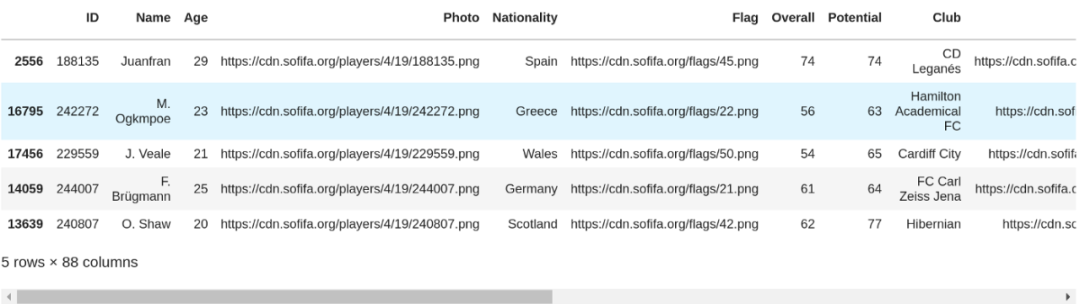
加载速度很快。现在介绍一下data.sample(5),这是一个随机选择行的方法。如果不知道数据是如何排序的,最好使用.sample()而不是.head()。
让我们用.describe()来做一些描述性统计。该方法“总结了数据集分布的集中趋势、分散和形状,不包括NaN值”。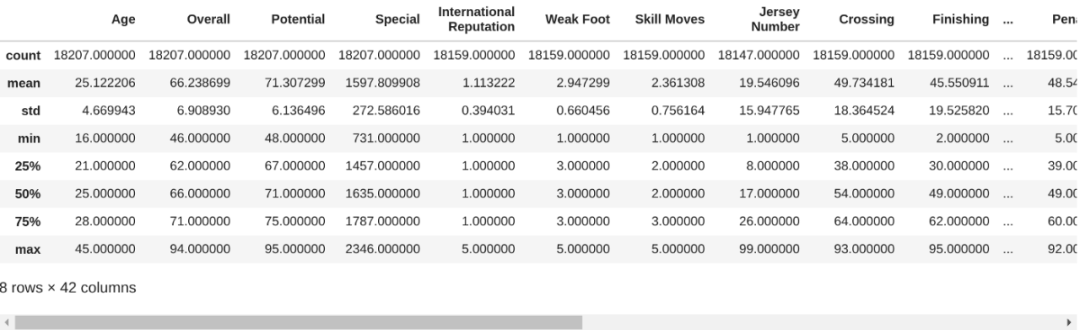
现在我们有了描述性统计数据,我们将会检查缺失数据。我们将会仅仅按顺序列出10个有超10%缺失值的特征:total = data.isnull().sum().sort_values(ascending=False) percent = (data.isnull().sum()/data.isnull().count()).sort_values(ascending=False) missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Missing Percent']) missing_data['Missing Percent'] = missing_data['Missing Percent'].apply(lambda x: x * 100) missing_data.loc[missing_data['Missing Percent'] > 10][:10]
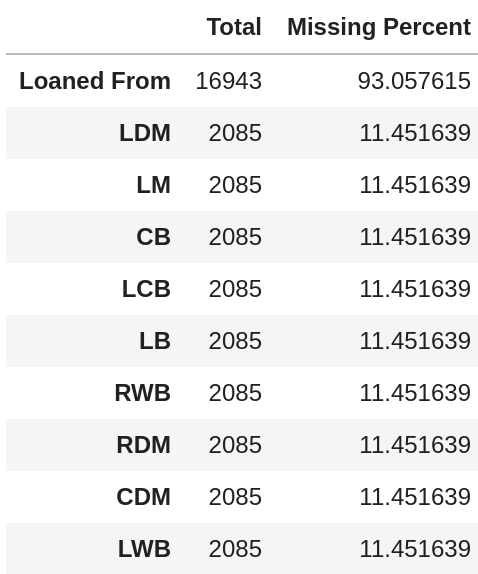
正如你看到的,对于数据科学家来说在notebook上做探索性数据分析是非常方便和高效的。但是,视觉效果仍然很有总结性。让我们一起看看如何用pandas-profiling来更省力地动态展现数据。Github描述:”从pandas Dataframe生成概况报告(profile)“Pandas-profiling将所有东西打包形成一个完整的EDA:最常见值、缺失值、相关性、分位数和描述性统计、数据长度等等。有了这些指标,您将很快看到数据的分布和差异。这些信息至关重要,帮你判断数据将来是否有用。pandas-profiling在HTML报告中以结构化的方式展现了不同指标。得益于它的交互性,我们能够很容易地从一个特征转换到另外一个并且访问其指标。https://miro.medium.com/max/1400/1*48uRp4eMwtQgb4raZRRAtA.gif
pip install pandas-profilingimport pandas as pdimport pandas_profilingdata_fifa = pd.read_csv('fifa.csv')profile = data_fifa.profile_report(title='Pandas Profiling Report')profile.to_file(output_file="fifa_pandas_profiling.html")
在以上的代码中,我们仅仅导入了pandas和pandas-profiling,读取我们的CSV文件并调用profile_report()方法,因为pandas_profiling使用data_fifa.profile_report()来扩展pandas DataFrame。然后,使用.to_file()将ProfileReport对象导出为HTML文件。大功告成!至此,我们的HTML文件位于该文件夹的根目录:
上图展现了报告的“概述”部分。这部分简略描述了变量的类型,缺失值或者是数据集的大小。Pandas-profiling使用matplotlib作为图形库和jinja2作为其接口的模板引擎。作为一个自由职业者,当我必须为客户处理一个新的数据集时,我总是先生成一个pandas profiling,它帮助我吸收数据集的信息。这种做法允许我量化数据集的处理时间。多少特征看起来是正确的?多少包含缺失值?缺失值的百分比是多少?哪些变量互相依赖?另外,此外,该报告还可以作为展示界面,向客户介绍数据健康度的全局情况。无需在你的Jupyter notebook上展示你的分析,当中还夹杂着代码和图表,该报告按照特征整合了各种度量指标,并且有更友好的界面。我的客户喜欢对委派给我的任务有一个完整的跟踪,也希望定期了解我的进展。通常我使用该报告提供数据的健康状态。这一步之后是更深入的数据分析和可视化。
大数据的潜力还在不断增长。充分利用这一优势意味着公司必须把分析和预测系统并入战略视野中,并且用此来做出更好更快的决策。通常来说我们拿到的数据含有错误和缺失值。为了使工作变得有效率,这些数据必须被分析和处理。这就是数据科学家要做的工作。数据科学家用pandas-profiling可以更省力地产出快速的探索性数据分析报告。这份报告清晰且容易使用, 还可以被任何有点统计基础的人看懂。有了对数据的全局理解,您就会有一些思路去进一步分析、处理数据或寻找外部数据源以提高数据质量。我希望您喜欢这个关于pandas-profiling的小介绍!这是我在medium上写的第一篇文章,欢迎评论和改进建议!A better EDA with Pandas-profilinghttps://towardsdatascience.com/a-better-eda-with-pandas-profiling-e842a00e1136译者简介:廖倩颖,马里兰大学公园分校市场分析专业硕士毕业,本科毕业于上海海洋大学包装工程专业。喜欢音乐、电影和看书,我对于数据科学和数据可视化比较有兴趣,最近在学习CV和机器学习算法基础,希望能与各位大佬交流切磋长姿势。「完」
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
数据分析(ID :?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




